

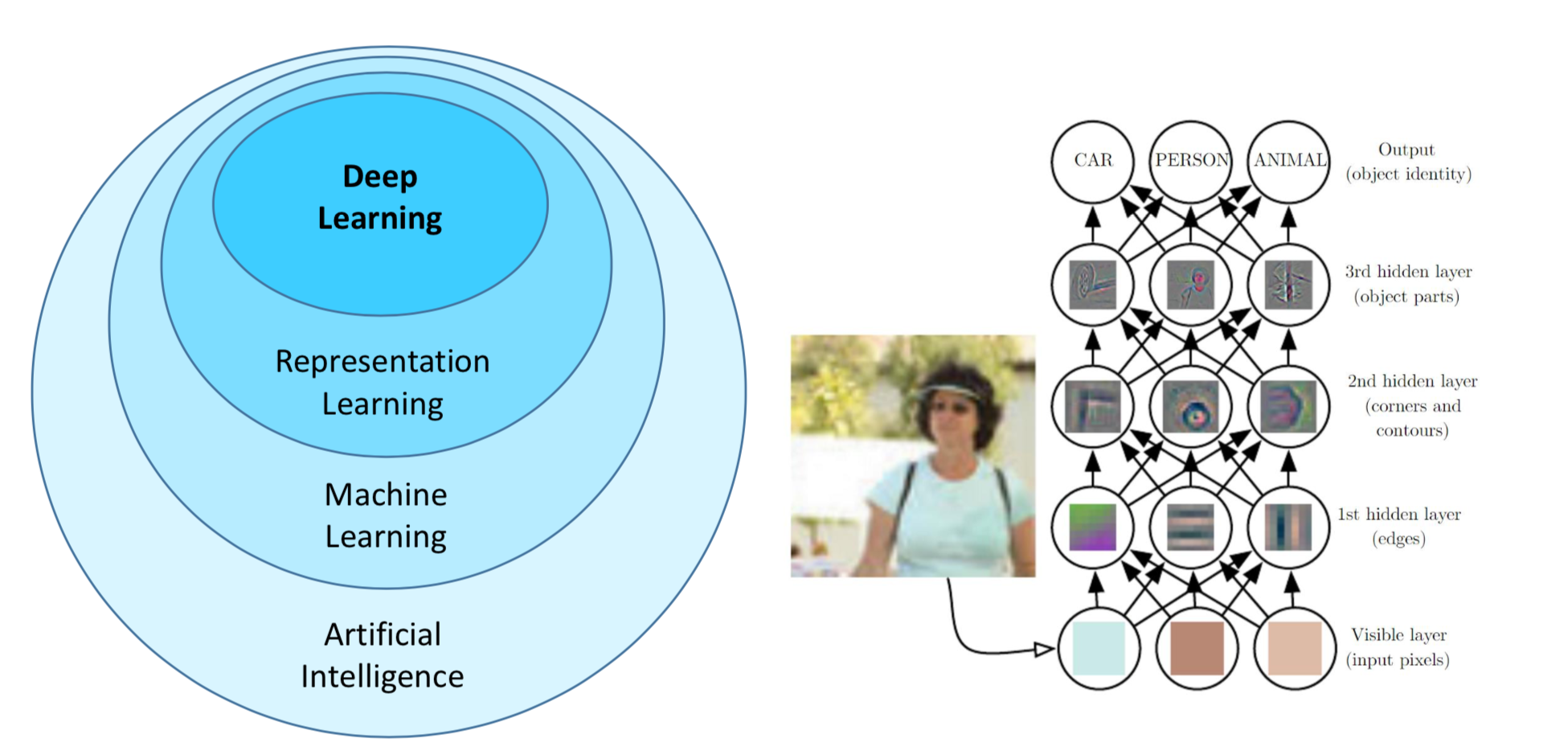
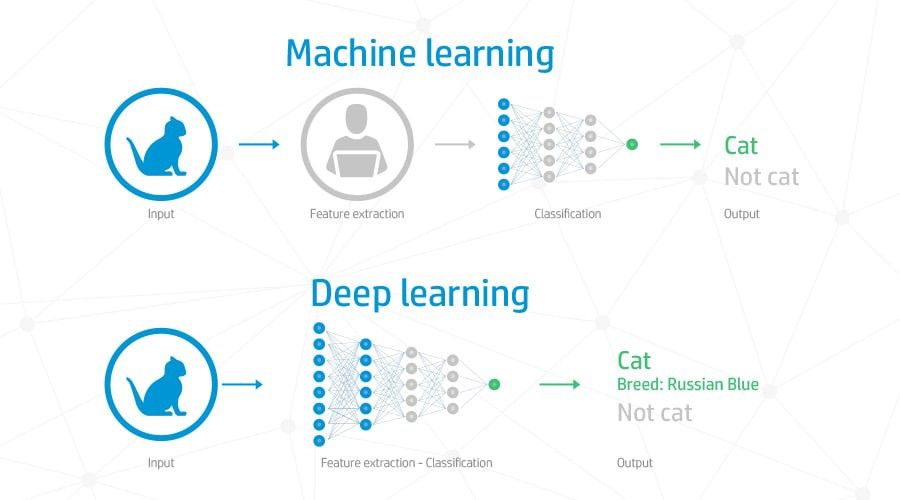
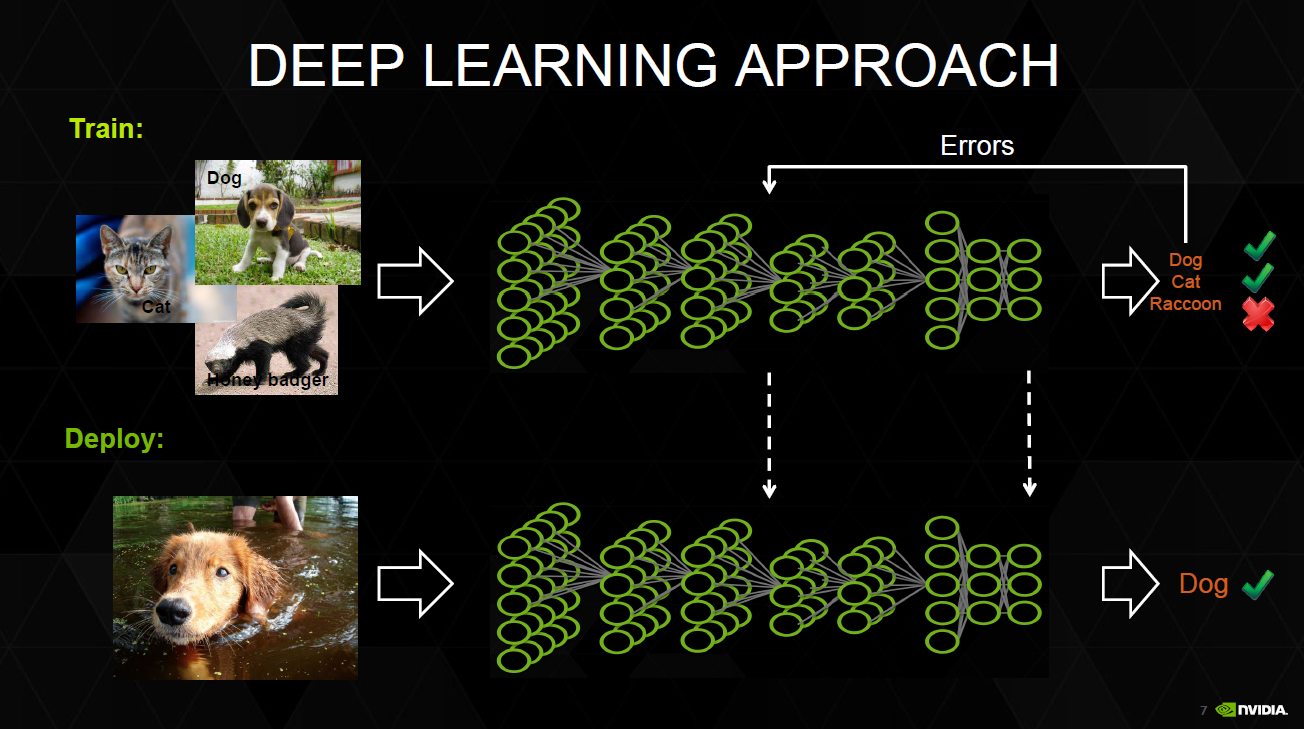
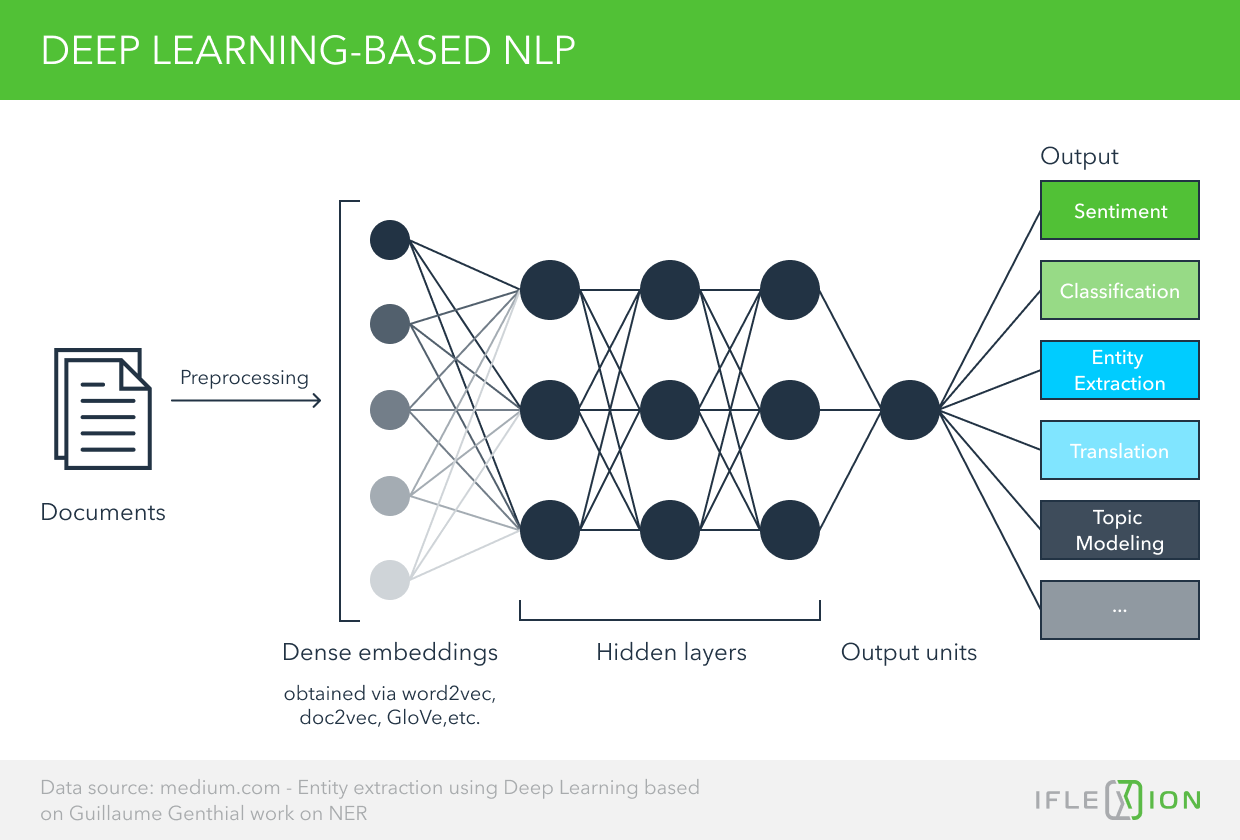
Как справиться с модельными рисками
В банке ВТБ для снижения модельных рисков выстроена целая система внутреннего контроля из трех линий защиты. Так, на первом уровне качеством работы моделей занимаются сами разработчики моделей. На втором — независимое подразделение валидации и управления модельным риском. Оно осуществляет независимую проверку разработанных моделей ИИ. И на третьей линии — отдельное подразделение внутреннего аудита, которое контролирует соблюдение внутренних стандартов сотрудниками на первых двух линиях.
Павел Николаев, управляющий директор департамента интегрированных рисков банка «Открытие», сравнивает набор различных ML-систем в банке с лоскутным одеялом: одновременно работают различные модели, созданные с помощью различных инструментов, разными группами дата-сайентистов. Такое положение дел обусловливает специфический риск: команды могут вмешиваться в данные, нарушая необходимые связи.
Решение – внедрение платформы ML-моделирования корпоративного масштаба IRIS компании Neoflex. По словам Лины Чудновой, руководителя бизнес-направления Fast Data и практики DevOps компании Neoflex, реализована идея Continuous Integration/Continuous Delivery/ Continuous Training моделей на базе общего репозитория моделей и единой платформы для всех бизнес-юнитов банка. Такой подход позволяет платформе интегрироваться со всеми кредитными конвейерами, и в то же время обеспечивается нужный уровень децентрализации работы с моделями – каждая команда дата-сайентистов получает в свое распоряжение свой кусочек общего пространства работы с интеллектуальными моделями, то есть собственную среду с динамическим расширением ресурсов для обучения модели.
Исследовательская компания Mediascope вместе с Neoflex запустила в промышленную эксплуатацию Data Science платформу для разработки и внедрения моделей машинного обучения. Как рассказали в компании, Mediascope получила масштабируемое и управляемое пространство для разработки ML-моделей, которое позволяет оперативно подключать внутренние команды дата-сайентистов с возможностью оценки результатов их работы. Компания также сможет быстро и с минимальными трудозатратами привлекать внешние ML-команды. Всем специалистам доступен централизованный каталог готовых пайплайнов, что даст возможность переиспользовать готовых компонентов.
При этом архитектура платформы обеспечивает автоматизированный процесс разработки и внедрения моделей, их перенос в промышленную среду, а также предоставляет инструменты для визуализации метрик экспериментов. Платформа построена на базе СПО Kubeflow, которое обеспечивает централизованные средства разработки ML-моделей, пайплайнов и управления артефактами. Используется также Argo Workflow — развитый оркестратор рабочих процессов на Kubernetes, который входит в состав Kubeflow, — он облегчает процесс использования разработанных моделей.
В ВТБ правильность работы моделей ИИ помогает отслеживать специальная автоматизированная система мониторинга моделей: внутренний учет разработанных моделей ведется в системе управления моделями, а правила и процесс взаимодействия подразделений регламентируются утвержденным стандартном жизненного цикла моделей.
Высокий уровень потребления вычислительных ресурсов решениями на базе ML-моделей неминуемо приводит к идее облачных сервисов. Так, решение для быстрого процессинга ML-моделей компании Neoflex одинаково легко может быть развернуто, как на локальной инфраструктуре банка, так и в облаке: AWS, Yandex Cloud, Mail Cloud Solutions.
Свое суперкомпьютерное облако открыли для всех разработчиков Сбербанк и SberCloud: облачная платформа ML Space на базе вычислительных мощностей суперкомпьютера «Кристофари» с более чем тысячей GPU предназначена для разработчиков ИИ-сервисов любого масштаба. Платформа ML Space ориентирована на полный цикл разработки прикладных решений на базе машинного обучения и совместной работы команд специалистов по данным над созданием и развертыванием моделей машинного обучения. Архитектура ML Space сформирована из интегрированных модулей-сервисов, каждый из которых рассчитан на решение определенных задач: хранение, анализ, управление доступом и жизненным циклом данных, датасетов, моделей, Docker-контейнеров и другое.
Что такое синапс?
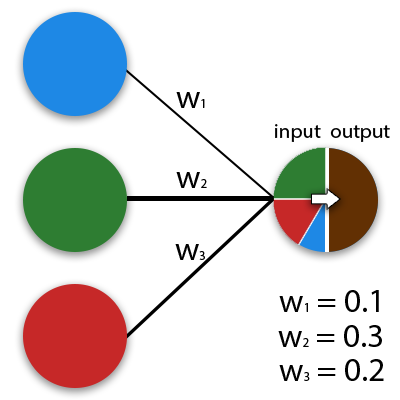
Синапс это связь между двумя нейронами. У синапсов есть 1 параметр — вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов. У того нейрона, у которого вес будет больше, та информация и будет доминирующей в следующем нейроне (пример — смешение цветов). На самом деле, совокупность весов нейронной сети или матрица весов — это своеобразный всей системы. Именно благодаря этим весам, входная информация обрабатывается и превращается в результат.
Важно помнить, что во время инициализации нейронной сети, веса расставляются в случайном порядке
2 Базовая структура ДНН
Нейронные сети являются продолжением персептронов, а DNN можно понимать как нейронные сети со многими скрытыми уровнями. Многослойные нейронные сети и глубокие нейронные сети DNN на самом деле вещь. DNN иногда называют Multi-Layer Perceptron (MLP).
Разделенные по положению разных слоев от DNN, слои нейронной сети внутри DNN можно разделить на три категории: входной слой, скрытый слой и выходной слой. , И количество слоев в середине все скрытые слои.
Слои полностью связаны, то есть любой нейрон в i-м слое должен быть связан с любым нейроном в i + 1-м слое. Хотя DNN выглядит очень сложным, он все же такой же, как персептрон в небольшой локальной модели, то есть линейная зависимость.Плюс функция активации 。
Поскольку существует много слоев DNN, число наших коэффициентов линейной зависимости w и смещения b также много. Как конкретные параметры определены в DNN?
Сначала взглянем на определение коэффициента линейной зависимости w.На следующем рисунке в качестве примера показан трехслойный DNN. Линейная зависимость между четвертым нейроном во втором слое и вторым нейроном в третьем слое определяется какВерхний индекс 3 представляет количество слоев, в которых находится линейный коэффициент w, а нижний индекс соответствует выходному индексу третьего уровня 2 и входному индексу второго уровня 4. Вы можете спросить, почему это не такКак насчет? Это главным образом для облегчения модели для операций матричного представления.Каждый раз, когда выполняется матричная операция,Это должно быть транспонировано
Если выходной индекс размещен впереди, линейная операция не нуждается в транспонировании, то есть непосредственно, Линейный коэффициент k-го нейрона в l-1-м слое к j-му нейрону в l-м слое определяется как, Обратите внимание, что входной слой не имеет параметра w
Посмотрите на определение смещения б снова.На примере этого трехслойного DNN смещение, соответствующее третьему нейрону во втором слое, определяется какСреди них верхний индекс 2 представляет количество слоев, а нижний индекс 3 представляет индекс нейрона, в котором находится смещение. По той же причине смещение первого нейрона в третьем слое должно быть выражено какВ выходном слое нет параметра смещения.
Где можно получить образование по нейронным сетям?
GeekUniversity совместно с Mail.ru Group открыли первый в России факультет Искусственного интеллекта преподающий нейронные сети.





Для учебы достаточно школьных знаний. У вас будут все необходимые ресурсы и инструменты + целая программа по высшей математике. Не абстрактная, как в обычных вузах, а построенная на практике. Обучение познакомит вас с технологиями машинного обучения и нейронными сетями, научит решать настоящие бизнес-задачи.
После учебы вы сможете работать по специальностям:
- Искусственный интеллект,
- Машинное обучение,
- Нейронные сети,
- Анализ больших данных.
Особенности обучения в GeekUniversity
Через полтора года практического обучения вы освоите современные технологии Data Science и приобретете компетенции, необходимые для работы в крупной IT-компании. Получите диплом о профессиональной переподготовке и сертификат.
Обучение проводится на основании государственной лицензии № 040485. По результатам успешного завершения обучения выдаем выпускникам диплом о профессиональной переподготовке и электронный сертификат на портале GeekBrains и Mail.ru Group.
Проектно-ориентированное обучение
Обучение происходит на практике, программы разрабатываются совместно со специалистами из компаний-лидеров рынка. Вы решите четыре проектные задачи по работе с данными и примените полученные навыки на практике. Полтора года обучения в GeekUniversity = полтора года реального опыта работы с большими данными для вашего резюме.
Наставник
В течение всего обучения у вас будет личный помощник-куратор. С ним вы сможете быстро разобраться со всеми проблемами, на которые в ином случае ушли бы недели. Работа с наставником удваивает скорость и качество обучения.
Основательная математическая подготовка
Профессионализм в Data Science — это на 50% умение строить математические модели и еще на 50% — работать с данными. GeekUniversity прокачает ваши знания в матанализе, которые обязательно проверят на собеседовании в любой серьезной компании.
GeekUniversity дает полтора года опыта работы для вашего резюме
В результате для вас откроется в 5 раз больше вакансий:
Для тех у кого нет опыта в программировании, предлагается начать с подготовительных курсов. Они позволят получить базовые знания для комфортного обучения по основной программе.
The following two tabs change content below.
Mining-Cryptocurrency.ru
Материал подготовлен редакцией сайта «Майнинг Криптовалюты», в составе: Главный редактор — Антон Сизов, Журналисты — Игорь Лосев, Виталий Воронов, Дмитрий Марков, Елена Карпина. Мы предоставляем самую актуальную информацию о рынке криптовалют, майнинге и технологии блокчейн.
Отказ от ответственности: все материалы на сайте Mining-Cryptocurrency.ru имеют исключительно информативные цели и не являются торговой рекомендацией или публичной офертой к покупке каких-либо криптовалют или осуществлению любых иных инвестиций и финансовых операций.
Новости Mining-Cryptocurrency.ru
- Binance Earn — как получать пассивный доход от хранения криптовалюты на бирже Binance? — 01.07.2023
- Что такое стейкинг и как получать пассивный доход от криптовалют? — 26.12.2022
- Конфискация криптовалюты в России: как работает механизм изъятия криптоактивов? — 26.12.2022
- Как минимизировать риски при торговле фьючерсами на Binance Futures? — 26.12.2022
Какую роль играет национальный доход НД в экономике?
Национальный доход играет ключевую роль в экономике, так как он влияет на многие аспекты жизни государства и его граждан. Вот несколько основных ролей, которые НД играет в экономике:
- Измерение экономической активности: Национальный доход позволяет оценить размер экономики и ее динамику. Он является основным индикатором для измерения экономической активности страны.
- Оценка уровня жизни: НД позволяет судить о достаточности доходов населения и качестве жизни граждан. Чем выше НД, тем выше уровень жизни и благосостояние населения.
- Планирование экономической политики: НД является важным инструментом для планирования экономической политики государства. Он помогает определить приоритеты и направление развития экономики.
- Распределение доходов: НД позволяет определить, как доходы распределяются между различными секторами экономики и населением. Он помогает выявить проблемы неравенства и разрешить их.
- Оценка эффективности государственных программ: НД позволяет оценить результаты государственных программ и мер, принятых для стимулирования экономического роста и благосостояния населения. Он помогает определить, какие программы эффективны, а какие нуждаются в корректировке или отмене.
Таким образом, национальный доход играет важную роль в экономической жизни страны. Он служит не только индикатором экономической активности и уровня жизни, но и инструментом для планирования и анализа экономической политики.
Beginning of first AI winter#
Researchers strongy believed that perceptrons can and will solve hard problems. In 1966 Marvin Minskey together with Seymour Papert as a summer project for his students gave a task to solve computer vision. Task was to split image into regions of likely objects and background areas and perform object classification. It turned out to be much harder than they anticipated. We will soon construct object classifier, if you are interested in background detection read about U-Net.
In their 1969 monograph Perceptrons, Marvin Minsky and Seymour Papert (same guys after 3 years) highlighted a number of serious weaknesses of Perceptrons—in particular, the fact that they are incapable of solving some trivial problems (e.g., the Exclusive OR (XOR) classification problem.
It turns out that some of the limitations of Perceptrons can be eliminated by stacking multiple Perceptrons (or using ADA activation)!
But, we have no idea how to train those stacked Perceptorns (DNN — deep neural nets). And also there are no big enough datasets or resources to try this out…
Said at the end
At this point, you should roughly understand the following things:
- What is machine learning
- What is a deep neural network
- What is the model
- What is the input layer, the output layer, what are the meanings of the classification applications in the example above, and what is the shape of the layer?
- What is training and what is its function
- What are the data training set, validation set, and test set, where are they used, and what needs to be paid attention to
- What is the standard to measure the quality of the model
If you still don’t understand, you can understand it again carefully, or refer to related materials. If you find a better way to explain it, please follow the document contribution method in the left directory to participate in the contribution.
Основные принципы работы ДНН
Искусственные нейроны
Одна из основных идей ДНН — использование искусственных нейронов, которые функционально аналогичны нейронам в мозге. Искусственные нейроны принимают входные данные, вычисляют определенную функцию активации и передают сигнал следующему нейрону.
Прямое распространение
Основная идея работы ДНН — прямое распространение. Это означает, что данные перемещаются от входного слоя через скрытые слои и, наконец, к выходному слою. Как метафора, можно сказать, что это как поток данных, движущихся через нейроны.
В процессе прямого распространения каждый искусственный нейрон получает входные данные и вычисляет выходную активацию с помощью функции активации.
Обучение с учителем и обратное распространение ошибки
ДНН могут быть обучены с учителем, используя метод обратного распространения ошибки. Этот метод основан на простой идее: сравнить выходные данные с ожидаемыми результатами и использовать полученную ошибку для обновления весов нейронов.







Обратное распространение ошибки работает путем вычисления градиента функции потерь относительно весов и дальнейшего обновления весов нейронов, чтобы уменьшить ошибку. Таким образом, нейронная сеть постепенно корректирует свои предсказания, чтобы быть более точной.
Использование больших объемов данных
ДНН обладают огромным потенциалом, но для их эффективной работы требуются большие объемы данных. Чем больше данных доступно для обучения, тем лучше нейронная сеть может изучить закономерности и делать точные прогнозы.
Поэтому важно иметь доступ к качественным, разнообразным и достаточному количеству данных для обучения ДНН. Благодаря этому нейронные сети могут улучшить точность предсказаний и предложить новые решения в различных областях: от анализа данных и обработки изображений до распознавания речи и автоматизации процессов
Таким образом, основные принципы работы ДНН включают использование искусственных нейронов, прямое распространение данных, обучение с учителем и обратное распространение ошибки, а также использование больших объемов данных для обучения. Эти принципы делают ДНН мощным инструментом для решения сложных задач и прогнозирования будущих событий.
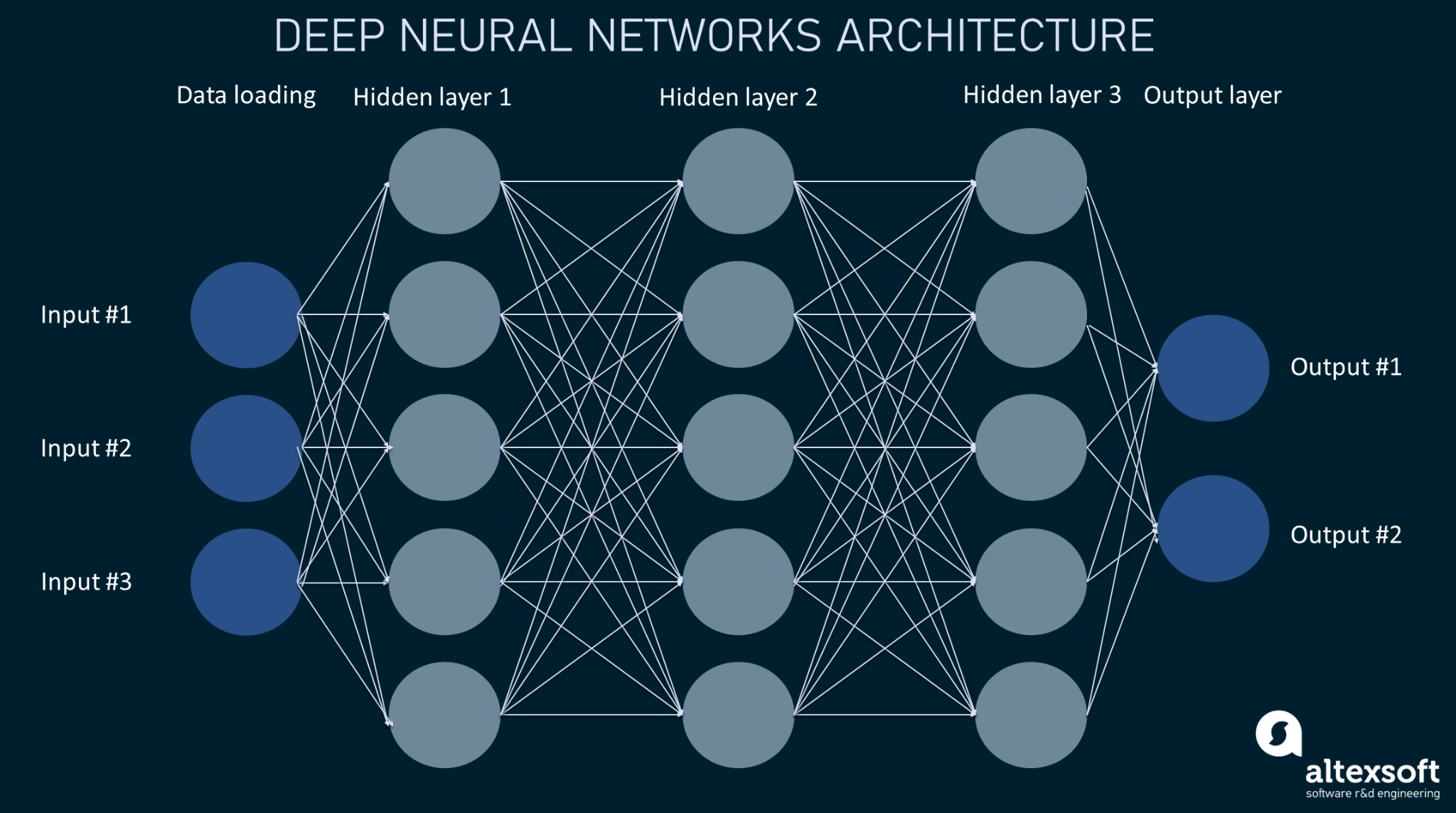
Виды нейросетей
Есть разные виды нейронных сетей, каждый из которых используется для определенных целей. Вот самые популярные из них.
Перцептрон
Модель перцептрона — пример самой простой архитектуры нейронной сети. Эту модель придумал Фрэнк Розенблатт в 1958 году. Перцептрон — это математическая модель восприятия информации мозгом.
Сейчас модель перцептрона в чистом виде практически не используется в мире нейронных сетей. Но на ее основе сделали искусственный нейрон, который является минимальным «кирпичиком» для многих других нейронных сетей.
Модель перцептрона состоит из четырех основных компонентов: входа, веса, сумматора и функции активации. Входные данные перемножаются с весами, суммируются и поступают на вход функции активации. Таким образом формируется результат работы перцептрона.
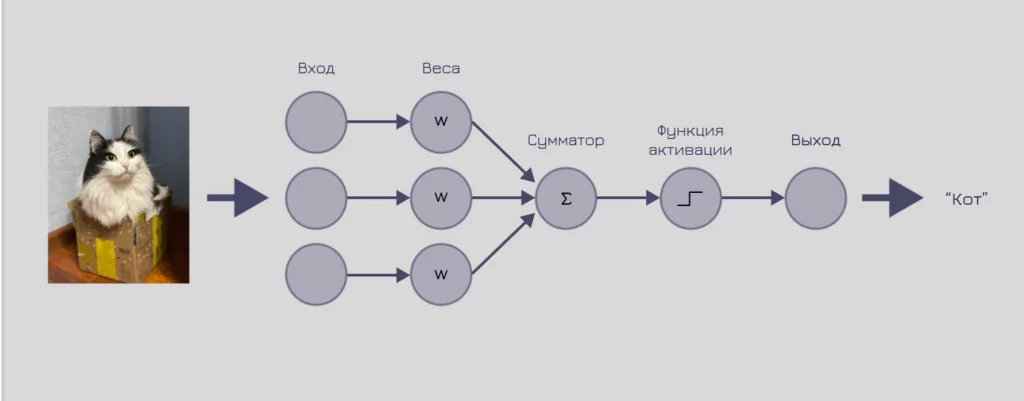
Концепция работы перцептрона на примере распознавания объекта
Многослойные нейронные сети
Многослойная нейронная сеть — одна из самых базовых архитектур. Она состоит из искусственных нейронов, которые объединяются в слои. Нейрон из одного слоя связан с каждым нейроном из следующего слоя, поэтому такие нейронные сети часто называют полносвязными.
Чаще всего их используют для обработки числовых данных или в составе других нейронных сетей.
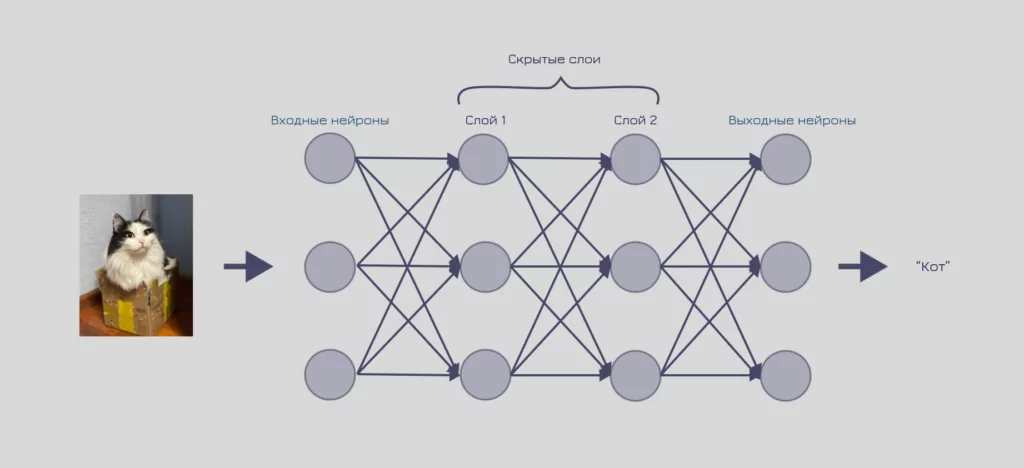
Визуализация работы многослойной нейронной сети
Свёрточные нейронные сети
Еще один вид популярных нейросетей — свёрточная нейронная сеть. Идея создания такой архитектуры тоже во многом заимствована из исследований по работе зрительной коры головного мозга. Неслучайно область, где свёрточные нейронные сети нашли применение, — это обработка изображений.
Основной принцип работы — переиспользование части нейронной сети внутри самой себя для обработки небольших участков входного изображения.
Другими словами, каждый слой такой архитектуры «смотрит» на фиксированный кусочек входа и извлекает из него информацию. Далее из этой информации строится новое «изображение», которое подается на вход следующего слоя.
Такие нейронные сети очень эффективны в распознавании простых элементов (паттернов): нос, глаз, ухо и так далее.
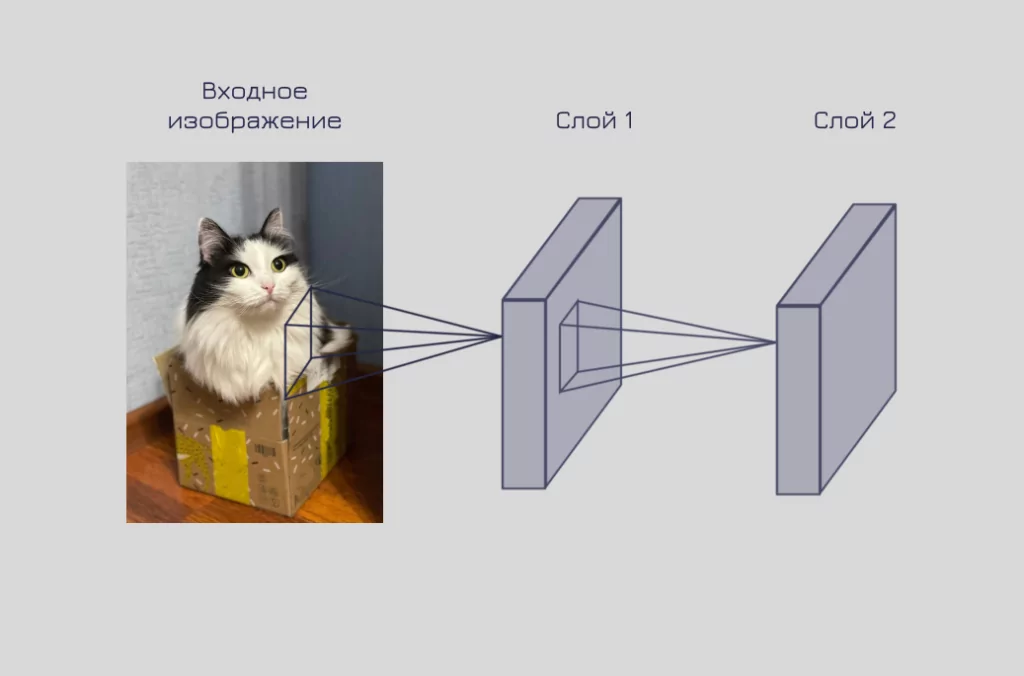
Визуализация работы свёрточных слоев нейронной сети
Рекуррентные нейронные сети
Для обработки последовательностей чаще всего используют рекуррентные нейронные сети. Основная особенность данной архитектуры — использование памяти. Нейронная сеть хранит внутри себя информацию о предыдущих данных и выдает ответ с учетом знания о всей последовательности.
Такая архитектура мотивирована исследованиями принципов работы памяти в головном мозге. Эти нейронные сети высоко зарекомендовали себя в задачах обработки текста, видео, аудио и других данных, зависимых от времени.
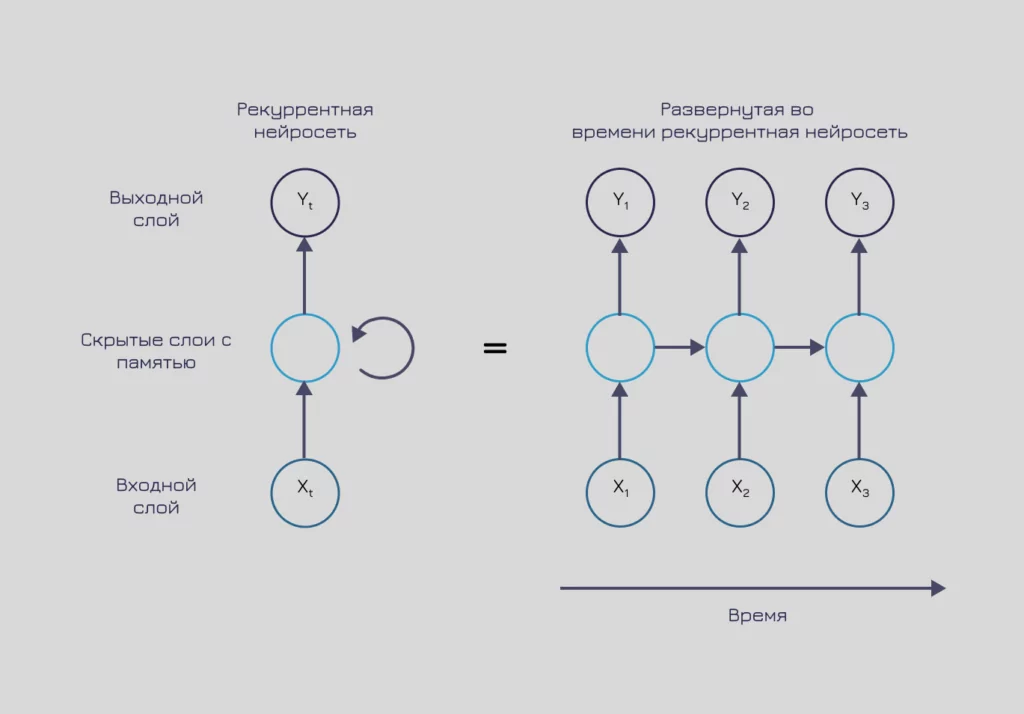
Визуализация работы рекуррентных слоев нейронной сети
Принципы расчета национального дохода НД
Принцип общественного производства. Расчет НД основывается на общественном производстве, то есть на деятельности всех секторов экономики. Включаются все виды производства — производственная, сельскохозяйственная, услуги и т.д. Этот принцип позволяет получить полную картину экономической активности государства.




Принцип рыночных цен. Расчет НД основывается на рыночных ценах товаров и услуг. Рыночная цена учитывает спрос и предложение на товары и является объективным показателем их стоимости. Использование рыночных цен позволяет учесть реальное значение товаров и услуг в экономике.
Принцип валового внутреннего продукта (ВВП). Расчет НД осуществляется на основе валового внутреннего продукта. ВВП представляет собой объем производства государством за определенный период времени, за вычетом стоимости промежуточных товаров и услуг. Использование ВВП позволяет оценить экономическую активность страны.
Принцип учета доходов и расходов. Расчет НД учитывает доходы и расходы государства, предприятий и организаций, а также доходы и расходы населения. Это позволяет оценить вклад различных субъектов экономики в формирование общего дохода.
Принцип двойного счета. Расчет НД осуществляется с использованием двойной системы счетов. Это означает, что в процессе расчета учитываются и доходы, и расходы, чтобы получить более полную и точную картину национального дохода.
Эти принципы позволяют определить национальный доход страны и его составляющие. Регулярный расчет НД и анализ его изменений позволяют подтвердить или опровергнуть предположения о состоянии экономики и принять меры для ее развития.
What does a neural network consist of?
A typical neural network has anything from a few dozen to hundreds, thousands, or even millions of artificial neurons called
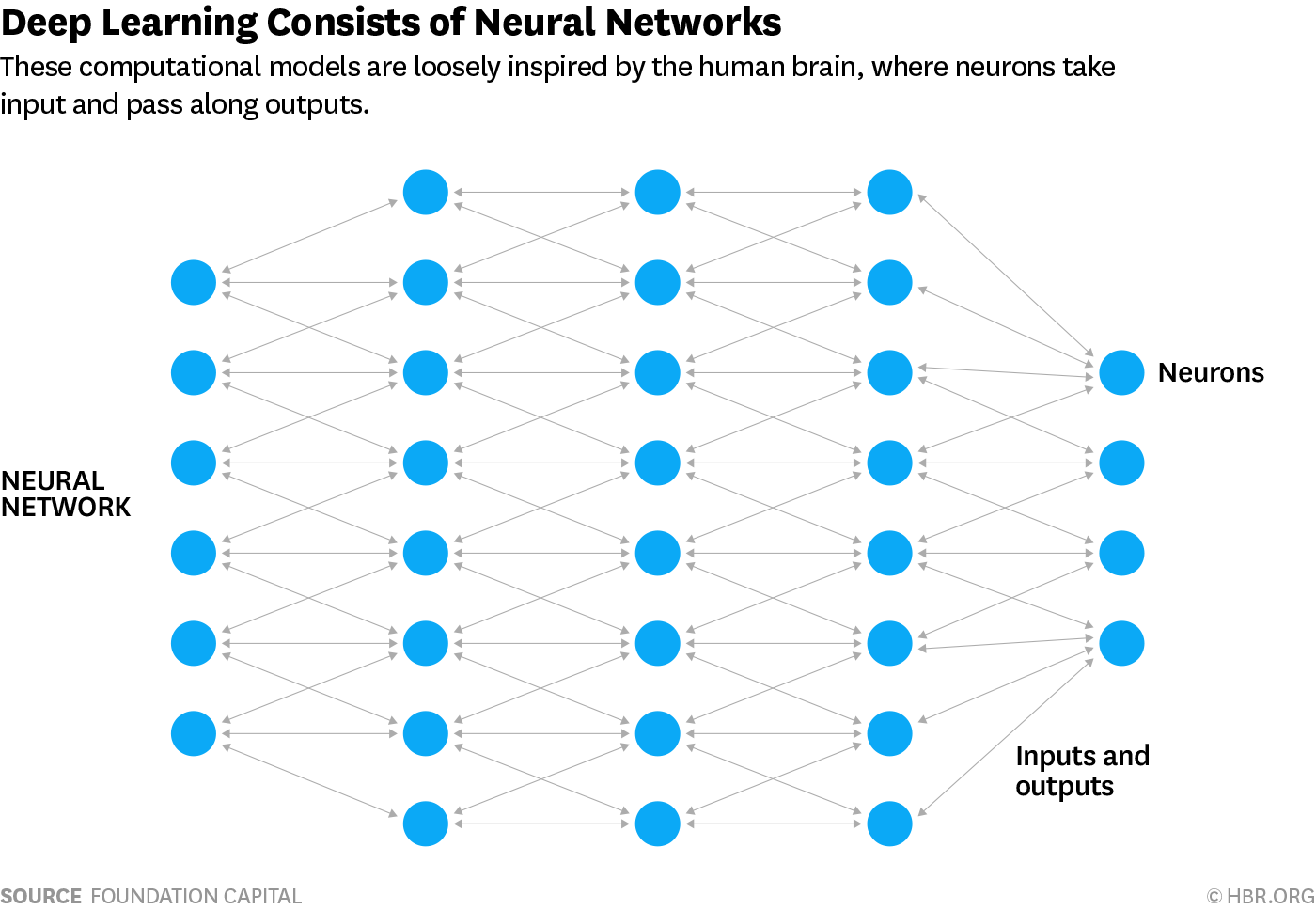
units arranged in a series of layers, each of which connects to the layers on either side. Some of them, known as input units, are designed to receive various forms of information from the outside world that the network will attempt to learn about, recognize, or otherwise process. Other units sit on the opposite side of the network and signal how it responds to the information it’s learned; those are known as output units. In between the input units and output units are one or more layers of hidden units, which, together, form the majority of the artificial brain. Most neural networks are fully connected, which means each hidden unit and each output unit is connected to every unit in the layers either side. The connections between one unit and another are represented by a number called a weight, which can be either positive (if one unit excites another) or negative (if one unit suppresses or inhibits another). The higher the weight, the more influence one unit has on another. (This corresponds to the way actual brain cells trigger one another across tiny gaps called synapses.)
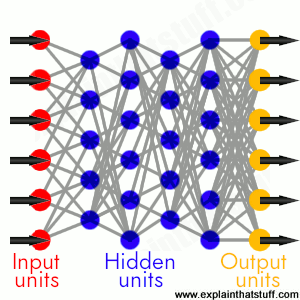
Photo: A fully connected neural network is made up of input units (red), hidden units (blue), and output units (yellow), with all the units connected to all the units in the layers either side. Inputs are fed in from the left, activate the hidden units in the middle, and make outputs feed out from the right. The strength (weight) of the connection between any two units is gradually adjusted as the network learns.
Deep neural networks
Although a simple neural network for simple problem solving could consist of just three layers, as illustrated here, it could also consist of many different layers between the input and the output. A richer structure like this is called a deep neural network (DNN), and it’s typically used for tackling much more complex problems. In theory, a DNN can map any kind of input to any kind of output, but the drawback is that it needs considerably more training: it needs to «see» millions or billions of examples compared to perhaps the hundreds or thousands that a simpler network might need. Deep or «shallow,» however it’s structured and however we choose to illustrate it on the page, it’s worth reminding ourselves, once again, that a neural network is not actually a brain or anything brain like. Ultimately, it’s a bunch of clever math… a load of equations… an algorithm, if you prefer.
Other types of neural networks
Most neural networks are designed upfront to solve a particular problem. So they’re designed, built, and trained on masses of data, and then they spend the rest of their days processing
similar data, and churning out solutions to essentially the same problem, over and over again. But human brains don’t really work that way: we’re much more adaptable to the ever-changing world around us. Liquid neural networks (LNN) are ones that replicate this adaptibility, to an extent, by modifying their algorithms and equations to suit their environments.