

Почему и зачем использовать веб-парсинг?
Необработанные данные можно использовать в различных областях. Давайте посмотрим на использование веб-скрапинга:
Динамический мониторинг цен
Исследования рынка
Web Scrapping идеально подходит для анализа рыночных тенденций. Это понимание конкретного рынка. Крупной организации требуется большой объем данных, и сбор данных обеспечивает данные с гарантированным уровнем надежности и точности.
Сбор электронной почты
Многие компании используют личные данные электронной почты для электронного маркетинга. Они могут ориентироваться на конкретную аудиторию для своего маркетинга.
Новости и мониторинг контента
Один новостной цикл может создать выдающийся эффект или создать реальную угрозу для вашего бизнеса. Если ваша компания зависит от анализа новостей организации, он часто появляется в новостях. Таким образом, парсинг веб-страниц обеспечивает оптимальное решение для мониторинга и анализа наиболее важных историй. Новостные статьи и платформа социальных сетей могут напрямую влиять на фондовый рынок.
Web Scrapping играет важную роль в извлечении данных с веб-сайтов социальных сетей, таких как Twitter, Facebook и Instagram, для поиска актуальных тем.
Исследования и разработки
Большой набор данных, таких как общая информация, статистика и температура, удаляется с веб-сайтов, который анализируется и используется для проведения опросов или исследований и разработок.
Предустановки
Прежде чем написать первую строчку кода, необходимо выполнить перечисленные ниже условия:
- Java >= 8: подойдет любая версия Java, начиная с 8-й. Рекомендуем загрузить и установить версию Java LTS (Long Term Support). В частности, данный учебник основан на Java 17. На момент написания статьи Java 17 является последней LTS-версией Java.
-
Maven или Gradle: вы можете выбрать любой инструмент автоматизации сборки Java-проектов, который вам больше нравится. В частности, Maven или Gradle понадобятся для управления зависимостями.
-
Продвинутая IDE с поддержкой Java: подойдет любая IDE, поддерживающая Java с Maven или Gradle. В данном руководстве используется IntelliJ IDEA, которая, вероятно, является лучшей из существующих Java IDE.
По указанным выше ссылкам можно выполнить все необходимые предустановки. По порядку загрузите Java, Maven или Gradle, а также IDE для Java. Следуйте официальным руководствам по установке, чтобы избежать распространенных проблем и неполадок.
Теперь проверим успешность выполненных предустановок.
Убедитесь, что Java настроена правильно
Откройте терминал. Убедитесь в том, что вы установили и правильно добавили Java в PATH. Это можно сделать помощью следующей команды:
В результате выполнения этой команды должно быть выведено что-то вроде этого:
Убедитесь, что установлен Maven или Gradle
Если вы выбрали Maven, выполните в терминале следующую команду:
Вы должны получить информацию о версии Maven, которую настроили, следующим образом:
Если же вы выбрали Gradle, то выполните в терминале эту команду:
Аналогичным образом необходимо получить информацию о версии установленного Gradle, как показано ниже:
Теперь вы готовы к тому, чтобы узнать, как выполнять веб-скрапинг с помощью Jsoup на языке Java!
Создание или покупка инструмента для парсинга данных
Как вы уже понимаете, эффективность парсинга данных зависит от используемого парсера. Поэтому вполне логично задаться вопросом, что лучше –позволить вашей технической команде создать парсер данных или воспользоваться коммерческим решением, таким как Bright Data.
Создание собственного парсера – более гибкий подход, но он требует больше времени, чем покупка, которая дает вам меньше контроля над ним. Очевидно, что вопрос более сложный, чем кажется. Итак, давайте попробуем разобраться, что для вас лучше – создать или купить парсер данных.
Создание парсера данных
В этом случае у вашей компании есть внутренняя группа разработчиков, которая может создать собственный парсер с нуля.
Плюсы
- Вы можете адаптировать его к вашим конкретным потребностям.
- Вы владеете кодом парсера и контролируете процесс его разработки.
-
При частом использовании в долгосрочной перспективе это может быть дешевле, чем платить за готовый продукт.
Минусы
-
Нельзя игнорировать стоимость разработки, управления ПО и хостингом сервера.
-
Вашей команде разработчиков придется потратить много времени на его проектирование, разработку и поддержку.
-
Могут возникнуть проблемы с производительностью, особенно если бюджет на мощный сервер ограничен.
Создание парсера с нуля всегда имеет свои преимущества, особенно если он должен соответствовать особенно сложным или специфическим требованиям. В то же время это требует много времени и ресурсов. Таким образом, вы можете не позволить себе это по бюджету или просто не захотите, чтобы ваша команда тратила время на создание такого инструмента.
Покупка парсера данных
В этом случае вы покупаете коммерческое решение, предлагающее нужные вам возможности парсинга данных. Обычно это предполагает оплату лицензии на ПО или небольшую плату за каждый вызов API.
Плюсы
- Ваша команда разработчиков не тратит время и ресурсы на его создание.
- Стоимость определена с самого начала и нет никаких «сюрпризов».
-
Об обновлении и обслуживании инструмента заботится поставщик, а не ваша команда.
Минусы
- Инструмент может не соответствовать вашим будущим потребностям.
- У вас нет контроля над парсером.
- Вы можете в конечном итоге потратить больше денег, чем на его создание.
Купить инструмент для парсинга можно быстро и легко. Всего несколько кликов, и вы можете начать парсинг данных. Однако если вы выберете недостаточно продвинутый инструмент, он может быстро дать сбой и не соответствовать вашим будущим запросам.
Как найти статьи конкурентов для последующего парсинга
Как мы уже разобрались выше, парсинг относится к процессу извлечения и анализа данных из различных источников, включая веб-страницы. Поскольку мы ищем способы отбора статей конкурентов для последующего парсинга, есть несколько подходов, которые можно использовать.
Во-первых, мы можем вручную собирать информацию о статьях наших конкурентов, обращая внимание на их статьи на веб-сайтах, социальные сети, блоги и другие платформы. Это позволит нам выбирать наиболее интересные и релевантные статьи для последующего парсинга
Во-вторых, мы можем воспользоваться различными инструментами и программами, которые автоматически собирают информацию о статьях конкурентов. Некоторые из них имеют встроенные алгоритмы для отбора наиболее релевантной информации.
Если рассмотреть вопрос шире, то вот несколько способов, которые можно использовать для сбора статей конкурентов:
Поиск поисковыми системами: Используйте поисковые запросы, связанные с вашей нишей и конкурентами, чтобы найти статьи, опубликованные Вашими конкурентами. Просмотрите результаты поиска и сохраните интересующие Вас статьи для последующего парсинга.
Использование специальных инструментов: Существуют инструменты, такие как Ahrefs, SEMrush, Moz и другие, которые помогают отслеживать контент конкурентов и предоставляют данные о их публикациях. Используйте такие инструменты, чтобы найти интересующие Вас статьи.
Подписка на рассылки: Если у Ваших конкурентов есть рассылки или блоги, подпишитесь на них. Это поможет Вам получать статьи и обновления напрямую на Вашу почту.










Мониторинг форумов и сообществ: Если Ваша ниша активна в форумах или сообществах, вступите в них и следите за обсуждениями. Здесь можно найти ссылки на полезные статьи и идеи.
Мониторинг новостных сайтов: Узнайте, какие новостные сайты отслеживают события и развитие в Вашей нише. Просмотрите разделы, связанные с вашими конкурентами, и сохраните статьи, которые Вам интересны.
Использование агрегаторов контента: Существуют платформы, такие как Feedly или Flipboard, которые могут помочь Вам собрать и организовать контент из разных источников. Подпишитесь на блоги и публикации Ваших конкурентов, чтобы получать их статьи на одной платформе.
Анализ исходного кода веб-страниц: Иногда в исходном коде веб-страницы можно найти ссылки на связанный контент или прямо на статьи конкурентов. Просмотрите HTML-код страницы и ищите подобные ссылки.
Использование специализированных инструментов для сбора контента: Существуют инструменты, разработанные специально для сбора статей и контента из определенных источников. Используйте такие инструменты для сбора статей Ваших конкурентов с их веб-сайтов.
Использование аналитических инструментов социальных медиа: Иногда социальные медиа платформы предоставляют аналитические инструменты, с помощью которых вы можете изучить активности Ваших конкурентов и найти их статьи. Узнайте, какие инструменты предоставляются в социальных медиа, которые вы используете, и воспользуйтесь ими для поиска контента.
Просмотр вебинаров и онлайн-мероприятий: Многие конкуренты проводят вебинары, онлайн-семинары и мероприятия, на которых представляют свои исследования и статьи. Участвуйте в таких мероприятиях или просматривайте их записи, чтобы получить доступ к полезному контенту.
Использование платформ для обмена контентом: Существуют платформы, на которых писатели и эксперты делятся своими статьями и материалами. Просматривайте соответствующие категории, указывайте интересующую Вас тему и собирайте полезные статьи относительно Ваших конкурентов.
Подписка на блоги и видеоканалы конкурентов: Оставайтесь в курсе последних материалов и контента, публикуемых Вашими конкурентами. Подпишитесь на их блоги, YouTube-каналы и другие платформы для получения уведомлений о новых публикациях.Когда Вы соберете статьи конкурентов, Вы можете применять парсинг для анализа их контента и получения полезной информации. И для этой задачи идеально подходит программа X-Parser. С ее помощью Вы очень легко и просто сможете спарсить найденные и отобранные статьи конкурентов.
How to create a web scraper with Java?
To create a complete web scraper, you should consider covering a group of the following features:
- data extraction (retrieve required data from the website)
- data parsing (pick only the required information)
- data storing/presenting
Let’s create a simple Java web scraper, which will get the title text from the site example.com to observe how to cover each aspect on practice:
Each of the steps described above is called separately from the function:
Getting data from the server
Our scraper data retrieving part is performed by the function :
library (we’ll review it a bit later) provides us the ability to make an HTTP call to get the information from the web server that hosts content.
After receiving the response (using ), we can get the response body containing the page’s HTML.
Extracting data from the HTML
The HTML content is full of HTML/CSS information, which is not what we’re targetting to get, so we need to extract exact text data (in our example, it is a page’s title).
To get this job done, we’re using RegExp (regular expression). It’s not the most effortless way of text data extraction, as some developers might not be too familiar with the regular expression rules. Still, the benefit of using it is in the ability not to use third-party dependencies.
As usual, we’ll discover a more comfortable way to deal with HTML parsing a bit later in this article.
Presenting data using console
And the last but not least part of our simple web scraper is data presenting to the end-user:
Not the most impressive part of the program, but this abstraction is required to use web scraping results. You can replace this part with an API call response, DB storing function, or displaying the data in UI.
Let’s move forward and check out valuable tools that cover data extraction needs.
Инструменты для парсинга стены ВКонтакте на Java
Парсинг стены ВКонтакте на Java становится все более актуальным, так как позволяет получать и анализировать данные из популярной социальной сети. Для этой задачи существует несколько инструментов, которые облегчают процесс парсинга и обработки информации.
Одним из таких инструментов является VK Java SDK. Он предоставляет разработчикам удобный API для работы с ВКонтакте и имеет ряд готовых методов для получения информации со стены пользователя или сообщества. С помощью этого SDK можно получить список постов, комментарии и другие данные, а также осуществить различные операции, такие как отправка сообщений или создание постов на стене.
Еще одним популярным инструментом для парсинга стены ВКонтакте на Java является VK API. Он также предоставляет удобное программное взаимодействие с ВКонтакте, но в отличие от VK Java SDK, не является официальным SDK и разрабатывается сообществом. VK API имеет крупное сообщество разработчиков, которые постоянно совершенствуют и обновляют его функционал.
Кроме указанных инструментов, существуют и другие библиотеки и фреймворки, которые можно использовать для парсинга стены ВКонтакте на Java. Некоторые из них предлагают дополнительные функции, такие как анализ тональности текста или рекомендации по постам, что может быть полезно при работе с полученной информацией.
Выбор конкретного инструмента для парсинга стены ВКонтакте на Java зависит от потребностей разработчика и задачи, над которой он работает. Ключевые критерии при выборе инструмента — это удобство использования, функционал, документация и поддержка сообщества разработчиков.
Примеры использования VK API на Java
Работа с VK API на Java может быть очень полезной для различных задач, связанных с социальной платформой VK. Представляем несколько примеров использования VK API на Java:
- Получение списка друзей пользователя: используя метод users.get с параметром fields=id,first_name,last_name,nickname можно получить список друзей пользователя, обрабатывая JSON-ответ, который возвращает API.
- Постинг на стену пользователя: используя метод wall.post с параметрами owner_id и message можно разместить запись на стене пользователя.
- Получение информации о группе: используя метод groups.getById с параметром group_id можно получить информацию о группе, такую как название, описание, количество участников.
- Поиск пользователей: используя метод users.search с параметром q можно осуществить поиск пользователей по заданным критериям, например по полу, возрасту и городу.
- Получение фотографии профиля: используя метод users.get с параметром fields=photo_100 можно получить ссылку на фотографию профиля пользователя в качестве аватара.
Это лишь некоторые из возможных примеров использования VK API на Java. Вся документация API доступна на официальной странице VK Developers.
Пример получения информации о пользователе
Для получения информации о пользователе в VK API необходимо выполнить запрос к методу users.get. Для этого требуется указать id, никнейм или домен пользователя.
Например, для получения информации о пользователе с id=1, необходимо выполнить следующий запрос:
Здесь:
- user_ids=1 — указывает id пользователя;
- fields=bdate,city,country — указывает, какую информацию о пользователе надо получить;
- access_token=ваш_токен — указывает ваш токен доступа;
- v=5.131 — версия API, которую вы используете.
Ответ от сервера будет содержать информацию о пользователе, например:
В ответе содержится id пользователя, его имя и фамилия, дата рождения, информация о городе и стране.
Пример отправки сообщения пользователю
Для отправки сообщения пользователю через VK API на Java необходимо выполнить следующие шаги:
- Получить токен пользователя. Для этого можно воспользоваться Implicit Flow авторизацией, которая не требует наличия сервера. Токен можно получить через , заменив APP_ID на идентификатор вашего приложения.
- Использовать VK API метод messages.send. Для отправки сообщения мы будем использовать метод messages.send. Необходимо вызвать его с передачей параметров:
- access_token — токен пользователя, полученный на первом шаге
- message — текст сообщения
- user_id — идентификатор пользователя, которому необходимо отправить сообщение
Пример вызова метода:
Где actor — это объект VKActor, который необходим для выполнения запросов к VK API. Его можно создать, передав идентификатор и секретный ключ вашего приложения:
В итоге, после выполнения этих шагов пользователю с идентификатором userId будет отправлено сообщение с текстом message.
Аутентификация пользователя
Для работы с VK API необходимо авторизоваться под своим пользователем и получить access_token. Для этого можно использовать следующие методы:
- Implicit Flow — подход, при котором клиентское приложение получает access_token после перенаправления на страницу авторизации VK. Этот способ удобен для прототипирования и установки разрешений по умолчанию, но не рекомендуется использовать в продакшене.
- Authorization Code Flow — более безопасный подход, при котором клиентское приложение получает код авторизации, а затем обменивает его на access_token. Для этого нужно перенаправить пользователя на страницу авторизации VK, передав приложению параметр redirect_uri.
Важно учитывать, что access_token является конфиденциальным и не должен передаваться по небезопасным каналам (например, в URL). Необходимо хранить его в безопасном месте и использовать только в рамках своего приложения
Авторизация через OAuth 2.0
OAuth 2.0 — это протокол для авторизации, который позволяет пользователям предоставлять доступ к своим данным в различных приложениях. В VK API используется именно эта версия протокола.
Чтобы использовать OAuth 2.0, необходимо получить доступ к приложению в VK API. Для этого нужно войти на сайт vk.com/developers, создать новое приложение и получить ID и секретный ключ приложения. Эти данные будут использоваться для авторизации через OAuth 2.0.
Чтобы получить токен, необходимо отправить HTTP-запрос с указанием своего ID приложения, секретного ключа и других параметров. Полученный токен будет использоваться для доступа к API VK.










Для авторизации через OAuth 2.0 можно использовать встроенный механизм авторизации VK API. Для этого нужно открыть новое окно браузера с URL-адресом https://oauth.vk.com/authorize. Затем пользователь должен ввести свои учетные данные и подтвердить разрешение на доступ к своим данным.
После успешной авторизации пользователя OAuth 2.0 в VK API, приложение получает токен доступа. Этот токен нужно сохранить, чтобы использовать его для доступа к API VK в дальнейшем.
Важно помнить, что OAuth 2.0 требует обработки ошибок и многоуровневой проверки безопасности для защиты пользовательских данных от несанкционированного доступа
Авторизация через VK SDK
Для начала работы с VK SDK необходимо авторизоваться в приложении ВКонтакте. Для этого нужно создать объект класса VKSdk, который предоставляет методы для работы с авторизацией.
Перед началом авторизации нужно зарегистрировать приложение в VK API и получить его идентификатор (App ID). Записать его в манифест приложения следующим образом:
<meta-data android_name=»com.vk.sdk.ApplicationId» android_value=»ВАШ_APP_ID» />
Также необходимо добавить разрешение на доступ к интернету и к данным пользователя:
<uses-permission android_name=»android.permission.INTERNET» />
<uses-permission android_name=»android.permission.ACCESS_NETWORK_STATE» />
Для начала авторизации нужно вызвать метод VKSdk.login(). Передаваемый параметр указывает на необходимость запроса прав на доступ к определенным данным пользователя, которые должны быть указаны в объекте VKScope.
После успешного прохождения авторизации необходимо получить объект VKAccessToken, который содержит информацию о токене доступа, его времени жизни и правах доступа. Это можно сделать следующим образом:
VKAccessToken token = VKAccessToken.currentToken();
В дальнейшем этот объект может использоваться для выполнения запросов к VK API. Если токен доступа не получен или устарел, необходимо снова выполнить авторизацию.
Что такое парсинг данных?
Парсинг данных – это процесс извлечения нужной информации из различных источников, например, веб-страниц. Для этого используется специальное программное обеспечение – парсер или скраппер. Он проходит по заданным страницам и собирает нужную информацию в соответствии с заданными правилами.
Парсинг данных часто применяется для автоматизации процессов сбора информации с сайтов. Например, компании могут использовать парсинг данных для извлечения цен на конкурирующие товары, для анализа акций и прогнозирования рынка, а также для получения информации о конкурентах и отзывах клиентов.
Парсинг данных может быть сложным и трудоемким процессом. При написании скриптов для парсинга необходимо учитывать множество факторов, таких как формат исходной страницы, использование анимации и динамического контента, а также возможные изменения на страницах. Однако правильно настроенный парсер может значительно упростить сбор и анализ данных в различных проектах.
Хорошие практики парсинга данных:
- Используйте стандартные библиотеки и пакеты для парсинга данных, чтобы минимизировать возможные ошибки.
- Указывайте явно правила для извлечения данных из источника, чтобы уменьшить риск ошибок при обработке данных.
- Проверяйте данные на корректность и соответствие заданным правилам при обработке и хранении данных.
- Обновляйте правила парсинга данных при необходимости, чтобы учитывать возможные изменения исходной страницы.
В целом, парсинг данных – это полезный инструмент для автоматизации сбора и анализа информации из различных источников. Более продвинутые варианты парсинга могут включать использование различных методов и технологий, таких как машинное обучение и искусственный интеллект, для более точного и эффективного сбора и обработки данных.
Как очистить данные веб-сайта с помощью Java?
- Шаг 1. Настройте среду
- Шаг 2. Проверьте страницу, которую хотите очистить
- Шаг 3. Отправьте HTTP-запрос и очистите HTML-код.
- Шаг 4: Извлечение определенных разделов
- Шаг 5: Экспортируйте данные в CSV.
Шаг 1. Настройте среду
Для начала создайте новый проект и импортируйте необходимые библиотеки Java:
- Суп: Отличная библиотека для работы с парсингом HTML и извлечения данных с веб-сайтов.
- Язык Apache Commons: Предоставляет полный набор утилит для работы со строками, массивами и другими распространенными типами данных.
Вы можете использовать Maven или Gradle для управления зависимостями. Вот как вы можете добавить зависимости с помощью Maven
Шаг 2. Проверьте страницу, которую хотите очистить
Щелкните правой кнопкой мыши страницу, которую вы хотите очистить, и выберите элемент проверки. Проверьте все имена элементов, чтобы очистить их правильно.
Шаг 3. Отправьте HTTP-запрос
Вам нужно отправить HTTP-запрос на сервер, чтобы очистить данные с веб-страницы. Используйте класс Java HttpURLConnection для отправки HTTP-запросов на подключение.
Вот как это сделать:
Что происходит в коде?
В приведенном выше коде мы создаем новый объект URL. И пытаемся открыть соединение с его сервером с помощью HttpURLConnection. Мы включили наш идентификатор как Mozilla Firefox. Наконец, мы читаем полученный ответ от сервера с помощью BufferedReader. Мы добавляем каждую входную строку в StringBuilder, чтобы преобразовать ее в удобочитаемую строку.
Шаг 4: Разберите HTML-документ
На этом этапе мы проанализируем HTML-документ с помощью JSoup. Мы можем выбрать элементы веб-страницы, которые мы хотим извлечь, используя имя тега, класс или идентификатор и просматривая дерево DOM.
Вот код использования Jsoup для разбора HTML.
В этом фрагменте кода мы сначала создаем новый объект Jsoup Document из строки HTML. Затем мы используем метод select для выбора всех ссылок на странице по их атрибуту href. Мы перебираем ссылки и извлекаем значение атрибута href с помощью метода attr.
Шаг 5. Сохраните данные в формате CSV.
Как только мы извлекли интересующие нас данные, мы можем сохранить их в файл или базу данных для дальнейшего анализа. В этом примере мы сохраним ссылки на файл CSV, используя библиотеку CSV Apache Commons.
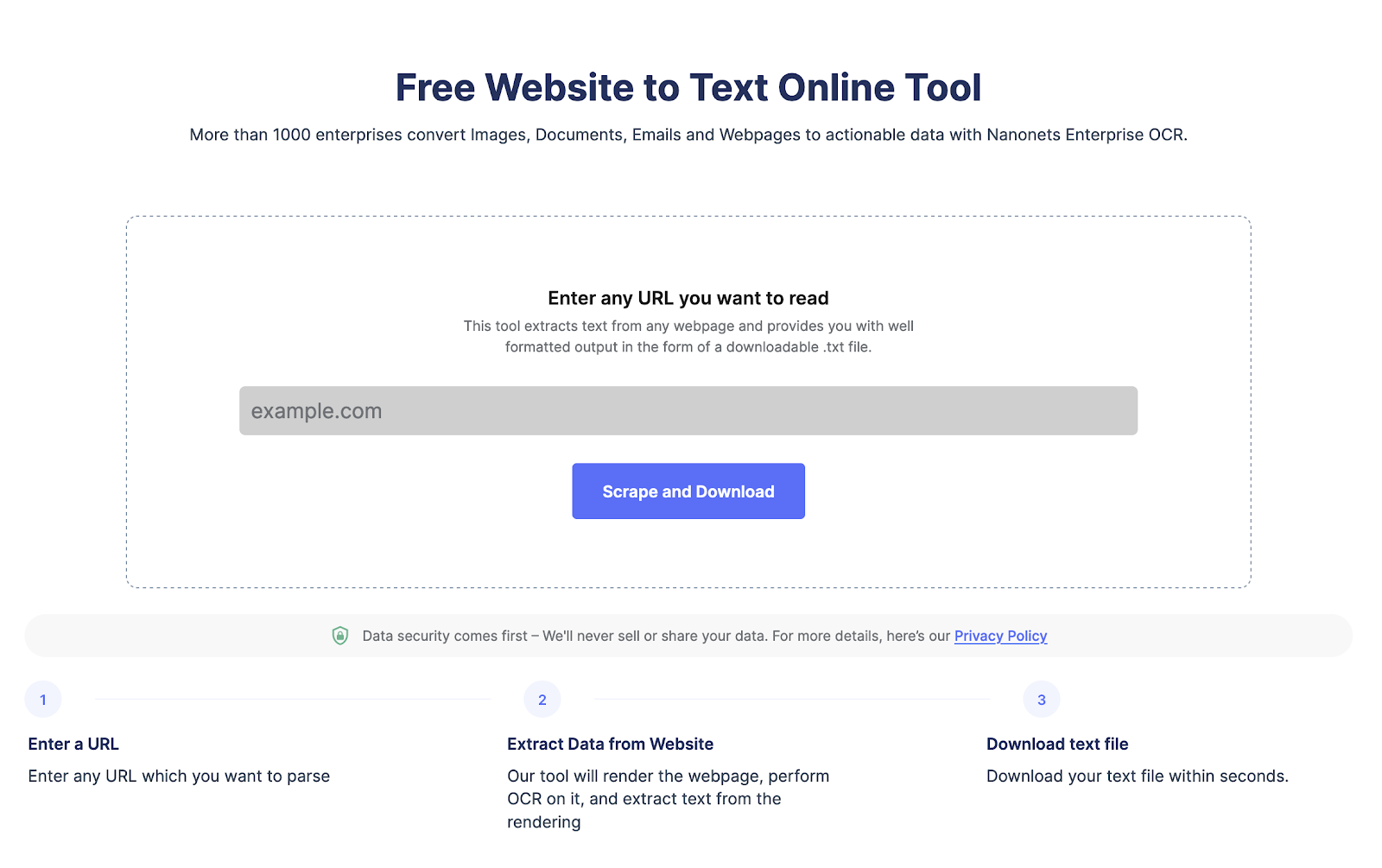
Извлекайте текст с любой веб-страницы всего одним щелчком мыши. Отправляйтесь в Нанонец парсер веб-сайтов, Добавьте URL-адрес и нажмите «Очистить», чтобы мгновенно загрузить текст веб-страницы в виде файла. Попробуйте бесплатно прямо сейчас.
Простой способ парсинга данных с сайта на Java
Парсинг данных с сайта – одна из важных задач веб-разработки. С помощью Java можно легко и быстро обработать полученные данные, привести их в нужный вид и использовать в своих проектах.
Для начала нужно выбрать подходящую библиотеку для парсинга данных. Например, jsoup – это удобная библиотека, которая позволяет получить данные из HTML-файлов и формировать запросы к сайтам. В качестве альтернативы можно использовать библиотеку HTML Parser.
Для использования библиотеки jsoup нужно добавить ее в проект, задать путь к файлу и получить доступ к доступным методам. Например, методы для получения текста, изображений, ссылок и других элементов веб-страницы.
Для парсинга данных необходимо знать структуру HTML-кода, чтобы корректно выбирать нужные элементы. За это отвечают CSS-селекторы. С их помощью можно выбрать элементы страницы по тегам, классам, атрибутам и т.д.
Для удобства обработки данных можно использовать циклы, условия и коллекции. Например, можно выбрать все элементы с определенным классом, пройтись по ним в цикле и сохранить нужные значения в коллекцию.
В итоге, парсинг данных с сайта на Java не является сложной задачей, если использовать правильные инструменты и знать основы работы с HTML и CSS. Библиотека jsoup делает эту задачу еще более простой и удобной.
Шаг 1: Выбор библиотеки для парсинга данных
Перед тем как приступить к парсингу данных с сайта, необходимо выбрать подходящую библиотеку для данной задачи. В Java существует множество библиотек для парсинга данных, однако, из представленных вариантов рекомендуется использовать библиотеку Jsoup. Эта библиотека предоставляет удобный и интуитивно понятный API, а также дает возможность быстро и качественно парсить данные.
Для установки библиотеки Jsoup необходимо добавить зависимость в Maven:
После добавления зависимости, можно начинать парсить данные. Библиотека Jsoup позволяет парсить как HTML, так и XML документы, а также работать с CSS селекторами для выбора нужной информации на странице. Это существенно упрощает процесс парсинга данных и дает возможность быстро получить нужную информацию.
Кроме Jsoup, существуют и другие библиотеки для парсинга данных в Java, такие как Selenium, HtmlUnit, Jaunt и другие. Однако, при выборе библиотеки необходимо учитывать задачи, которые требуется выполнить, и особенности целевого сайта. В конкретных случаях может быть полезнее использовать другую библиотеку для парсинга данных.
Итак, первым шагом при парсинге данных с сайта необходимо выбрать подходящую библиотеку для данной задачи. В большинстве случаев рекомендуется использовать библиотеку Jsoup, так как это позволяет быстро и удобно получить нужную информацию на странице.




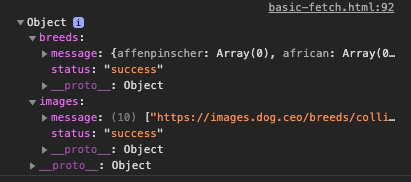
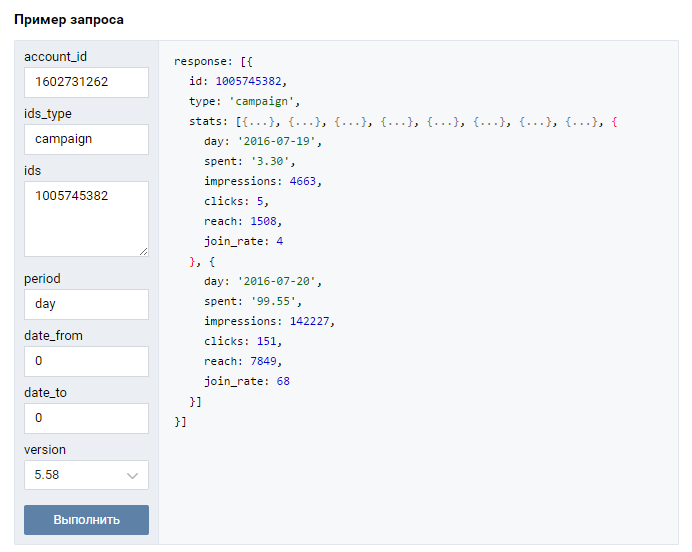



Шаг 2: Импортирование библиотеки в проект
После скачивания библиотеки jsoup вам необходимо добавить ее в проект. Для этого выполните следующие действия:
- 1. Откройте вашу Integrated Development Environment (IDE).
- 2. Создайте новый проект или откройте существующий.
- 3. Нажмите на правую кнопку мыши на проекте в обозревателе проектов.
- 4. Выберите пункт «Properties» или «Свойства».
- 5. В открывшемся окне выберите пункт «Java Build Path» или «Путь сборки Java».
- 6. Нажмите на кнопку «Add External JARs» или «Добавить внешние JAR-файлы».
- 7. Выберите файл jsoup.jar, который вы скачали на предыдущем шаге.
- 8. Нажмите на кнопку «OK».
После выполнения всех шагов библиотека jsoup будет добавлена в ваш проект, и вы будете готовы к парсингу данных с сайта на Java.
Шаг 3: Написание кода для парсинга данных
Для начала необходимо установить библиотеку Jsoup, которую мы будем использовать для парсинга данных. Для этого нужно добавить зависимость в файл pom.xml:
- Перейти в раздел Dependencies
- Добавить зависимость com.github.jsoup:jsoup:1.14.2
После установки библиотеки можно начать написание кода для парсинга данных. Для этого нужно создать экземпляр класса Document, которому необходимо передать ссылку на страницу, которую мы будем парсить:
Теперь мы можем использовать методы Jsoup для поиска элементов на странице и извлечения нужных данных. Например, для поиска всех заголовков можно использовать следующий код:
Для получения содержимого тега можно использовать метод text():
Также можно извлекать атрибуты тегов, например, ссылки:
Таким образом, используя библиотеку Jsoup и написав несколько строк кода на Java, мы можем быстро и просто получить нужные данные с любого сайта.
Как парсинг данных используется в бизнес-целях?
Для примера возьмем сферу e-commerce. С помощью автоматического парсинга данных можно собирать информацию о товарах конкурентов на их страницах и анализировать важные параметры:
- цены;
- ассортимент;
- политику скидок;
- описание и фотографии товаров.
Так продавец всегда будет в курсе действий конкурентов и сможет своевременно подстроиться под них, чтобы не терять клиентов. Кроме того, парсингом легко собирать отзывы и сообщения с упоминанием бренда или товаров на различных площадках, чтобы выявлять и исправлять проблемы, понимать потребительские предпочтения и прогнозировать спрос на товары.
Стандартные методы класса String
Класс String в Java обладает множеством стандартных методов, которые позволяют эффективно выполнять различные операции со строками. Ниже приведены некоторые из наиболее полезных методов класса String:
- length() – возвращает длину строки
- charAt(int index) – возвращает символ по указанному индексу
- substring(int beginIndex) – возвращает подстроку, начиная с указанного индекса
- substring(int beginIndex, int endIndex) – возвращает подстроку, начиная с указанного начального индекса и заканчивая указанным конечным индексом
- concat(String str) – объединяет указанную строку с текущей строкой
- trim() – удаляет пробелы в начале и конце строки
- toLowerCase() – преобразует все символы строки в нижний регистр
- toUpperCase() – преобразует все символы строки в верхний регистр
- replace(char oldChar, char newChar) – заменяет все вхождения указанного символа на новый символ
- indexOf(String str) – возвращает индекс первого вхождения указанной подстроки
- lastIndexOf(String str) – возвращает индекс последнего вхождения указанной подстроки
Это лишь небольшой набор методов класса String, доступных в Java. Они помогают обрабатывать и изменять строки в удобной и эффективной манере. При работе со строками в Java необходимо использовать эти методы для получения нужных результатов.
split()
Для использования метода split() необходимо вызвать его у строки, которую вы хотите разделить, и передать разделитель в качестве параметра.
Например, если у вас есть строка “Java – лучший язык программирования!”, и вы хотите разделить ее по символу “-“, можно использовать следующий код:
В результате выполнения кода каждая часть строки, разделенная символом “-“, будет сохранена в массиве parts.
Вы также можете использовать регулярные выражения в качестве разделителя. Например, чтобы разделить строку по пробелам, вы можете использовать следующий код:
В данном случае, “\\s+” – это регулярное выражение, указывающее на один или несколько пробелов в качестве разделителя.
Метод split() возвращает массив подстрок, полученных после разделения строки. Вы можете использовать эти подстроки в своей программе в соответствии с вашими потребностями.
Примечание: Если разделитель не найден в строке, метод split() вернет массив, содержащий только исходную строку.
substring()
Синтаксис метода выглядит следующим образом:
String substring(int startIndex)
String substring(int startIndex, int endIndex)
Где startIndex – это индекс символа, с которого начинается подстрока. endIndex – это индекс символа, на котором заканчивается подстрока.
Если указан только startIndex, то метод вернет подстроку, начиная с этого индекса и до конца строки.
Метод substring() очень полезен при обработке строк, например, при извлечении определенных значений из URL-адреса, парсинге даты или времени, разделении отдельных слов и т.д.
Пример использования метода:
В результате получим подстроку “world”.
Необходимо помнить, что метод substring() возвращает новую строку, исходная строка остается неизменной.