
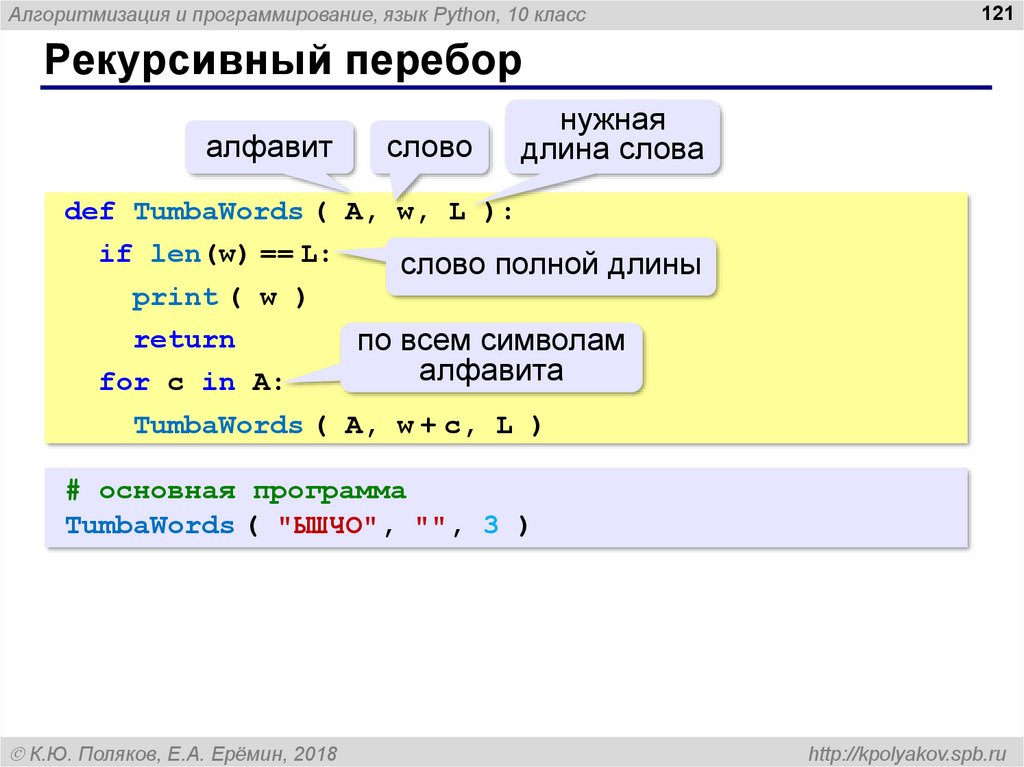
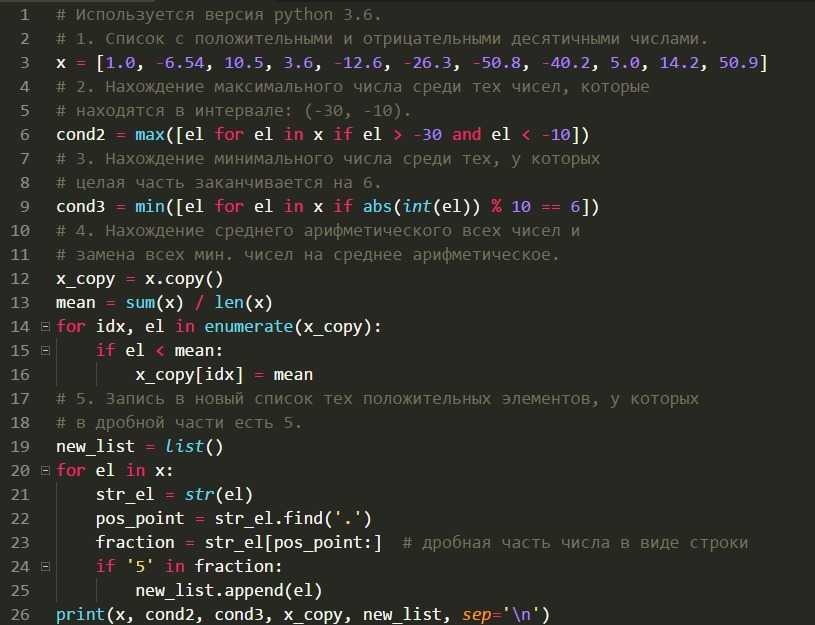
Difference between text files and binary files
In binary files, a structure’s contents are always editable. Any structure in the file can be accessed immediately, offering random access similar to that of an array.
The file-of-structures approach is very well supported in C. You can read, write to, or seek to any structure in the file after it has been opened. The idea of a file pointer is supported by this file concept. The pointer points to record 0 when the file is initially opened. Any read operation advances the pointer down one structure and reads the structure that is presently pointing to. Any write operation shifts the pointer down one structure and writes to the structure that is currently being referenced to. The pointer is moved to the specified record by seeking.
Because a binary image of the record is stored directly from memory to disc, binary files typically have faster read and write times than text files.
A text file is meant to be readable and understandable by humans. This used to mean good old ASCII but now includes other human-language character sets as well. It even includes things like HTML or XML, which are often human-readable by a very generous definition. You can still open them in a text editor, they’ll display sensibly, and you can see something reasonably meaningful. Binary is anything else. All files are ultimately stored in binary form.
There’s actually a particular context in which «text» and «binary» actually mean something similar and are distinct from anything else. A compiled program, as distinct from its source code or data files, is called a binary. If you use the right tools to peek inside a binary, you’ll find that one of the segments is called «text», meaning that it’s the main piece of executable code — not libraries, data, etc. This same terminology repeats inside the kernel, which uses this information to load the various pieces of the program into memory. In this linker/loader context, «text» is part of a «binary», and «binary» refers to a specific kind of file.
Работа с двоичными файлами в Python
В Python для работы с файлами существует два режима: текстовый и бинарный. Различие между ними заключается в том, как интерпретируются символы новой строки и как обрабатываются байты данных.
Различие между текстовым и бинарным режимом:
-
Текстовый режим ():
- Символ новой строки () может быть автоматически преобразован в соответствующий формат для операционной системы (например, в Windows).
-
Текстовый режим удобен для работы с обычными текстовыми файлами, где структура данных представляет собой последовательность символов.
-
Бинарный режим ():
- Байты данных считываются и записываются без изменений. Никаких автоматических преобразований символов новой строки не происходит.
-
Бинарный режим подходит для работы с файлами, в которых содержится необработанный двоичный код, такими как изображения, аудиофайлы и другие бинарные данные.
Использование с параметром для чтения бинарных данных:
Использование с параметром для записи бинарных данных:
Помните, что при работе с бинарными данными важно быть внимательным к формату данных, чтобы избежать ошибок при их интерпретации. В некоторых случаях может быть полезно использовать модуль для структурированной обработки бинарных данных
How To Read Binary File in C++?
You can read a binary file using the ::read() method invoked from the std::fstream object. This built-in function extracts characters from the stream and stores them at the address of the char pointer passed to it as the first argument.
Notice that this function also takes a number of characters that need to be read from the file stream. The next example code demonstrates only a raw usage of the ::read() function.
Generally, reading and writing binary files requires proposed formatting that will make data persistent in the filesystem or over the communication medium. Furthermore, this demands more delicate usage of STL classes and preferably designing custom classes that are based on std::basic_streambuf. Alternatively, one can employ third-party C++ libraries that provide the needed functionality.
– Code For Read
| #include <iostream> #include <fstream> #include <vector> #include <sstream> #include <filesystem>using std::cout; using std::cerr; using std::endl; using std::string;int main() { string filename(“newfile.txt”); std::fstream file; file.open(filename, std::ios_base::in | std::ios::binary);if (!file.is_open()) { file.clear(); file.open(filename, std::ios_base::out | std::ios_base::binary); file.close(); file.open(filename, std::ios_base::in | std::ios_base::binary);cout << “a new file was created!” << endl; } else if (file.good()) { cout << “file already exists.” << endl; cout << “file was opened on the first try!” << endl; } auto file_size = std::filesystem::file_size(filename); char *data = reinterpret_cast<char *>(new int); file.read(data, file_size); std::string output(data); cout << output << endl; exit(0); } |
Открытие файла
Python предоставляет функцию open(), которая принимает два аргумента: имя файла и режим доступа, в котором осуществляется доступ к файлу. Функция возвращает файловый объект, который можно использовать для выполнения различных операций, таких как чтение, запись и т. д.
Синтаксис:
file object = open(<file-name>, <access-mode>, <buffering>)
Доступ к файлам можно получить с помощью различных режимов, таких как чтение, запись или добавление. Ниже приведены подробные сведения о режимах доступа для открытия файла.
| Режим доступа | Описание | |
|---|---|---|
| 1 | r | Он открывает файл в режиме только для чтения. Указатель файла существует в начале. Файл по умолчанию открывается в этом режиме, если не передан режим доступа. |
| 2 | rb | Открывает файл в двоичном формате только для чтения. Указатель файла существует в начале файла. |
| 3 | г + | Открывает для чтения и записи. Указатель файла также существует в начале. |
| 4 | rb + | в двоичном формате. Указатель файла присутствует в начале файла. |
| 5 | w | Только для записи. Он перезаписывает файл, если он существовал ранее, или создает новый, если файл с таким именем не существует. Указатель имеется в начале файла. |
| 6 | wb | Открывает файл для записи только в двоичном формате. Перезаписывает файл, если он существует ранее, или создает новый, если файл не существует. Указатель файла существует в начале файла. |
| 7 | w + | Для записи и чтения обоих. Он отличается от r + в том смысле, что он перезаписывает предыдущий файл, если он существует, тогда как r + не перезаписывает ранее записанный файл. Он создает новый файл, если файл не существует. Указатель файла существует в начале файла. |
| 8 | wb + | Он открывает файл для записи и чтения в двоичном формате. Указатель файла существует в начале файла. |
| 9 | а | В режиме добавления. Указатель файла существует в конце ранее записанного файла, если он существует. Он создает новый файл, если не существует файла с таким же именем. |
| 10 | ab | В режиме добавления в двоичном формате. Указатель существует в конце ранее записанного файла. Он создает новый файл в двоичном формате, если не существует файла с таким же именем. |
| 11 | а + | Он открывает файл для добавления и чтения. Указатель файла остается в конце файла, если файл существует. Он создает новый файл, если не существует файла с таким же именем. |
| 12 | ab + | Открывает файл для добавления и чтения в двоичном формате. Указатель файла остается в конце файла. |
Давайте посмотрим на простой пример, чтобы открыть файл с именем «file.txt»(хранящийся в том же каталоге) в режиме чтения и распечатать его содержимое на консоли.
Пример:
#opens the file file.txt in read mode
fileptr = open("file.txt","r")
if fileptr:
print("file is opened successfully")
Выход:
<class '_io.TextIOWrapper'> file is opened successfully
В приведенном выше коде мы передали filename в качестве первого аргумента и открыли файл в режиме чтения, поскольку мы упомянули r в качестве второго аргумента. Fileptr содержит объект файла, и если файл открывается успешно, он выполнит оператор печати.
Преимущества использования бинарных файлов
При работе с данными в программировании, бинарные файлы представляют собой особый формат хранения информации, который обладает несколькими преимуществами перед другими типами файлов.
1. Эффективность хранения и передачи данных
Бинарные файлы позволяют хранить и передавать данные более компактно и эффективно, по сравнению с текстовыми файлами. Это связано с тем, что бинарные файлы сохраняют данные в более низкоуровневом виде, без необходимости хранения дополнительной информации, такой как символы перевода строки или пробелы.
2. Отсутствие проблем с кодировкой
Бинарные файлы не зависят от конкретной кодировки символов, поэтому они идеально подходят для работы с данными, включающими специальные символы или символы, отличные от стандартной кодировки. Это особенно полезно при работе с данными, содержащими графику, звук или видео.
3. Быстрый и простой доступ к данным
Бинарные файлы позволяют быстро и просто считывать и записывать данные. Так как они хранят данные в бинарном виде, для их чтения или записи нет необходиомсти выполнять сложные операции преобразования типов данных или обработки символов, что делает работу с ними более эффективной.
4. Поддержка структурированных данных
Бинарные файлы позволяют сохранять структурированные данные, такие как массивы, структуры или классы, без потери информации о их внутреннем формате. Это позволяет программам быстро и эффективно работать с такими данными, даже после сохранения и загрузки в файл.
5. Защита данных
Бинарные файлы могут быть защищены от несанкционированного доступа и изменений
Это особенно важно при работе с конфиденциальными или важными данными, которые должны быть надежно защищены
В итоге, использование бинарных файлов позволяет повысить эффективность работы с данными, обеспечить их сохранность и защиту, а также упростить и ускорить процесс обработки данных в программировании.
Особенности работы с бинарными «элементами»
Текстовый файл – понятие далеко не новое. Оно встречается не только в программировании. В Google можно отыскать четкое определение оному. И работа с «обычным текстом» при написании кодификаций не такая уж трудная.
Сложнее использовать двоичный файл. Он встречается в кодах чаще всего. В основном используется для записи чисел и значений.
Для того, чтобы в Си-семействе (в C++ в особенности) работать с бинарными файлами, согласно Google, используется стандартная библиотека. Для текстовых применяются:
- fscanf;
- fpintf.
Бинарные файлы тоже используют соответствующие «архивы», но с некоторыми корректировками. Пример – для чтения используют не параметр «r», а «rb». Работа осуществляется непосредственно с битами. Доступ к данным осуществляется произвольным образом.
Доступ к информации в функции
Для того, чтобы получить доступ к информации в функции произвольно, записывается следующая кодификация:
Fseek (переменная, расстояние, seek_set или seek_cur или seek_end).
Здесь имеет место следующая расшифровка:
- seek_set – открываем файл и ведем отсчет от начала;
- seek_cur – непосредственно от установленного курсора;
- seek_end – конец файла.
Для того, чтобы рассчитать расстояние (битов, на «размер» которых сдвигается указатель), используют sizeof().
Запись и чтение
Немаловажным моментом является запись и чтение. При помощи Google можно разобраться с тем, как создается и используется поток поступаемой информации при обработке кода. Но без «базы» осознать соответствующую информацию не выйдет.
Для записи бинарного файла (из данных Google) используется запись:
Fwrite (ссылка на записываемую информацию, размер, количество «сведений», файловая переменна).
Для того, чтобы осуществить чтение соответствующего документа, задействуется функция под называнием fread. Параметры у нее будут аналогичные.

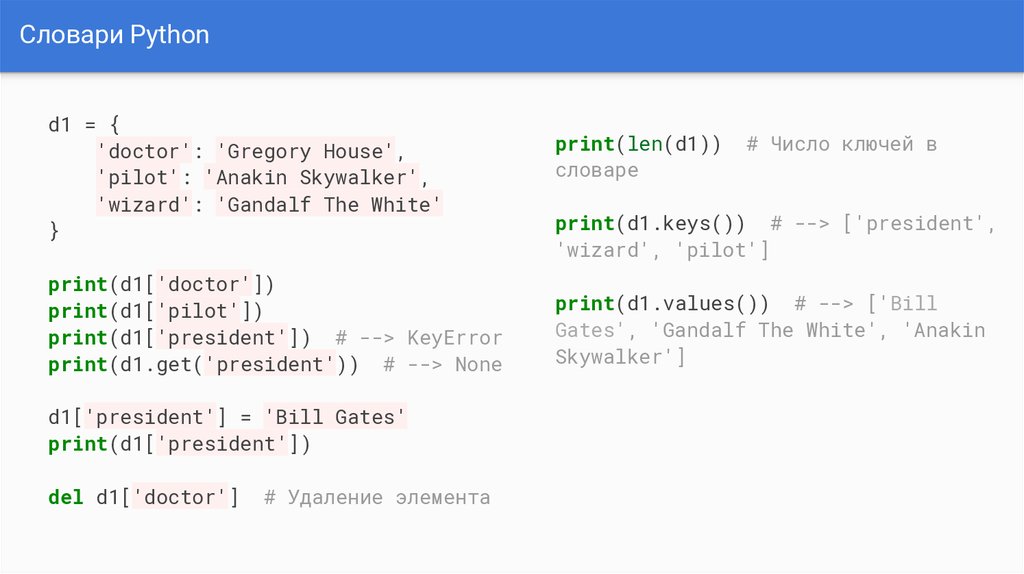
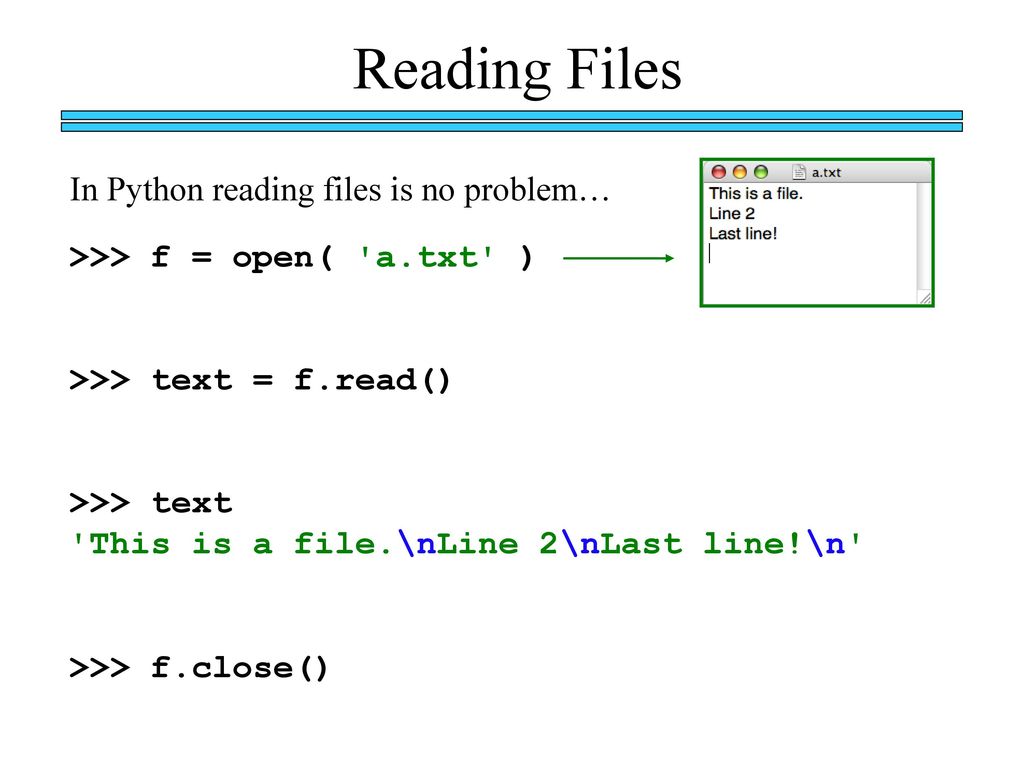


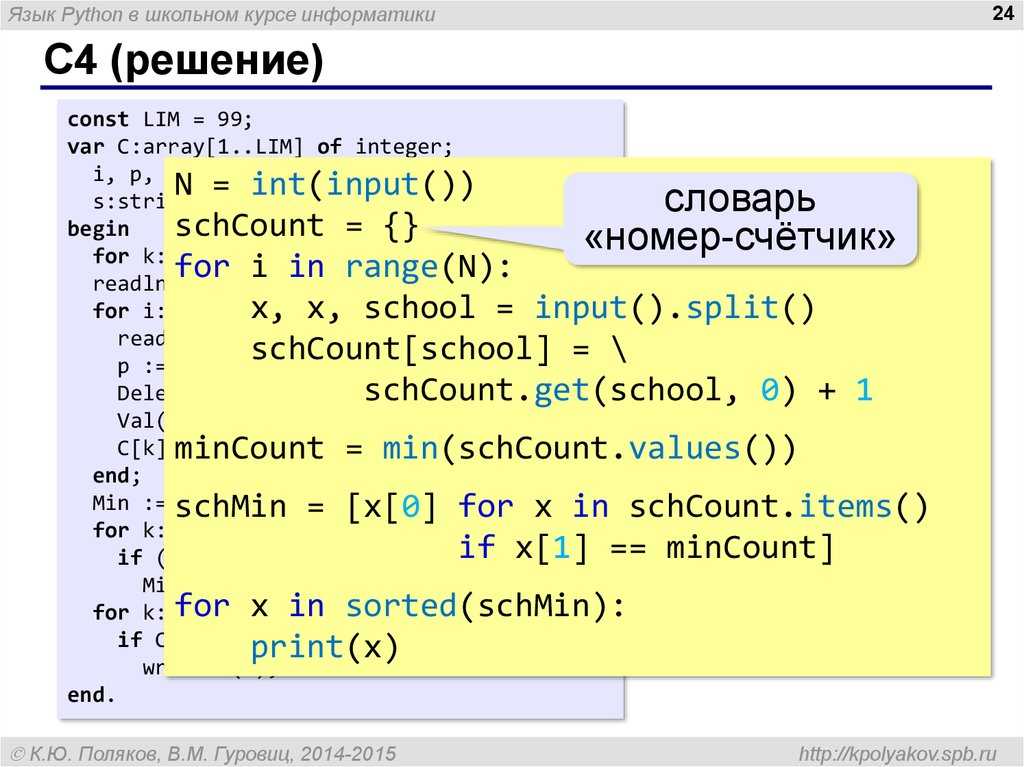
Чтение потоковых данных
Чтение потоковых двоичных данных в Python подразумевает обработку непрерывного потока байтов, который может представлять данные, поступающие из различных источников, таких как сетевые соединения, аудио-и видеопотоки, а также другие форматы данных, передаваемые по потоку.
Для этого в Python часто используются библиотеки, такие как , которая предоставляет инструменты для структурированного чтения и записи данных в бинарном формате. Давайте рассмотрим общий подход к чтению потоковых двоичных данных.
Использование библиотеки :
-
Открытие потока байтов:
Например, если у вас есть сетевое соединение, вы можете использовать библиотеку socket для получения данных:
import socket# Установка соединения
server_address = (‘localhost’, 12345)
with socket.create_connection(server_address) as sock:
# Получение данных
binary_data = sock.recv(1024)
-
Использование для интерпретации данных:
struct позволяет определить формат данных и распаковать их в соответствии с этим форматом.
import struct# Формат данных: два целых числа (int), одно число с плавающей запятой (float)
format_string = ‘iif’
data_size = struct.calcsize(format_string) # Определение размера данных# Распаковка данных
unpacked_data = struct.unpack(format_string, binary_data)# Вывод распакованных данных
print(unpacked_data)
-
Обработка данных:
Теперь у вас есть распакованные данные, которые вы можете использовать в вашем приложении.
Пример чтения аудиопотока:
Здесь представлен пример чтения аудиопотока с использованием сетевого соединения и библиотеки . Формат данных определен как 16-битные целые числа (short), и приложение может обработать эти аудиообразцы в функции .
Важно помнить, что при работе с потоковыми данными необходимо обращать внимание на синхронизацию и обработку данных в реальном времени в зависимости от конкретного применения
How do they work?
When it comes to files, binary has two widely used definitions.
1. The file is executable.
2. It cannot be read by humans
For (1), the executable likely has a particular format that any operating system «loader» mechanism can understand. In order to launch the program, the OS loader must first read it from the disc, allocate and copy the necessary bytes to memory, and then spawn a process. Additionally, libraries may need to be loaded dynamically.
For (2), those bytes’ meaning was determined by someone somewhere. It might be as complex as an official standard like MP3 or as simple as a coder sending a few bytes to the file, and only by reading the code can it be understood.
Writing into the File
Enough talking, let’s start by writing a text content into the file using . Before all of that, you need to instantiate the ofstream and open the file:
Enter fullscreen modeExit fullscreen mode
The function, as it says, open the file with name (first argument) and the mode (second argument).
I will discuss different modes with you as we proceed, mode is used to tell the function, that opens the file in write mode, overwrite the contents of it if it exists or create a new one.
Now it’s time to write into the file stream using the left shift operator . This will format all your data into before writing.
Enter fullscreen modeExit fullscreen mode
Since we are using a pointer variable, therefore it is required to dereference the file handle to access the operator from the object stored.
Binary Mode fopen flags
The flag might contain 1-2 characters as string. Each character is in short hand form and represents the mode name. B — Stands for Binary. R — Stands for read, W — Stands for write, A — Stands for Append. The default is text mode unless B is specified in the flag.
| #1 |
Binary Read (rb) Opens a file in binary read mode |
SYNTAX: |
| #2 | Binary write (wb) Opens a file in binary write mode. |
SYNTAX: |
| #3 | Binary append (ab) Opens a file in binary append mode i.e. to add at the end of file. |
SYNTAX: |
| #4 | Binary read+write (r+b) Opens preexisting file in read and write mode. |
SYNTAX: |
| #5 | Binary write+read (w+b) Open file for binary reading and writing also creates a new file if not exists. |
SYNTAX: |
| #6 | Binary append+write (a+b) Opens file in append mode i.e. data can be written at the end of file. |
SYNTAX: |
Чтение структуры из бинарного файла
Чтобы прочитать данные из бинарного файла в виде структуры, необходимо сначала открыть файл в режиме бинарного чтения с помощью функции fopen(). Затем нужно использовать функцию fread(), чтобы прочитать данные из файла и сохранить их в структуре.
Пример кода:
#include
struct Person
{
char name;
int age;
float height;
};
int main()
{
FILE *file = fopen("data.bin", "rb");
if (file == NULL)
{
printf("Ошибка открытия файла
");
return 1;
}
struct Person person;
fread(&person, sizeof(struct Person), 1, file);
printf("Имя: %s
", person.name);
printf("Возраст: %d
", person.age);
printf("Рост: %.2f
", person.height);
fclose(file);
return 0;
}
В этом примере мы объявляем структуру Person, которая содержит поля name (типа массив char), age (типа int) и height (типа float). Затем мы открываем файл «data.bin» в режиме бинарного чтения с помощью функции fopen().
Далее мы объявляем переменную person типа Person, в которую будут записаны прочитанные данные. Затем мы вызываем функцию fread(), которая считывает данные из файла и сохраняет их в структуре person. Первый аргумент функции fread() — это указатель на переменную, в которую нужно записать данные, второй аргумент — размер одного элемента для чтения (в данном случае sizeof(struct Person)), третий аргумент — количество элементов для чтения (в данном случае 1), четвертый аргумент — указатель на файл.
Таким образом, мы можем считывать данные из бинарного файла в виде структуры на языках С/С++ с помощью функций fopen(), fread() и fclose(). Это позволяет нам удобно работать с данными внутри файла и использовать их в наших программах.
Как открыть бинарный файл в Python?
Открытие бинарного файла в Python необходимо для работы с различными видами файлов, в том числе изображениями, звуковыми файлами и прочими типами файлов. Для начала работы с бинарным файлом, необходимо определить тип открываемого файла и установить режим доступа — чтение или запись.
Для открытия бинарного файла в Python используется функция open(). Для работы с бинарным файлом, нужно установить флаг ‘b’. Пример открытия бинарного файла для чтения:
Пример:
- file = open(«example.bin», «rb»)
- # операции с файлом
- file.close()
Функция open() возвращает объект файла, который можно использовать для чтения или записи данных. В данном примере, бинарный файл example.bin открывается для чтения, флаг ‘rb’ указывает, что файл должен быть открыт в бинарном режиме чтения.
Также, для записи в бинарный файл используется флаг ‘wb’:
Пример:
- data = b»Hello, world!»
- file = open(«example.bin», «wb»)
- file.write(data)
- file.close()
В данном примере, бинарный файл example.bin открывается для записи, флаг ‘wb’ указывает, что файл должен быть открыт в бинарном режиме записи. Функция write() используется для записи данных в файл.





Открытие бинарного файла в Python — необходимая операция для работы с различными типами файлов
Важно помнить о необходимости установки правильного режима доступа и использованию флага ‘b’ в функции open() при открытии файла в бинарном режиме
Открытие файла в режиме чтения
Для работы с бинарными файлами в Python, важно знать, как их открывать. Один из важных моментов — это режим открытия файла
Если нужно только прочитать информацию из файла, то надо открыть его в режиме чтения.
Чтобы открыть файл в режиме чтения, нужно использовать функцию open(). Её первый аргумент — путь к файлу, а второй — режим открытия файла. Режим устанавливается с помощью флага ‘r’, который передается как параметр второго аргумента.
Пример:
data = f.read()
В примере выше открывается файл с именем «filename.bin» в режиме чтения бинарного файла (‘rb’). Далее функция read() считывает все данные из файла в переменную data.
Важно помнить, что во время открытия файла в режиме чтения нельзя записывать в него данные. Для этого нужно использовать режим записи (‘w’, ‘wb’)
Открытие файла в режиме записи
Открытие файла в режиме записи происходит с помощью функции open() с аргументом «w». Этот режим позволяет программисту записывать данные в файл.
При открытии файла в режиме записи, все данные в файле будут удалены, и новые данные будут записаны вместо них. Если файл с таким названием не существует, он будет создан.
Пример открытия файла в режиме записи:
Теперь можно записать данные в файл, используя метод write().
Пример записи данных в файл:
После записи данных в файл необходимо закрыть его с помощью метода close().
Пример закрытия файла:
Важно помнить, что открытый файл должен быть закрыт после окончания работы с ним, чтобы предотвратить потерю данных или падение производительности программы
Открытие файла в режиме добавления
В Python для открытия файла в режиме добавления используется режим «a» (append). Этот режим позволяет добавлять данные в конец файла, без изменения уже существующих данных.
Для открытия файла в режиме добавления используется функция open(), которая принимает два параметра: название файла и режим открытия. Если файл не существует, то он будет создан в процессе открытия.
Пример:
f = open(‘file.txt’, ‘a’)
После открытия файла в режиме добавления, данные можно записывать в файл с помощью метода write(). После записи данных, необходимо закрыть файл, используя метод close().
Пример:
| f = open(‘file.txt’, ‘a’) | # открываем файл в режиме добавления |
| f.write(‘some data’) | # записываем данные в файл |
| f.close() | # закрываем файл |
Кроме того, можно записывать данные в файл с помощью оператора print(), используя параметр file, который указывает на объект файла.
Пример:
| f = open(‘file.txt’, ‘a’) | # открываем файл в режиме добавления |
| print(‘some data’, file=f) | # записываем данные в файл |
| f.close() | # закрываем файл |
Открытие файла в режиме добавления позволяет безопасно добавлять данные в файл, не перезаписывая уже существующие данные. Это очень удобно, если нужно добавлять данные в файл по мере их поступления, например, в лог-файлах.
Чтение бинарных данных из файла
Чтение бинарных данных из файла в Python выполняется с использованием метода , когда файл открыт в бинарном режиме (). Этот метод позволяет считывать определенное количество байтов из файла. Давайте рассмотрим этот процесс более подробно:
-
Открытие файла в бинарном режиме:
-
Использование метода :
В данном примере, file.read() считывает все бинарные данные из файла binary_file.bin и сохраняет их в переменной binary_data.
-
Чтение и интерпретация байтов:
- Полученные данные представлены в виде байтовой строки (). Каждый байт представляет собой числовое значение от 0 до 255.
- Для интерпретации и работы с содержимым байтовой строки, мы можем использовать цикл или индексирование.
Пример обработки считанных бинарных данных:
Пример полного кода:
Этот код открывает бинарный файл , считывает все его содержимое в байтовую строку , а затем выводит первые 10 байт в шестнадцатеричной форме.
Важно помнить, что при чтении бинарных данных нужно быть внимательным к их формату, особенно если данные представляют сложные структуры, такие как изображения или аудиофайлы. В некоторых случаях может потребоваться использовать библиотеки, такие как для структурированного чтения данных
Read File Contents Byte by Byte in C++
C++ red file byte by byte can be achieved using the C standard library facilities for I/O. In our case, we are going to employ the fread() function to read binary stream data and then print bytes in hexadecimal notation.








This solution is demonstrated in the following code snippet, where you would only need to modify a filename that should be accessible to the program. If your file is located in a different location than the compiled program, then you should specify the path to it.
Notice that this code example also utilizes fopen() function from the C standard library to retrieve FILE* object – later to be passed as an argument for the fread() function. Moreover, stat() Unix system call is used to retrieve the size of the file. Finally, we use printf() to output contents byte by bytes to the terminal formatted in hexadecimal notation.
Note that the memory should be allocated dynamically for the array where the file contents are saved, and you should be aware of the allocation errors if the file to be read is relatively huge. You might also choose to map files into the memory using platform-specific API, e.g., mmap() in POSIX systems.
– Code For C++ Read File Byte by Byte
| #include <iostream> #include <sys/stat.h> #include <unistd.h> #include <unistd.h>using std::cout; using std::cerr; using std::endl; using std::string;int main() { string filename(“filename”); auto in_file = fopen(filename.c_str(), “rb”); if (!in_file) { perror(“fopen”); exit(EXIT_FAILURE); }struct stat sb{}; if (stat(filename.c_str(), &sb) == -1) { perror(“stat”); exit(EXIT_FAILURE); }u_char* file_contents = new u_char; fread(file_contents, sb.st_size, 1, in_file); for (int i = 0; i < sb.st_size; ++i) { printf(“%02X “, file_contents); if (i % 10 == 0 && i != 0){ cout << ‘n’; } } delete [] file_contents; |
Binary files – an efficient way to read and write data
We assume here that the reader is somewhat familiar with the different types and the C++ syntax.
Why binary?
A common way to store data in file is to save it in plain text. In effect, this is simple and convenient. More often than not however, this is inefficient: the files are big, slow to write and slow to read. A faster and lighter way of storing data is to directly save its bytes from the memory.
Consider an array of 8 values that all have 5 decimals
In a text file, this data could be saved by separating each value with a space and by writing the numbers in strings. If the file uses the ASCII character set, every character requires 1 byte. This way, each number would occupy
In addition, each character is separated by a space, which adds 7 extra characters to the file. In total, the file size would be
In constrast, the type only occupies 4 bytes of memory. In this manner, if the binary reprensation of the numbers is written in the file, its size is
The file is almost half the size of its text counterpart!
How to implement it?
The process involving writing to binary is more complex and tedious than the usual text file, but it is managable. The first difference is that the flag “binary” must be set to the file stream
In order to write the data in the file, it must be casted (transformed) into an array of characters. This can be done with a C-type cast
Note here that the reference of the variable is used. Here comes the trickier part: the number of bytes saved must be passed in argument to the method. Even though there is a built-in function that returns the size of a type, one must proceed carefully because it does not always give directly the required size.
In the proposed exampled, there are two ways to go about the writing process. The most intuitive way is to loop on the values stored and write them one by one
The second way involves taking advantage of the contiguous memory used by arrays. When the array was declared, 8 locations of 4 bytes were allocated to this variable (the 32 bytes that was shown in the last section). It turns out that these are stored one after the other in memory. Knowing that 32 bytes are required, it is possible to write the entire array with a single line of code
The principle to read the data is similar. The input stream is opened in binary
When the file is read with , the bytes are copied into the variable passed in argument. In the same manner as for the writing, the size read in bytes must be known.
There are once again two options to read the data: fill each element of the array one by one with a loop
and fill the array all at once
Although it is possible to save more complex data type such as structures and classes in binary, this guide don’t explain it this as it very quickly becomes complicated. A good place to start for a interested reader is (here)serialization-cpp.
Here is a simple program that writes into a binary file , reads it and output the values to the console.