

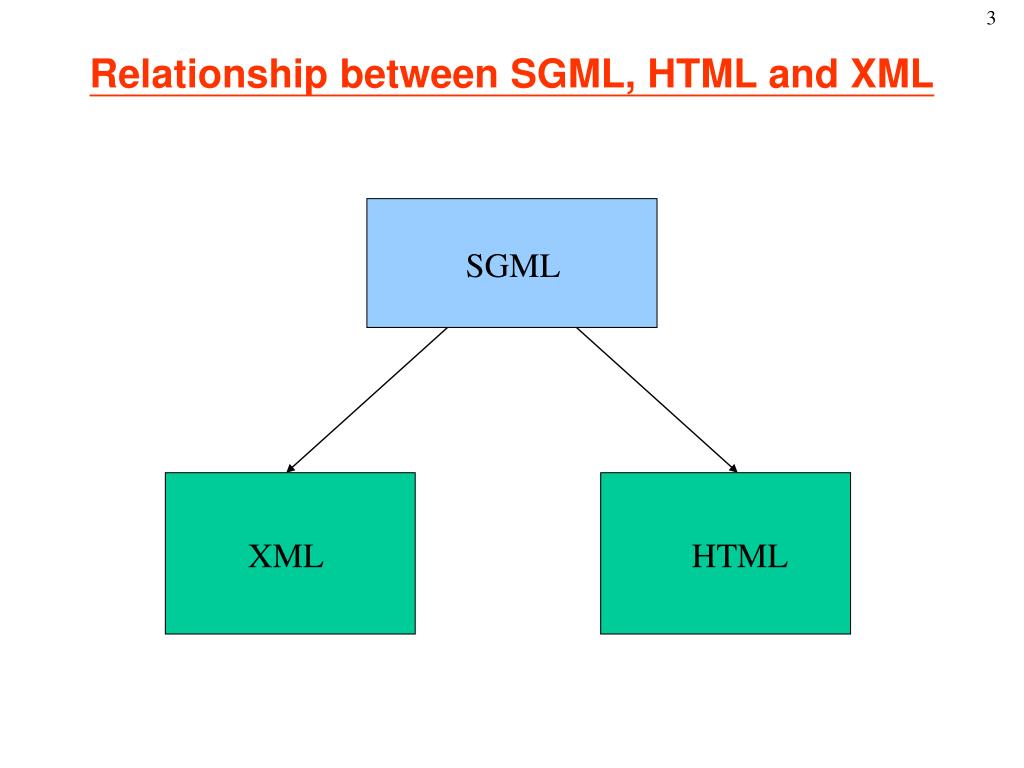
Что такое XML?
В современных информационных системах (в том числе и в сети Интернет) обмен данными и их обработка очень часто выполняются автоматически, без участия человека.
До недавнего времени для передачи данных использовались в основном двоичные форматы. Это значит, что данные представляются в том же виде, в котором они хранятся в памяти компьютера. Вспомним, что любой двоичный код — это просто последовательность битов, и невозможно сказать, что он означает — код программы, текст, рисунок или звук. Поэтому при передаче двоичных данных приёмник должен заранее знать их формат, т. е. такой подход не универсален.
Для обмена гипертекстовой информацией был разработан язык HTML. Поскольку некоторое время назад этот язык был единственным средством разработки веб-страниц, в него были включены тэги физической разметки (определяющие оформление), которые совсем не нужны для машинной обработки. Вместе с тем пользователь не может ввести в язык новые тэги, т. е. HTML непригоден для передачи произвольных данных.
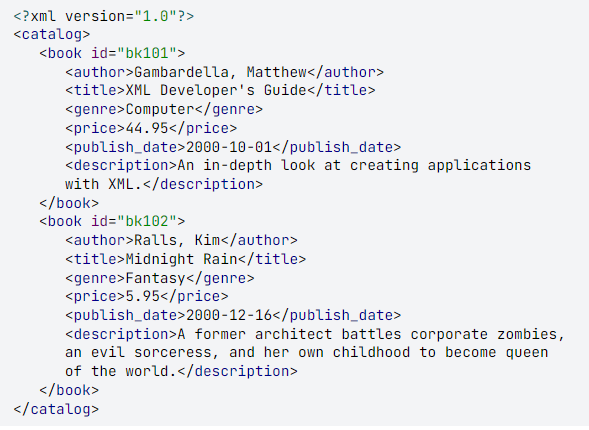
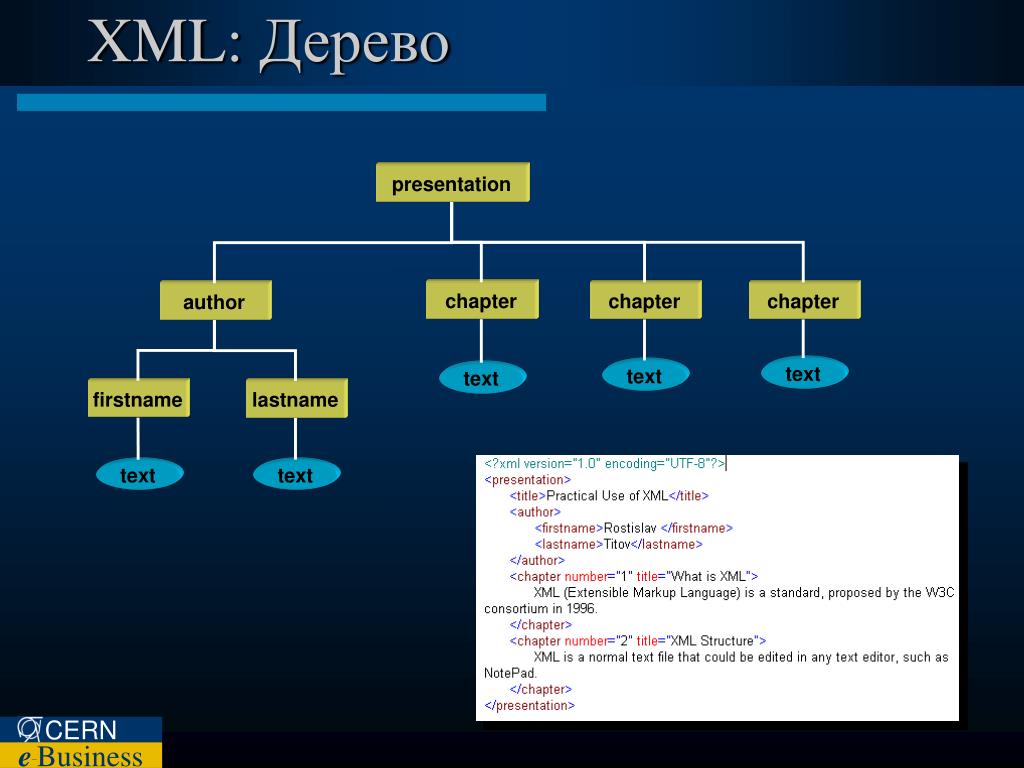
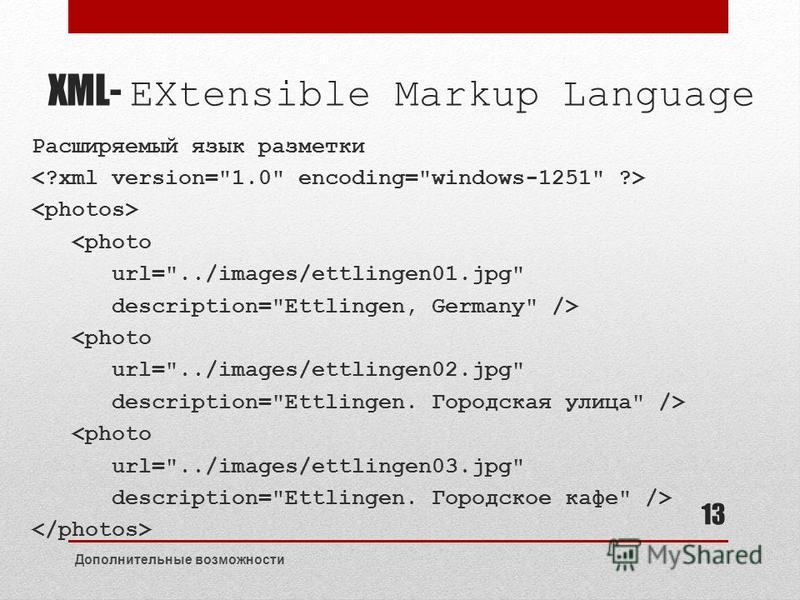
В конце XX века был предложен новый язык описания данных, который во многом снял проблему совместимости различных информационных систем. Он получил название XML (от англ. extensible Markup Language — расширяемый язык разметки). Вот пример XML-файла:
<?xml version="1.0"?> <компьютер> <процессор частота="2 ГГц">Intel Сеlеrоn</процессор> <память фирма="Kingston">2048 Мб</память> <винчестер фирма="Seagate">320 Гб</винчестер> <периферия> <Mонитop>Philips 190С1SВ</монитор> <Клавиатура>Logitech Classic 200</клавиатура> <Mышь>Genius Navigator 600</мышь> </периферия> </компьютер>
Первая строчка говорит о том, что это XML-документ версии 1.0. Оставшаяся часть очень напоминает HTML-код:• для разметки используются тэги-контейнеры в угловых скобках; закрывающий тэг начинается знаком «/»;
• в один контейнер могут быть вложены другие, это позволяет хранить данные в виде многоуровневой структуры (дерева);
• тэги могут иметь атрибуты, в которых хранятся дополнительные данные.
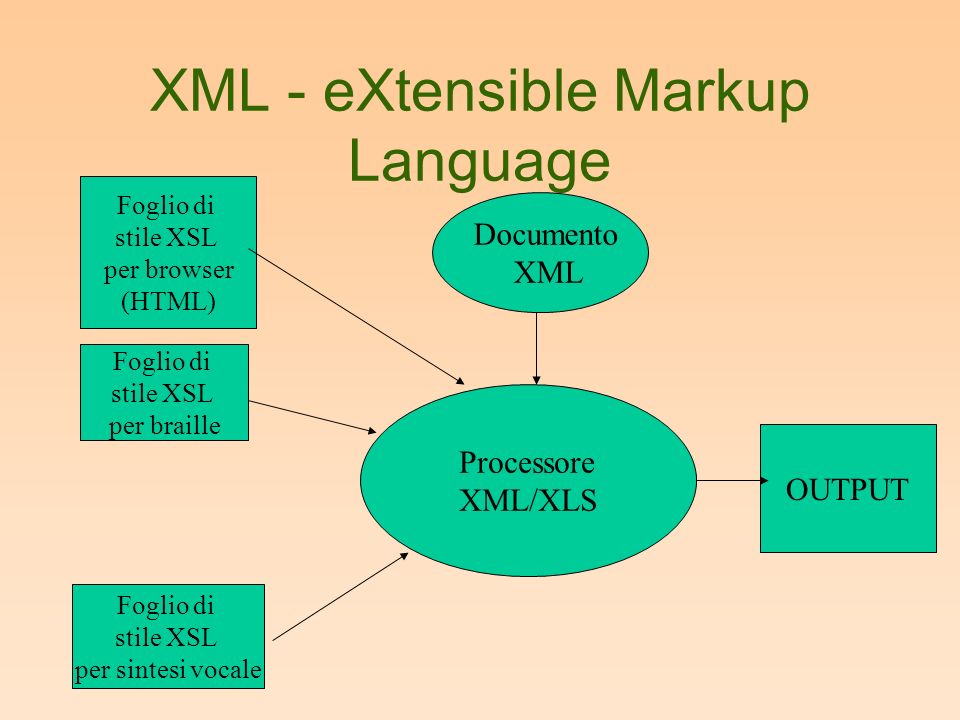
Фактически XML-файлы — это иерархические базы данных, хранящиеся в текстовом формате. В отличие от HTML здесь можно вводить свои собственные тэги и атрибуты, но никаких средств оформления нет. Для того чтобы вывести данные из XML-файла на экран в нужном виде, используют специальные стилевые таблицы, построенные с помощью языка XSL (англ. extensible Stylesheet Language — расширяемый язык таблиц стилей).
XML обладает несомненными достоинствами с точки зрения автоматизации обработки данных:• открытый текстовый формат, не зависящий от типа компьютера и операционной системы;
• построен на строгих правилах, определённых стандартами, поэтому несложно написать программу для обработки XML-файлов и проверки их правильности;
• удобен для представления многоуровневых списков и иерархических баз данных.
В то же время нужно отметить и недостатки XML:• достаточно сложно описать структуры данных, отличающиеся от иерархии, например графы;
• не различаются типы данных (число, текст, дата, время, логическое значение);
• XML-файлы избыточны, т. е. занимают в несколько раз больше места, чем те же самые данные в двоичном виде.
Сейчас язык XML широко используется в программном обеспечении. Например, последние версии офисных пакетов Microsoft Office и OpenOffice.org сохраняют документы как набор XML-файлов, упакованных в zip-архив. На XML основаны форматы RSS (ленты новостей на сайтах и в блогах), MathML (описание математических формул), SVG (векторная графика на вебстраницах).
Следующая страница Что такое XHTML?
Cкачать материалы урока
HTML или XHTML
Осуществляя выбор между этими двумя стандартами необходимо обратить внимание на следующие основные моменты:
- XHTML представляет собой текущий стандарт разметки гипертекста, заменивший HTML 4;
- является совместимым с другими продуктами на базе XML (языками, протоколами и приложениями) в отличии от HTML;
- XHTML является более последовательным, чем HTML, что способствует снижению вероятности возникновения ошибок;
- XHTML 1.0 представляет собой мост к новым версиям XHTML;
- старыми браузерами так же корректно отображается XHTML, как и HTML;
- новые браузеры охотнее работают с XHTML, поскольку им предоставляются многие функции, которые недоступны в HTML;
- XHTML хорошо работает в беспроводных устройствах, программах для чтения информации с экрана и других пользовательских устройствах, чем устраняется необходимость создания отдельных версий для беспроводных устройств и повышается доступность сайта;
- XHTML относится к семейству веб-стандартов (куда входят и CSS и W3C DOM), это дает возможность контроля внешнего вида и поведения страницы в разных платформах, браузерах и устройствах;
- использование XHTML повышает доступность сайта и способствует одинаковому отображению страниц в разных браузерах;
- при использовании XHTML можно осуществлять проверку страниц с помощью валидатора Консорциума W3C, что способствует экономии времени на тестировании и отладке и недопущению основных ошибок доступности.
Как было упомянуто выше, стандартом XHTML используются правила синтаксиса XML. Кроме того, существуют еще некоторые правила синтаксиса XHTML, отличающие его от HTML:
- необходимость наличия специальных объявлений DOCTYPE;
- использование нижнего регистра для записи всех элементов, атрибутов и значений;
- все значения атрибутов заключаются в кавычки (одинарные или двойные), но пользоваться можно только одними;
- все атрибуты должны иметь определенные значения.
Замечание 4
Эти правила не обязательные при написании кода, однако все они отлично работают в HTML.
Одно правило XHTML все же нарушает синтаксис HTML — это применение косой черты при закрытии пустых элементов.
При использовании HTML вместо XHTML необходимо учесть только эту небольшую разницу при написании страниц.
Полезные советы для скачивания xml файла.
Скачивание xml файла с веб-сайта может быть довольно простым процессом, если вы знаете, как правильно его выполнить. В этом разделе мы предоставим вам полезные советы для скачивания xml файла с сайта.
- Определите источник файла. Прежде чем начать процесс скачивания xml файла, убедитесь, что у вас есть точная ссылка на источник файла. Это может быть ссылка на веб-страницу, содержащую файл, или прямая ссылка на сам файл.
- Проверьте права доступа. Убедитесь, что вы имеете необходимые права доступа для скачивания файла с сайта. Некоторые веб-сайты могут ограничить доступ к своим файлам или требовать авторизации.
- Используйте браузер для скачивания файла. Большинство современных веб-браузеров предлагают функцию скачивания файлов. Вы можете использовать эту функцию, чтобы скачать xml файл с сайта. Просто откройте ссылку на файл в браузере и выберите опцию «Сохранить как» или «Скачать файл».
- Используйте программу для скачивания. Если браузер не предлагает опцию скачивания файла или вы хотите использовать специальную программу для скачивания, вы можете установить и использовать такую программу. Существуют множество программ для скачивания файлов, таких как DownThemAll, Internet Download Manager и другие.
- Убедитесь в целостности файла. После скачивания xml файла проверьте его целостность. Убедитесь, что файл полностью и точно соответствует ожидаемому содержимому.
Важно помнить, что скачивание xml файла с веб-сайта может нарушать авторские права или правила использования. Убедитесь, что вы имеете право скачивать и использовать файлы, прежде чем продолжить процесс
Объявления атрибутов
Объявление списка атрибутов определяет имена атрибутов, устанавливает тип для каждого атрибута и задаёт
востребованность для каждого атрибута, в частности, может задавать значение атрибута по умолчанию. Объявление
списка атрибутов имеет следующую форму записи:
<!ATTLIST Имя ОпрАтр>
Здесь «Имя» — имя элемента, для которого задаются атрибуты. «ОпрАтр» — это одно или несколько определений атрибутов.
Определение атрибута имеет следующую форму записи:
Имя ОпрАтр ОбъявУмолч
Здесь «Имя» — имя атрибута. ОпрАтр представляет собой тип атрибута. ОбъявУмолч — это объявление значения по
умолчанию, которое указывает на востребованность атрибута и содержит некоторую дополнительную информацию. Пример
объявления:
<!ATTLIST PRODUCT Retail CDATA «retail» Title CDATA #REQUIRED>
Вышеприведённое объявление означает, что вы можете присвоить атрибуту Retail любую строку в кавычках (ключевое
слово CDATA); если этот атрибут опущен, ему будет присвоено значение по умолчанию «retail». Вы можете присвоить
атрибуту Title любую строку в кавычках; этот атрибут должен быть обязательно задан для каждого элемента PRODUCT
(ключевое слово #REQUIRED) и не имеет значения по умолчанию.
Объявления атрибутов просто включаются в DTD наряду с объявлениями типов элементов, например:
…
<!ELEMENT PRODUCT (#PCDATA)>
<!ATTLIST PRODUCT Retail CDATA «retail» Title CDATA #REQUIRED>
…
Вы можете задавать тип атрибута тремя различными способами:
- Строковый тип (ключевое слово CDATA, что означает символьные данные, Character Data).
- Маркерный тип.
- Нумерованный тип.
Вот список ключевых слов, которые вы можете использовать в определении маркерных типов атрибутов:
| ID | Для каждого элемента атрибут должен иметь уникальное значение. Элемент может иметь только один атрибут типа ID. В объявлении значения по умолчанию такого атрибута должно фигурировать #REQUIRED или #IMPLIED. |
| IDREF | Значение такого атрибута является ссылкой на атрибут типа ID другого элемента . |
| IDREFS | Этот тип атрибута похож на IDREF, но его значение может включать ссылки на несколько идентификаторов — разделённых пробелами — внутри строки в кавычках. |
| ENTITY | Значение атрибута должно совпадать с именем примитива, объявленного в DTD. Такой примитив ссылается на внешний файл, обычно содержащий не XML-данные. Таким способом, например, определяют путь к файлу, содержащему графические данные (рисунок). |
| ENTITIES | Этот тип атрибута похож на ENTITY, но его значение может включать ссылки на несколько идентификаторов, разделённых пробелами — внутри строки в кавычках. Таким способом, например, определяют пути к файлам, содержащим графические данные (рисунки) в альтернативных форматах. |
| NMTOKEN | Элементарное имя. |
| NMTOKENS | Этот тип атрибута похож на NMTOKEN, но его значение может включать несколько элементарных имён, разделённых пробелами — внутри строки в кавычках.. |
Два способа, которые вы можете использовать в определении нумерованных типов атрибутов:
-
Если вы хотите ограничить значение атрибута «Mass» словами «net» и «gross», вы можете написать следующее:
<!ATTLIST PRODUCT Mass (net | gross) «net»>
-
Нумерованный тип можно определить с помощью ключевого слова NOTATION. Каждая из указанных нотаций должна точно
соответствовать имени нотации, объявленному в DTD. Нотация описывает формат данных или идентифицирует программу,
применяемую для обработки определённого формата данных:<!ATTLIST PRODUCT Description NOTATION (HTML | SGML | RTF) #REQUIRED>
Объявление значения атрибута по умолчанию может иметь четыре формы:
| #REQUIRED | Вы должны задать значение атрибута для каждого элемента. |
| #IMPLIED | Вы можете опустить атрибут, но никакое значение по умолчанию назначено не будет. |
| AttValue | Собственно значение по умолчанию. Вы можете опустить атрибут, и ему будет назначено это значение по умолчанию. |
| #FIXED AttValue | Вы можете опустить атрибут, и ему будет назначено это значение по умолчанию (AttValue). Если вы не опускаете атрибут, вы обязаны назначить ему это значение по умолчанию. При таком объявлении указывать атрибут в элементе имеет смысл только для того, чтобы сделать документ более понятным для восприятия. |
Working Groups
There is more detail about each of these Working Groups in the Activity Statement and also on the individual Working
Group public web pages.
Most Working Groups have both a public web page and another more private
one that is only accessible to W3C Members. The private page has telephone
numbers, schedules for meetings and conference calls, links to internal
editing drafts, and other administrative information.
XSLT Working Group
The XSLT Working Group is responsible for
XSL Transformations (XSLT) and a number of supporting specifications.
You can read the XSLT Working Group Public Page
and they also have a member-only page.
The Efficient XML Interchange Working Group
The Efficient XML Interchange Working
Group is responsible for developing ways to exchange XML documents in
ways that are as efficient as is practical without compromising the
interoperability of XML itself.
This Working
Group is not about producing a closed, proprietary or obfuscated
“binary XML ”—The W3C is all about increasing
interoperability!
The EXI format is a compressed stream of parse events that can use
an XML Schema to avoid having to transmit known information and to
use native type representations. The receiver of an EXI stream doesn’t
have to reconstitute the original document, but can process the parse events directly as if parsing had happened, saving CPU, memory, time and bandwidth.








You can read the Efficient XML Interchange Working Group
Public Page; there is also a member-only page.
XML Query Working Group
The XML Query Working Group is working on the XML Query Language, a way to
provide flexible query facilities and processing of forests of trees, typically
exchanged using XML or JSON.
This includes publication of XQuery and also XPath, in
conjunction with the XSLT Working Group.
You can read the XML Query Working Group Public Page
and there is also a member-only
page.
Method 4: Downloading an XML file using a command line tool
For individuals comfortable with the command line interface and seeking a powerful and customizable solution, downloading an XML file using a command line tool can be an ideal choice. Command line tools provide advanced functionalities and allow for automation and scripting. Here’s how you can download an XML file using a command line tool:
- Open your preferred command line interface, such as Terminal (for macOS and Linux) or Command Prompt (for Windows).
- Use the or command, both of which are commonly available in most operating systems, to download the XML file.
- Specify the URL of the XML file after the or command.
- Optionally, provide additional arguments or flags to modify the download behavior as needed. For example, you can use the flag followed by a filename to save the downloaded file with a specific name.
- Hit enter to execute the command, and the command line tool will begin downloading the XML file.
By utilizing command line tools like or , you have more control over the download process. These tools offer various options to customize the download behavior, such as resuming interrupted downloads, limiting download bandwidth, or specifying user credentials for authentication if required.
It’s worth noting that using command line tools may require a basic understanding of the command line interface and knowledge of the specific commands and flags available. However, once you become familiar with the commands, this method can be incredibly powerful and efficient, especially when combined with other command line tools or scripts.
Command line tools provide a flexible and robust approach to download XML files, offering a range of options to suit your specific needs and automate the process if desired.
Обзор
- XML означает расширяемый язык разметки. XML — это язык (не язык программирования), который использует разметку и может расширяться.
- Основная цель — транспортировать данные, а не отображать их.
- XML 1.1 — последняя версия. Тем не менее, XML 1.0 является наиболее используемой версией.
- Теги работают парами, за исключением объявлений.
- Открывающий тег + содержимое + закрывающий тег = элемент.
- Сущности — это способ представления специальных символов.
- DTD означает «Определение типа документа». Он определяет структуру XML-документа с использованием некоторых допустимых элементов. XML DTD не является обязательным.
- DOM означает объектную модель документа. Он определяет стандартный способ доступа к XML-документам и манипулирования ими.
- Правильно сформированные XML-документы — это XML-документы с правильным синтаксисом.
- Действительные XML-документы имеют правильный формат и соответствуют правилам DTD.
- Пространства имен помогают избежать конфликтов имен элементов.
Использование общих примитивов и нотаций
Объявление общего внутреннего разбираемого примитива имеет следующую форму записи:
<!ENTITY Имя Значение>
Здесь «Имя» есть имя примитива. Примитив может иметь такое же имя, что и другой параметрический примитив в
документе, т.к. общие и параметрические примитивы занимают различные пространства имён. Примитив также может иметь
такое же имя, что и элемент или атрибут. «Значение» есть строка, заключённая в кавычки (литерал). Строка не может
содержать символы амперсанда (&) и процентов (%). Содержимое строки должно быть корректным для места, в которое
вы предполагаете вставить примитив.
Пример:
…
<!ENTITY title
«Groceries
<SUBTITLE>Dry Produce</SUBTITLE>»
>
…
<PRODUCT>
Title: &title
<PRODUCT>
Объявление общего внешнего разбираемого примитива имеет следующую форму записи:
<!ENTITY Имя SYSTEM Литерал>
Здесь «Имя» есть имя примитива. «Литерал» есть путь к файлу, содержащему данные примитива. Вы можете вставить общий
внешний разбираемый примитив только внутрь содержимого элемента.
Объявление общего внешнего неразбираемого примитива имеет следующую форму записи:
<!ENTITY Имя SYSTEM Литерал NDATA ИмяНотации>
Здесь «Имя» есть имя примитива. «Литерал» есть путь к файлу, содержащему данные примитива. Ключевое слово NDATA
указывает, что файл примитива содержит неразбираемые данные (они не обрабатываются синтаксическим анализатором).
«ИмяНотации» есть имя нотации, объявленной в DTD.
Файл неразбираемого внешнего примитива может содержать любой тип текста или нетекстовые данные. Фактически
единственный способ использования этого типа примитива состоит в присвоении его имени атрибуту с типом ENTITY или
ENTITIES. Процессор просто делает примитив и его нотацию доступными приложению, которое может выполнять необходимые
действия с этой информацией (например, он может запустить программу, ассоциированную с нотацией, и указать ей
отобразить данные из файла примитива).
Пример:
…
<!ENTITY faun SYSTEM «Faun.gif» NDATA GIF>
…
<COVERIMAGE Source=»faun» />
Нотация описывает определённый формат данных. Это делается путём указания адреса описания формата, адреса программы,
которая может обрабатывать данные в этом формате, либо указания просто описания формата. Вы можете использовать
нотацию, чтобы описать формат общего внешнего неразбираемого примитива, либо можете присвоить нотацию атрибуту,
который имеет нумерованный тип NOTATION.
Нотация имеет следующую форму записи:
<!NOTATION Имя SYSTEM Литерал>
Здесь «Имя» есть имя нотации. «Литерал» есть строка, куда вы можете включить любое описание формата, которое
проинформирует приложение, как отображать или обрабатывать документ. Например, вы можете включить в литерал одно из
следующих описаний:
-
URL программы, которая может обрабатывать или отображать нужный формат данных:
<!NOTATION BMP SYSTEM «Pbrush.exe»>
-
URL документа, который описывает нужный формат данных:
<!NOTATION STRANGEFORMAT SYSTEM «http://StrangeFormat.com/StrangeFormat.htm»>
-
Простое описание формата:
<!NOTATION GIF SYSTEM «Graphic Interchange Format»>
Какие данные нужны для поиска информации о недвижимости в ЕГРП
Как скачать Xml из публичной кадастровой карты?
Как скачать Xml из ЕГРП?
Как скачать Xml из Росреестра кадастровая карта?
Какие данные содержит Xml файл публичной кадастровой карты?
Xml файл публичной кадастровой карты содержит данные о границах участка, его площади, категории земельного участка, наличие строений на участке и другую информацию, связанную с данным участком. Также в Xml файле могут содержаться сведения о соседних земельных участках и ограничениях, налагаемых на данный участок.
Можно ли скачать Xml файл из Росреестра бесплатно?
Политика конфиденциальности • Реклама • Согласие на обработку персональных данных • Пользовательское соглашение
Поделиться
Класснуть
Поделиться
Чтение XML-данных из URL-адреса
В этом примере используется файл с именемBooks.xml. Вы можете создать собственный файлBooks.xml или использовать пример файла, который входит в краткие руководства по пакету SDK для .NET. Этот файл также доступен для скачивания; См. первый элемент в разделе этой статьи, чтобы получить сведения о расположении скачивания.
-
Скопируйте файлBooks.xml в папку на компьютере.
-
Откройте Visual Studio.
-
Создайте консольное приложение Visual C#. Вы можете перейти к разделу или выполнить следующие действия, чтобы создать приложение.
-
Укажите директиву using для пространства имен, чтобы не требовалось указывать объявления классов позже в коде. Директиву using необходимо использовать перед любыми другими объявлениями.
-
Получите XML-поток с помощью URL-адреса. Потоки используются для обеспечения независимости от устройства; Таким образом, изменения программы не требуются, если изменяется источник потока. Объявите константу для URL-адреса. На следующем шаге вы будете использовать константу с . Добавьте следующий пример кода в процедуру main класса по умолчанию:
-
Создайте экземпляр класса и укажите URL-адрес. Как правило, используется, если требуется доступ к XML-файлу в качестве необработанных данных без затрат на модель DOM; таким образом, предоставляет более быстрый механизм чтения XML- кода. Класс имеет различные конструкторы для указания расположения XML-данных. Следующий код создает экземпляр объекта и передает КОНСТРУКТОРу URL-адрес:
-
Чтение XML-кода.
Примечание.
На этом шаге показан базовый внешний цикл, а в следующих двух шагах описывается использование этого цикла и чтение XML.
После загрузки выполняет последовательные операции чтения для перемещения между XML-данными и использует метод для получения следующей записи. Если записей больше нет, метод возвращает значение false.
-
Проверьте узлы. Для обработки XML-данных каждая запись имеет тип узла, который можно определить из свойства . Свойства и возвращают имя узла (имена элементов и атрибутов) и значение узла (текст узла) текущего узла (или записи). Перечисление определяет тип узла. В следующем примере кода отображается имя элементов и тип документа.
Примечание.
В этом примере атрибуты элемента игнорируется.
-
-
Проверьте атрибуты. Типы узлов элементов могут включать список связанных с ними узлов атрибутов. Метод последовательно перемещается по каждому атрибуту в элементе . Используйте свойство , чтобы проверить, есть ли у узла какие-либо атрибуты. Свойство возвращает количество атрибутов для текущего узла.
-
Выполните сборку и запуск проекта.







Other Resources
There are so many resources related to XML that we can’t possibly list
them all here. This is a good thing, because it means XML is a
success! In addition to a history of the development of XML at W3C, there is an
extensive index at the Cover Pages,
maintained by Robin Cover. The individual Working Group public web pages may
have links to specific resources. There are Usenet newsgroups (e.g. comp.text.xml) and public mailing lists (e.g.
xml-dev).
You could also try a search engine such as for:
- XML
conferences - books
- training
courses - online
tutorials - bibliographies
- parsers (both
proprietary and open source) - magazines
- and even movies
How to format an XML file for readability?
To format an XML file for readability, you can follow these steps:
- Indentation: Start by indenting your XML file properly. This helps in visualizing the hierarchy of the XML elements. Each level of nesting should be indented by a fixed number of spaces or tabs. For example:
1 2 3 4 5 6 7 8 9 10 11 |
<root>
<element1>
<subelement1>Text</subelement1>
<subelement2>Text</subelement2>
...
</element1>
<element2>
...
</element2>
...
</root>
|
- Line breaks: Use line breaks to make the XML file more readable. Begin a new line for each opening tag and its corresponding closing tag. For example:
1 2 3 4 5 |
<root>
<element1>
...
</element1>
</root>
|
- Self-closing tags: If an element doesn’t have any content, use the self-closing tag format. For example:
1 |
<emptyElement /> |
- Attribute alignment: Align attributes within an element. For better readability, it’s recommended to align the attributes vertically. For example:
1 2 3 4 5 6 |
<element attribute1="value1"
attribute2="value2"
...
attributeN="valueN">
...
</element>
|
- Group similar elements: If you have repeating elements, group them together to improve readability. For example:
1 2 3 4 5 6 7 8 |
<root>
<group>
<element1>Text</element1>
<element2>Text</element2>
...
</group>
...
</root>
|
- Comments: Add comments within the XML file to provide additional context or explanation. Comments in XML start with . For example:
1 2 3 4 |
<root>
<!-- This is a comment explaining the purpose of the root element -->
...
</root>
|
By following these formatting guidelines, you can make your XML file more readable and easier to understand for yourself or others who may be working with it.
Подготовка к парсингу сайтов в Excel (Google Таблице)
Для того, чтобы начать парсить сайты потребуется в первую очередь перейти в Google Sheets, что можно сделать открыв страницу:
https://www.google.com/intl/ru_ru/sheets/about/
Потребуется войти в Google Аккаунт, после чего нажать на «Создать» (+).
Теперь можно переходить к парсингу, который можно выполнить через 2 основные функции:
- IMPORTXML. Позволяет получить практически любые данные с сайта, включая цены, наименования, картинки и многое другое;
- IMPORTHTML. Позволяет получить данные из таблиц и списков.
Однако, все эти методы работают на основе ссылок на страницы, если таблицы с URL-адресами нет, то можно ускорить этот сбор через карту сайта (Sitemap). Для этого добавляем к домену сайта конструкцию «/robots.txt». Например, «seopulses.ru/robots.txt».
Здесь открываем URL с картой сайта:
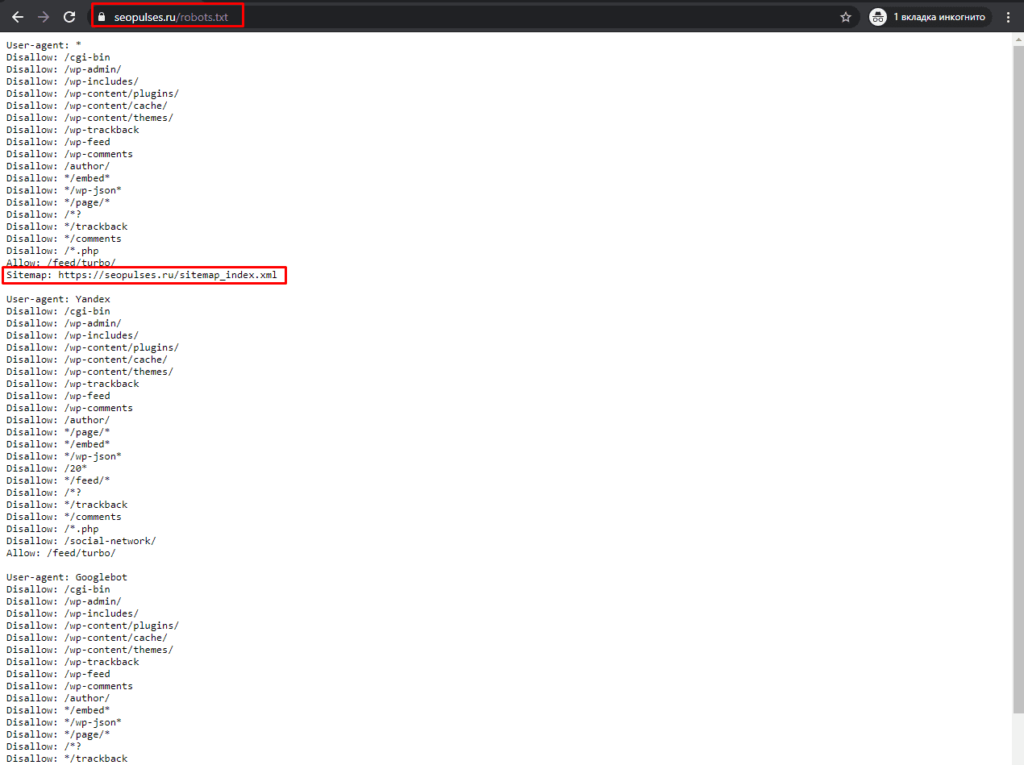
Нас интересует список постов, поэтому открываем первую ссылку.
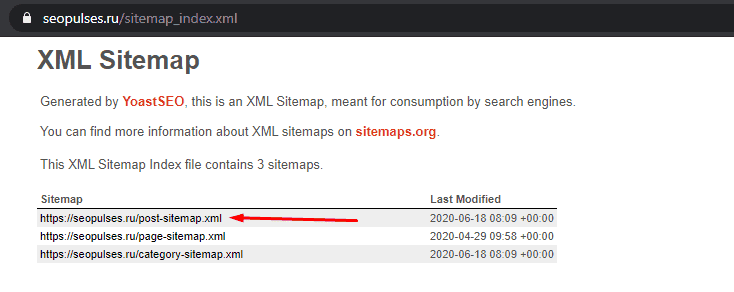
Получаем полный список из URL-адресов, который можно сохранить, кликнув правой кнопкой мыши и нажав на «Сохранить как» (в Google Chrome).
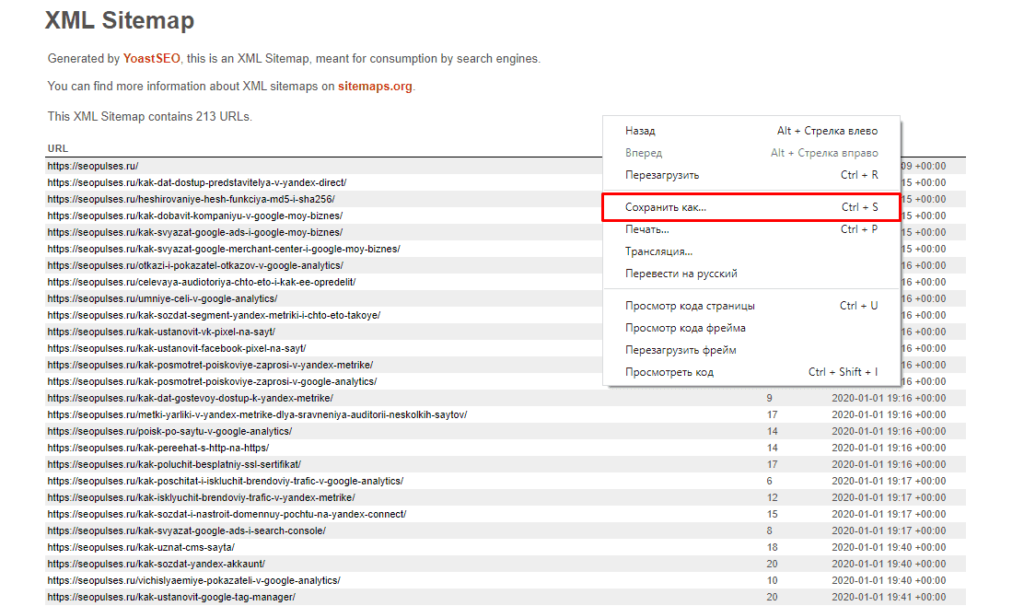
Теперь на компьютере сохранен файл XML, который можно открыть через текстовые редакторы, например, Sublime Text или NotePad++.
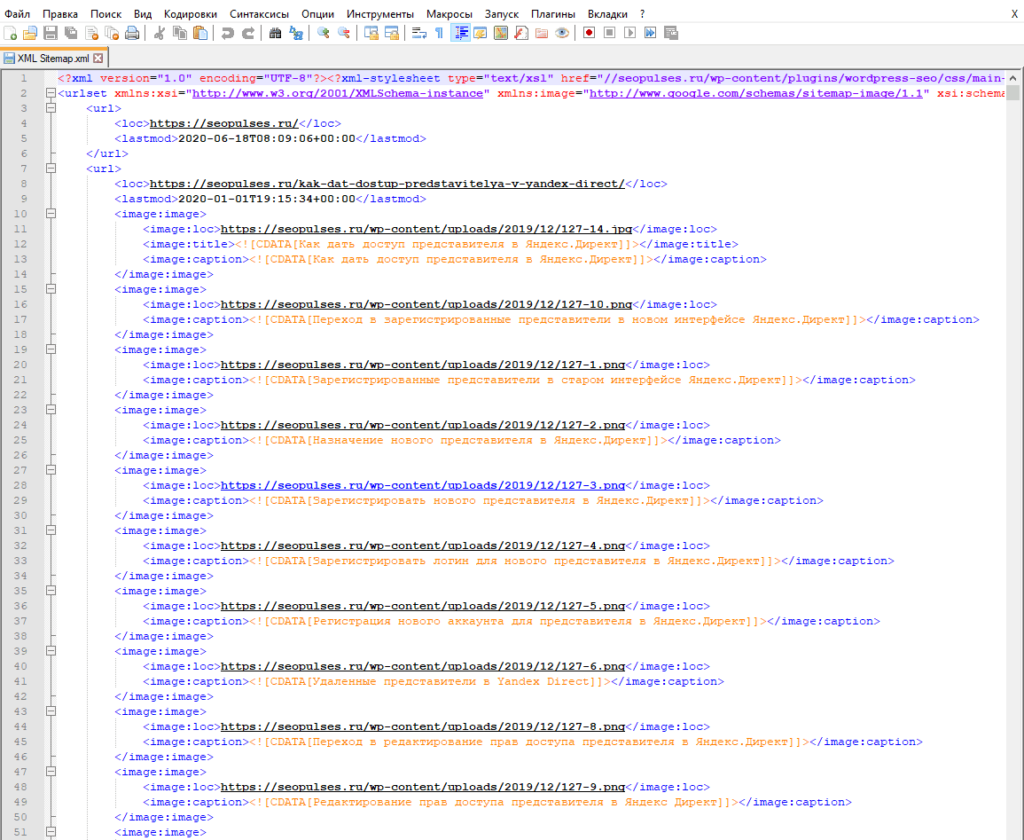
Чтобы обработать информацию корректно следует ознакомиться с инструкцией открытия XML-файлов в Excel (или создания), после чего данные будут поданы в формате таблицы.
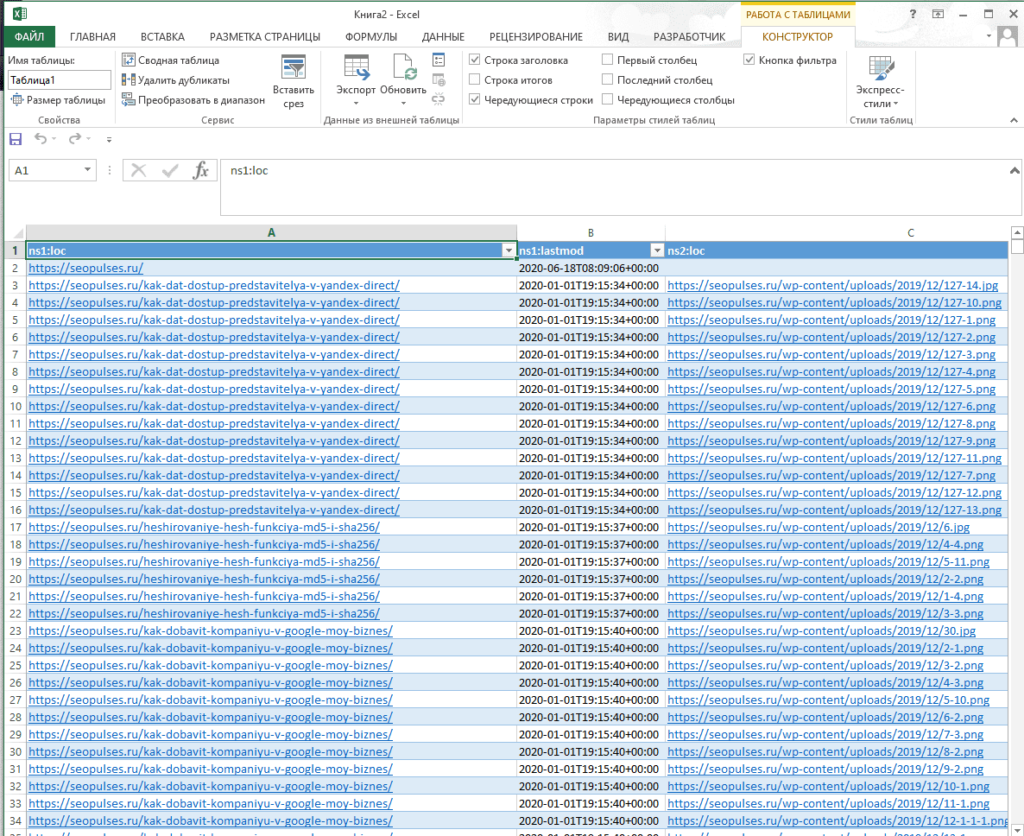
Все готово, можно переходить к методам парсинга.
Проверка и сохранение файла
После успешной загрузки xml файла с веб-сайта, необходимо проверить его на наличие ошибок и сохранить на локальный компьютер для последующего использования. Ниже представлены несколько шагов, которые помогут вам выполнить эти действия.
1. Проверка файла на наличие ошибок
Перед тем как сохранить скачанный файл, рекомендуется выполнить проверку на наличие возможных ошибок. Для этого существует специальные инструменты, позволяющие анализировать структуру xml файла и выявлять потенциальные проблемы.
Одним из таких инструментов является онлайн-валидатор xml, который позволяет проверить файл на соответствие стандарту XML и выявить возможные ошибки синтаксиса. Просто загрузите файл на соответствующую площадку и дождитесь результатов проверки.
2. Сохранение файла на компьютер
После того как файл проверен и не содержит ошибок, его можно сохранить на локальный компьютер. Для этого выполните следующие действия:
- Нажмите правой кнопкой мыши на ссылке скачивания файла на сайте.
- Выберите опцию «Сохранить ссылку как» или аналогичную (название может отличаться в зависимости от браузера).
- Укажите путь к папке, в которую вы хотите сохранить файл.
- Нажмите кнопку «Сохранить».
После выполнения этих действий, выбранный xml файл будет сохранен на вашем компьютере и готов к использованию.
Не забывайте, что некоторые веб-сайты могут ограничивать или запрещать скачивание файлов. В таком случае, вам может потребоваться обратиться к администрации сайта или выполнить дополнительные действия для получения необходимого файла.
3. Использование сохраненного файла
После сохранения файла на компьютер, вы можете использовать его для различных целей. XML файлы часто используются для обмена данными между различными программами или для импорта данных в базы данных.
Для работы с xml файлами существуют различные программы и инструменты. Некоторые текстовые редакторы, такие как Notepad++ или Sublime Text, имеют встроенную поддержку xml формата, что позволяет легко просматривать и редактировать содержимое файлов.
Также существуют специализированные приложения и программы для работы с xml файлами, такие как XMLSpy или Altova XML Editor. Эти программы позволяют производить сложные манипуляции с xml данными, включая преобразования и валидацию.







В заключение, для проверки и сохранения xml файлов необходимо выполнить следующие действия: проверить файл на наличие ошибок с помощью специальных инструментов, сохранить файл на компьютере, а затем использовать его с помощью соответствующих программ и инструментов.
Использование внешних DTD
Вы можете поместить все или часть объявлений DTD документа в отдельный файл, а затем ссылаться на этот файл из
объявления типа документа. DTD, или часть DTD, содержащаяся в отдельном файле, называется внешним подмножеством DTD.
Применение внешнего подмножества DTD имеет смысл для DTD, которые являются общими для группы документов.
Ссылка на внешний DTD выглядит следующим образом:
<!DOCTYPE PRODUCTS SYSTEM «Products.dtd»
>
Файл, содержащий внешнее подмножество DTD, может включать любые объявления разметки, которые могут быть включены во
внутреннее подмножество DTD. Например, содержимое файла «Products.dtd» может выглядеть так:
<!ELEMENT PRODUCT ANY>
XML-процессор осуществляет слияние внутреннего и внешнего подмножества DTD. Если одно и то же объявление встречается
более одного раза, XML-процессор использует первое объявление и игнорирует все последующие. Внутреннее подмножество
DTD имеет приоритет перед внешним (т.е. внешнее подмножество DTD всегда обрабатывается после того, как полностью
будет обработано подмножество внутреннего DTD). Такой способ объединения DTD даёт вам возможность адаптировать (или
субклассировать) DTD для конкретного документа.
Вы можете заставить XML-процессор игнорировать часть внешнего DTD с помощью раздела IGNORE. Такой приём подобен
«комментированию» фрагмента кода:
<!ELEMENT PRODUCT ANY>
<!]>
Если вы хотите временно восстановить блок разметки в разделе IGNORE, достаточно просто заменить ключевое слово
IGNORE на INCLUDE, не удаляя при этом символы-ограничители разметки, чтобы потом можно было быстро опять
«закомментировать» код.
Примечание: разделы IGNORE и INCLUDE можно использовать только во внешнем DTD.
Переключатель ссылки (или просто Switcher)
Все дело в том, что гугл кэширует результаты выполнения importxml и обновляет их по одним гуглу известным алгоритмам. Я перерыл тонны вариантов решения этой проблемы где только можно и нельзя и самым «изящным» и приемлемым стал следующий: при обновлении ссылки (как аргумента importxml) гугл воспринимает ее как новую и заново перевыполняет функцию importxml.
То есть мне надо обновлять первый аргумент функции, при неизменном втором — xpath. Вот тут в действие и вступает так называемый «свитчер».

Это «условный» переключатель, который будет меняться с 1 на 0 скриптом.

Что все это значит? Написанный далее скрипт будет менять значение ячейки B1 c единицы на ноль (и обратно) и далее в зависимости от значения ячейки «свитчера» (1 или 0), будет меняться ссылка в importxml.
Чтобы она менялась на новую, но вела на тот же сайт за теми же значениями, я добавляю несуществующий параметр сайта
Цели XHTML
Ограничения HTML связывают со специфичностью его словаря, перекочевавшего в XHTML. XML представляет собой язык семантический. В HTML используются специальные теги при достижении заданной цели. В XML теги используются специфичные для всех тем в отдельности, эти теги полностью создаются авторами.
XHTML представляет собой своеобразный мост, соединяющий ограничения специфического словаря и более открытую спецификацию, в которой автор создает свои собственные DTD и может в случае необходимости изменить язык.
Особыми целями XHTML являются:
- ужесточенные правила создания веб-документов;
- предоставление веб-разработчикам расширяемости;
- поддержка большого количества постоянно появляющихся альтернативных устройств (телевизионных приставок, карманных компьютеров, пейджеров и др.), воспринимающих веб-информацию.
Замечание 2
Отметим, что XHTML поддерживает любой браузер, способный к интерпретации HTML, так как XHTML работает с HTML-словарем.
Основное отличие заключается в жестких правилах, в том, каким образом написан язык и насколько строго соблюдены данные правила.