
Другие варианты
Помимо кодировки Windows-1251, для представления русского языка в текстовом формате существуют и другие кодировки. Некоторые из них нашли широкое применение и получили соответствующие названия, такие как KOI8-R или UTF-8.
Критерии выбора кодировки зависят от внешних факторов и содержания данных, с которыми мы сталкиваемся. Некоторые символы русского алфавита встречаются достаточно редко, поэтому для их представления можно использовать кодировки, которые использовали меньше 8 битных символов.
Среди наиболее часто используемых кодировок для русского языка можно назвать такие, как UTF-8, KOI8-R и ISO 8859-5 (Cyrillic).
Особенности каждой кодировки зависят от ее конкретной реализации. Например, кодировка UTF-8 может представлять символы с помощью переменного числа байтов, а кодировка KOI8-R использует фиксированное число байтов для каждого символа.
Для сравнения разных кодировок можно использовать таблицы, которые можно найти в справочниках или посмотреть в онлайн-шпаргалках.
Ссылки:
- Справочник по кодировкам: https://www.onlinedeveloper.com/codepages/cp1251.htm
- Онлайн-шпаргалка по кодировкам: https://www.encodingpedia.com/
Независимо от выбранной кодировки, важно учитывать проблемы, с которыми мы можем столкнуться при работе с текстом на русском языке. Одна из таких проблем — это ошибки при автоопределении кодировки, особенно в случае отсутствия явного указания кодировки в данных
Также возможны ситуации, когда определенный текст может быть некорректно отображен из-за неправильного выбора кодировки.
Кодировка Windows-1251 была долгое время неотъемлемой частью системы Windows, являясь ее стандартной кодировкой для работы с текстом на русском языке. Однако, с появлением Unicode и более современных кодировок, таких как UTF-8, использование Windows-1251 стало менее распространенным.
Но несмотря на это, кодировка Windows-1251 все еще используется в некоторых системах и программах. Кроме того, есть ситуации, когда нам приходится иметь дело с текстом, который сохранен в кодировке Windows-1251, например, в старых базах данных или файловых форматах.
Если вы столкнулись с ошибкой автоопределения кодировки или вам необходимо работать с текстом, сохраненным в кодировке Windows-1251, вам придется использовать специальные инструменты или процедуры для преобразования текста в другую кодировку.
Таким образом, существуют и другие кодировки, являющиеся альтернативами кодировки Windows-1251. Каждая из этих кодировок имеет свои преимущества и особенности, и выбор конкретной кодировки зависит от задачи, с которой мы сталкиваемся.
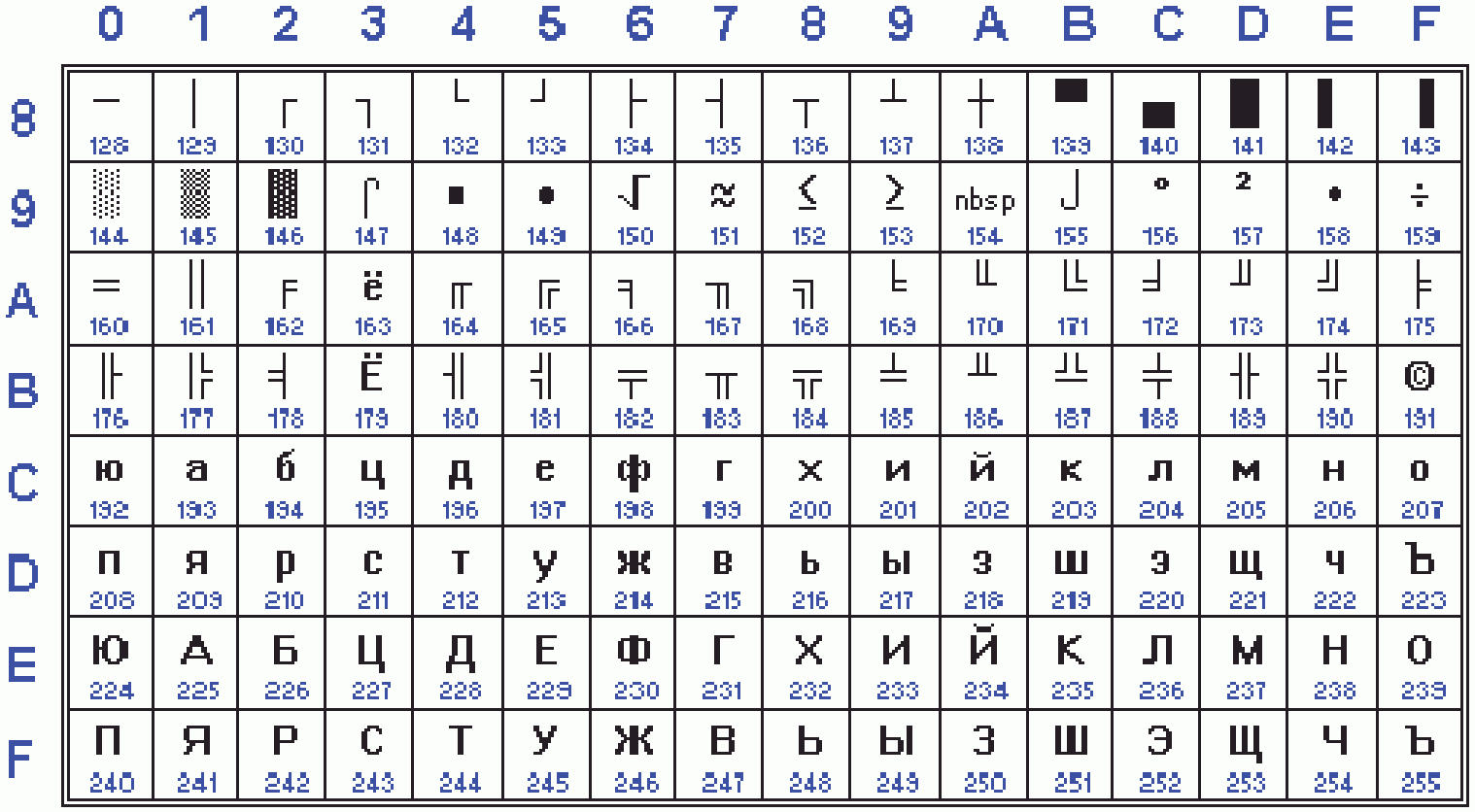
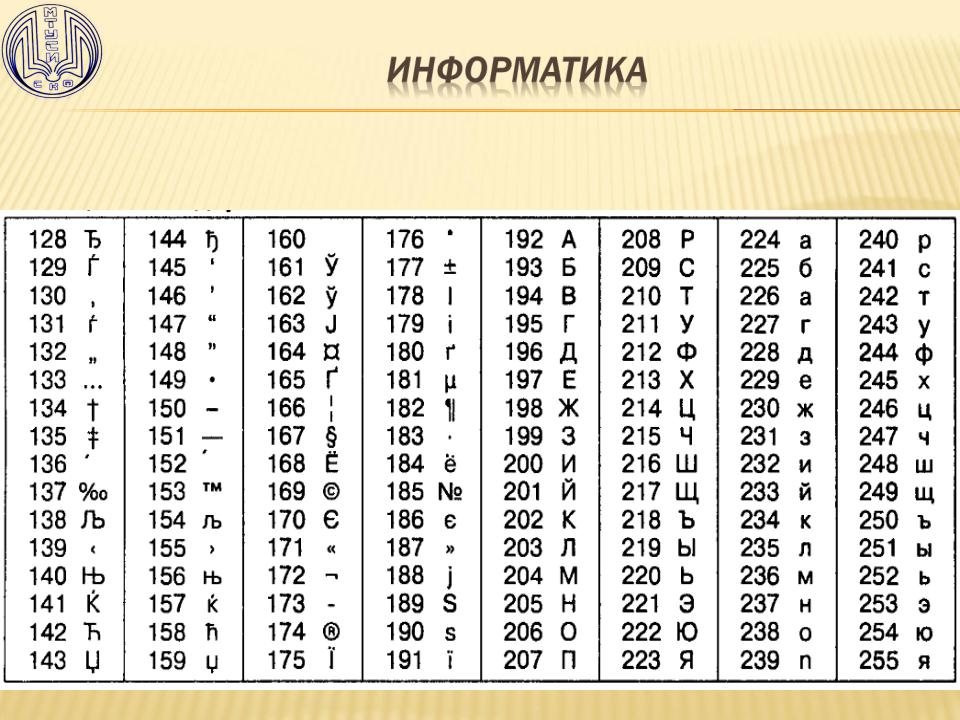
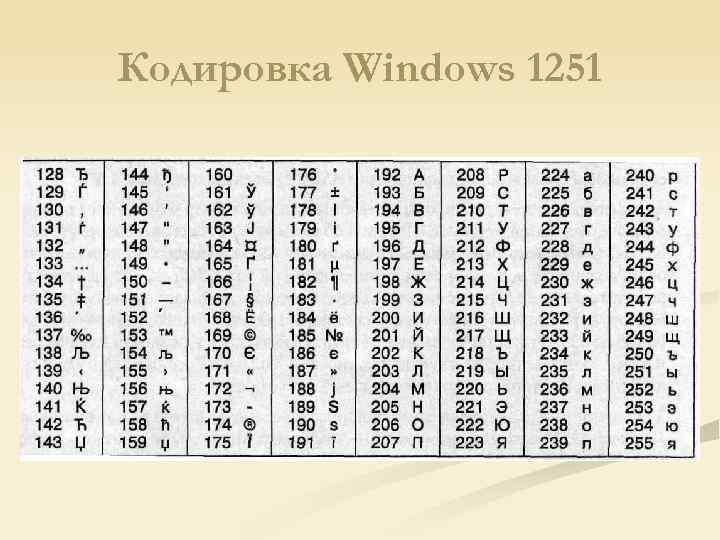
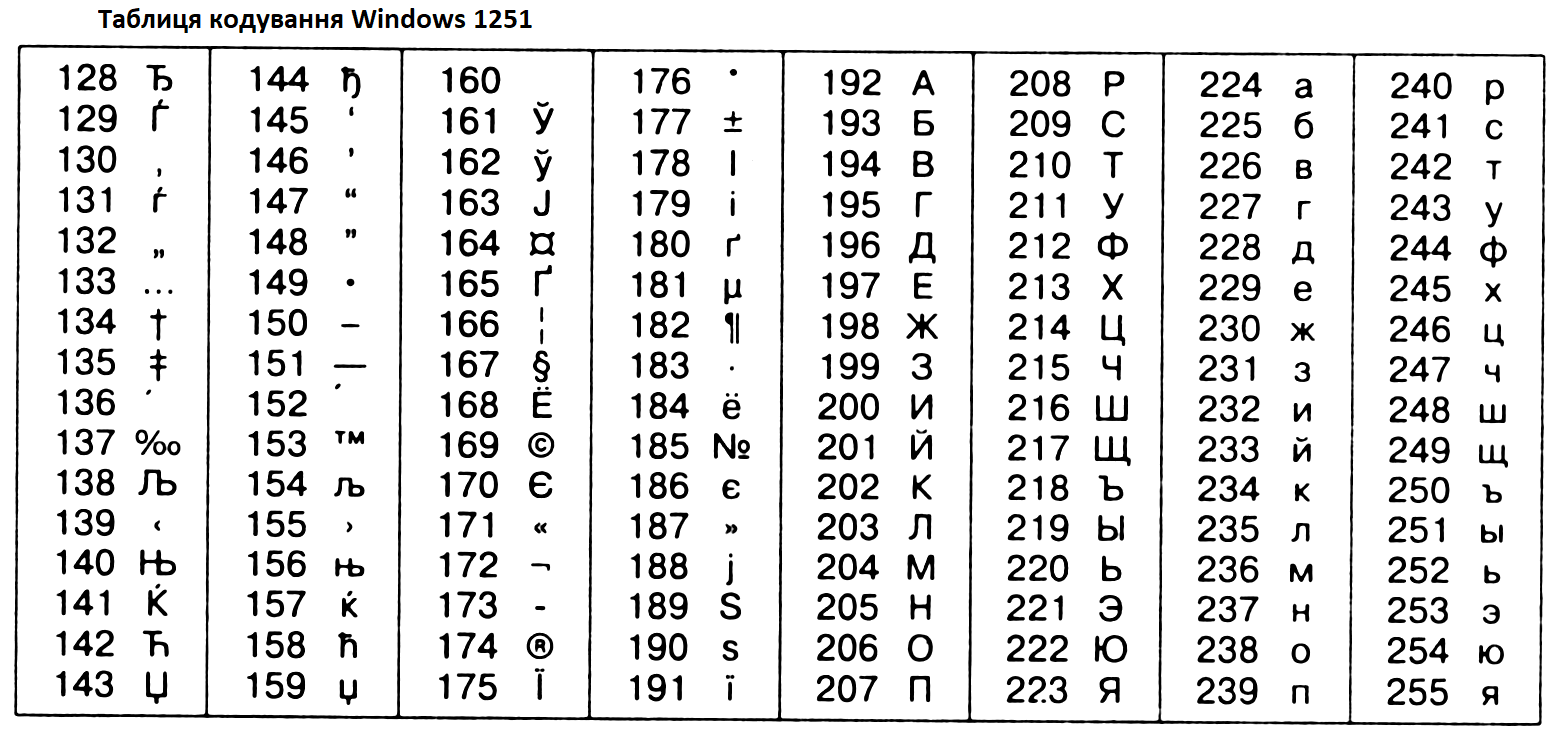
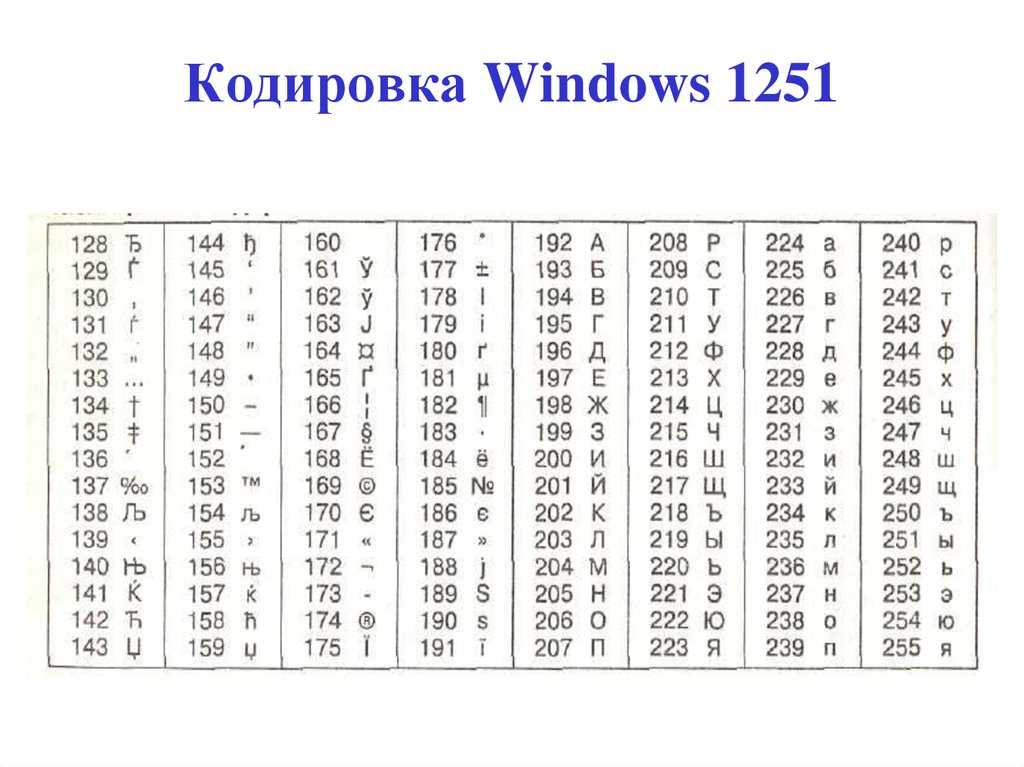
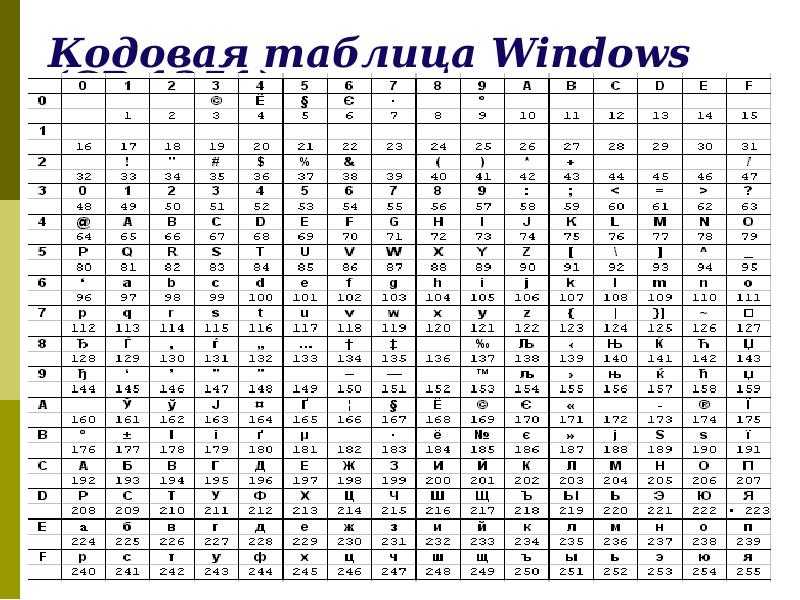
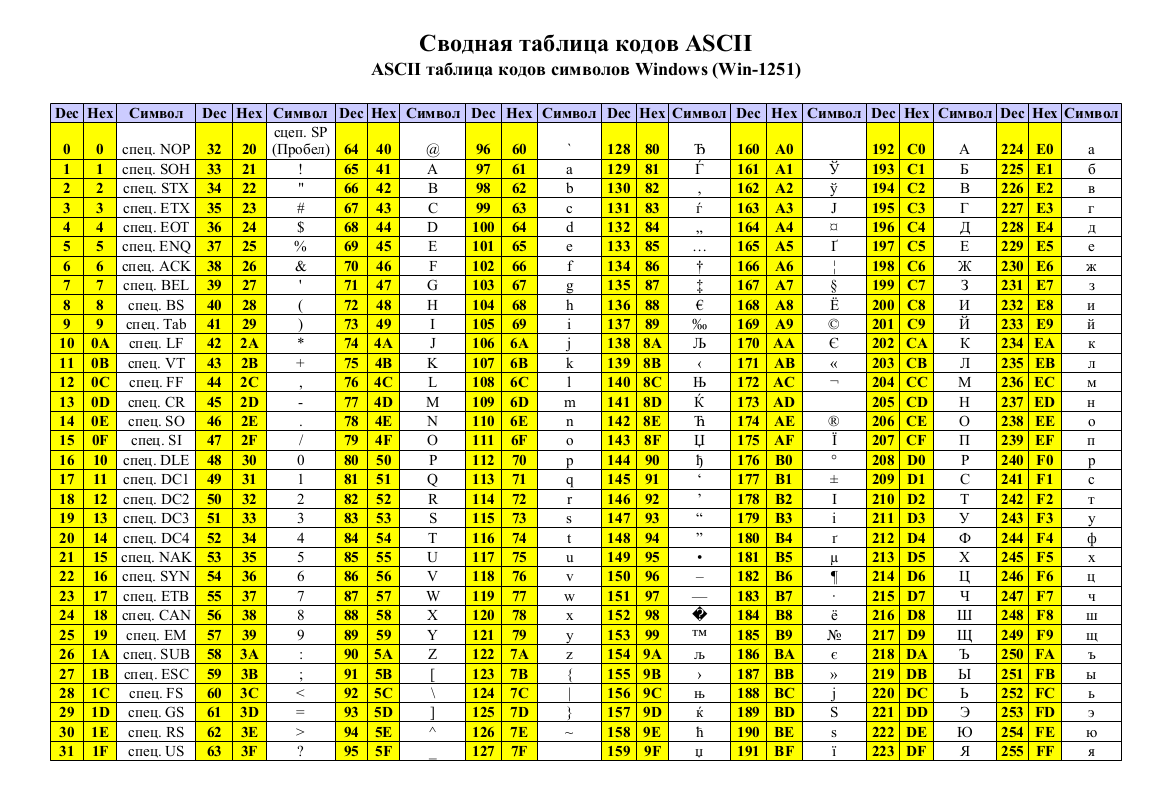
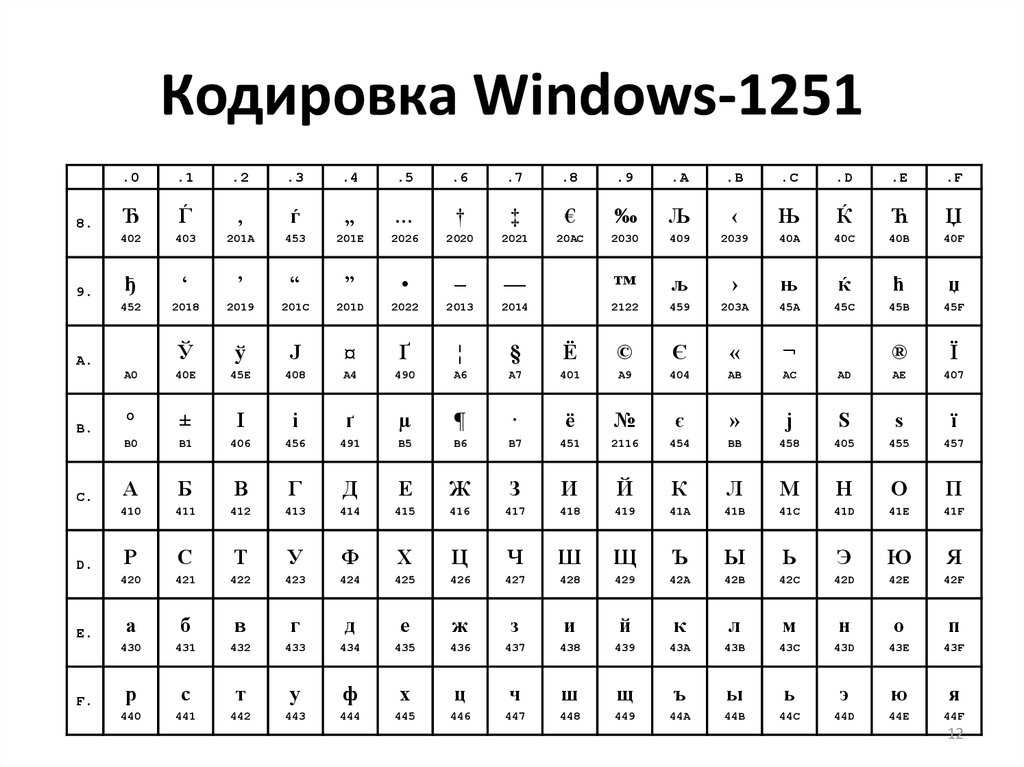
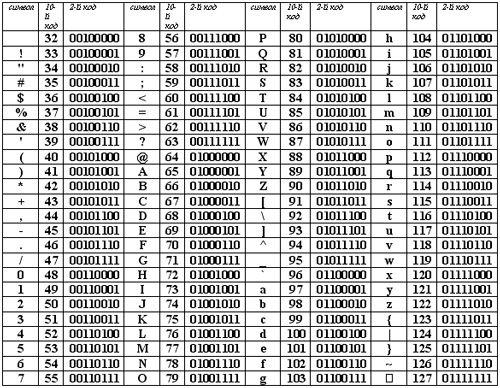
Таблица кодов символов Windows-1251
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Данная кодировка пользуется довольно большой популярностью в восточно-европейских странах.
Windows-1251 выгодно отличается от других 8-битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в традиционной русской типографике для обычного текста (отсутствует только знак ударения). Кириллические символы идут в алфавитном порядке.
Windows-1251 также содержит все символы для близких к русскому языку языков: белорусского, украинского, сербского, македонского и болгарского.
На практике этого оказалось достаточно, чтобы кодировка Windows-1251 закрепилась в интернете вплоть до распространения UTF-8.
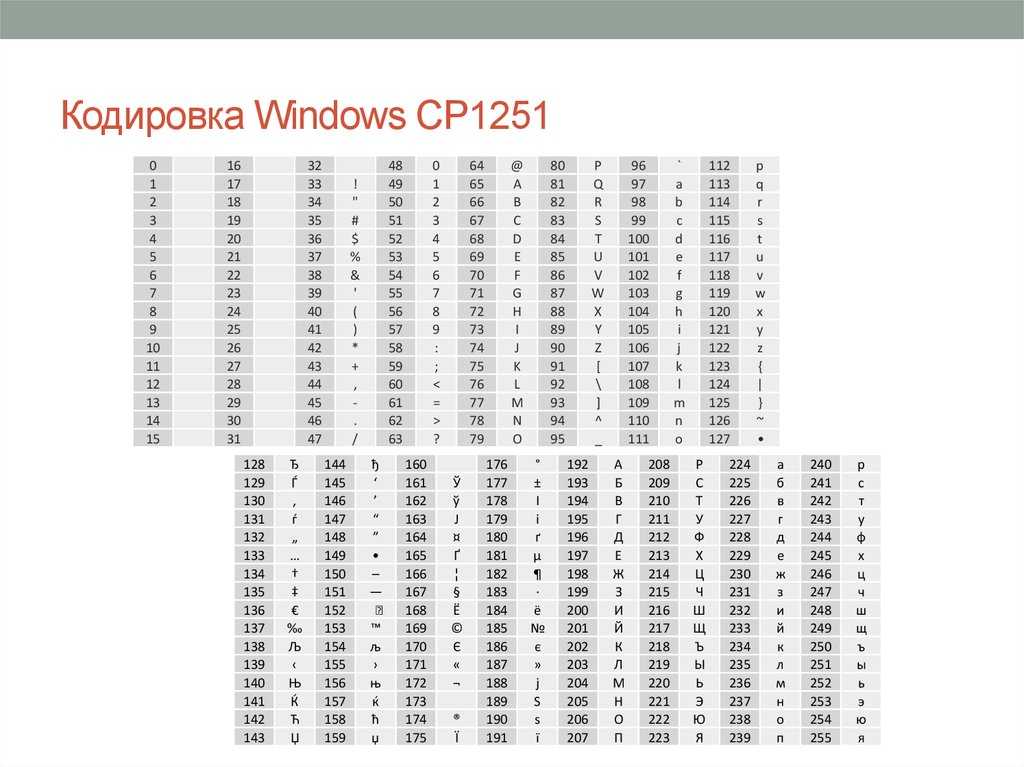
| 000 | 00 | NOP | 128 | 80 | Ђ |
| 001 | 01 | SOH | 129 | 81 | Ѓ |
| 002 | 02 | STX | 130 | 82 | ‚ |
| 003 | 03 | ETX | 131 | 83 | ѓ |
| 004 | 04 | EOT | 132 | 84 | „ |
| 005 | 05 | ENQ | 133 | 85 | … |
| 006 | 06 | ACK | 134 | 86 | † |
| 007 | 07 | BEL | 135 | 87 | ‡ |
| 008 | 08 | BS | 136 | 88 | € |
| 009 | 09 | TAB | 137 | 89 | ‰ |
| 010 | 0A | LF | 138 | 8A | Љ |
| 011 | 0B | VT | 139 | 8B | ‹ |
| 012 | 0C | FF | 140 | 8C | Њ |
| 013 | 0D | CR | 141 | 8D | Ќ |
| 014 | 0E | SO | 142 | 8E | Ћ |
| 015 | 0F | SI | 143 | 8F | Џ |
| 016 | 10 | DLE | 144 | 90 | ђ |
| 017 | 11 | DC1 | 145 | 91 | ‘ |
| 018 | 12 | DC2 | 146 | 92 | ’ |
| 019 | 13 | DC3 | 147 | 93 | “ |
| 020 | 14 | DC4 | 148 | 94 | ” |
| 021 | 15 | NAK | 149 | 95 | • |
| 022 | 16 | SYN | 150 | 96 | – |
| 023 | 17 | ETB | 151 | 97 | — |
| 024 | 18 | CAN | 152 | 98 | |
| 025 | 19 | EM | 153 | 99 | |
| 026 | 1A | SUB | 154 | 9A | љ |
| 027 | 1B | ESC | 155 | 9B | › |
| 028 | 1C | FS | 156 | 9C | њ |
| 029 | 1D | GS | 157 | 9D | ќ |
| 030 | 1E | RS | 158 | 9E | ћ |
| 031 | 1F | US | 159 | 9F | џ |
| 032 | 20 | SP | 160 | A0 | |
| 033 | 21 | ! | 161 | A1 | Ў |
| 034 | 22 | “ | 162 | A2 | ў |
| 035 | 23 | # | 163 | A3 | Ћ |
| 036 | 24 | $ | 164 | A4 | ¤ |
| 037 | 25 | % | 165 | A5 | Ґ |
| 038 | 26 | & | 166 | A6 | ¦ |
| 039 | 27 | ‘ | 167 | A7 | § |
| 040 | 28 | ( | 168 | A8 | Ё |
| 041 | 29 | ) | 169 | A9 | |
| 042 | 2A | * | 170 | AA | Є |
| 043 | 2B | + | 171 | AB | |
| 044 | 2C | , | 172 | AC | ¬ |
| 045 | 2D | – | 173 | AD | |
| 046 | 2E | . | 174 | AE | |
| 047 | 2F | 175 | AF | Ї | |
| 048 | 30 | 176 | B0 | ° | |
| 049 | 31 | 1 | 177 | B1 | ± |
| 050 | 32 | 2 | 178 | B2 | І |
| 051 | 33 | 3 | 179 | B3 | і |
| 052 | 34 | 4 | 180 | B4 | ґ |
| 053 | 35 | 5 | 181 | B5 | µ |
| 054 | 36 | 6 | 182 | B6 | ¶ |
| 055 | 37 | 7 | 183 | B7 | · |
| 056 | 38 | 8 | 184 | B8 | ё |
| 057 | 39 | 9 | 185 | B9 | № |
| 058 | 3A | 186 | BA | є | |
| 059 | 3B | ; | 187 | BB | |
| 060 | 3C | 190 | BE | ѕ | |
| 063 | 3F | ? | 191 | BF | ї |
| 064 | 40 | @ | 192 | C0 | А |
| 065 | 41 | A | 193 | C1 | Б |
| 066 | 42 | B | 194 | C2 | В |
| 067 | 43 | C | 195 | C3 | Г |
| 068 | 44 | D | 196 | C4 | Д |
| 069 | 45 | E | 197 | C5 | Е |
| 070 | 46 | F | 198 | C6 | Ж |
| 071 | 47 | G | 199 | C7 | З |
| 072 | 48 | H | 200 | C8 | И |
| 073 | 49 | I | 201 | C9 | Й |
| 074 | 4A | J | 202 | CA | К |
| 075 | 4B | K | 203 | CB | Л |
| 076 | 4C | L | 204 | CC | М |
| 077 | 4D | M | 205 | CD | Н |
| 078 | 4E | N | 206 | CE | О |
| 079 | 4F | O | 207 | CF | П |
| 080 | 50 | P | 208 | D0 | Р |
| 081 | 51 | Q | 209 | D1 | С |
| 082 | 52 | R | 210 | D2 | Т |
| 083 | 53 | S | 211 | D3 | У |
| 084 | 54 | T | 212 | D4 | Ф |
| 085 | 55 | U | 213 | D5 | Х |
| 086 | 56 | V | 214 | D6 | Ц |
| 087 | 57 | W | 215 | D7 | Ч |
| 088 | 58 | X | 216 | D8 | Ш |
| 089 | 59 | Y | 217 | D9 | Щ |
| 090 | 5A | Z | 218 | DA | Ъ |
| 091 | 5B | 219 | DB | Ы | |
| 092 | 5C | 220 | DC | Ь | |
| 093 | 5D | 221 | DD | Э | |
| 094 | 5E | 222 | DE | Ю | |
| 095 | 5F | _ | 223 | DF | Я |
| 096 | 60 | ` | 224 | E0 | а |
| 097 | 61 | a | 225 | E1 | б |
| 098 | 62 | b | 226 | E2 | в |
| 099 | 63 | c | 227 | E3 | г |
| 100 | 64 | d | 228 | E4 | д |
| 101 | 65 | e | 229 | E5 | е |
| 102 | 66 | f | 230 | E6 | ж |
| 103 | 67 | g | 231 | E7 | з |
| 104 | 68 | h | 232 | E8 | и |
| 105 | 69 | i | 233 | E9 | й |
| 106 | 6A | j | 234 | EA | к |
| 107 | 6B | k | 235 | EB | л |
| 108 | 6C | l | 236 | EC | м |
| 109 | 6D | m | 237 | ED | н |
| 110 | 6E | n | 238 | EE | о |
| 111 | 6F | o | 239 | EF | п |
| 112 | 70 | p | 240 | F0 | р |
| 113 | 71 | q | 241 | F1 | с |
| 114 | 72 | r | 242 | F2 | т |
| 115 | 73 | s | 243 | F3 | у |
| 116 | 74 | t | 244 | F4 | ф |
| 117 | 75 | u | 245 | F5 | х |
| 118 | 76 | v | 246 | F6 | ц |
| 119 | 77 | w | 247 | F7 | ч |
| 120 | 78 | x | 248 | F8 | ш |
| 121 | 79 | y | 249 | F9 | щ |
| 122 | 7A | z | 250 | FA | ъ |
| 123 | 7B | { | 251 | FB | ы |
| 124 | 7C | | | 252 | FC | ь |
| 125 | 7D | } | 253 | FD | э |
| 126 | 7E | ~ | 254 | FE | ю |
| 127 | 7F | DEL | 255 | FF | я |
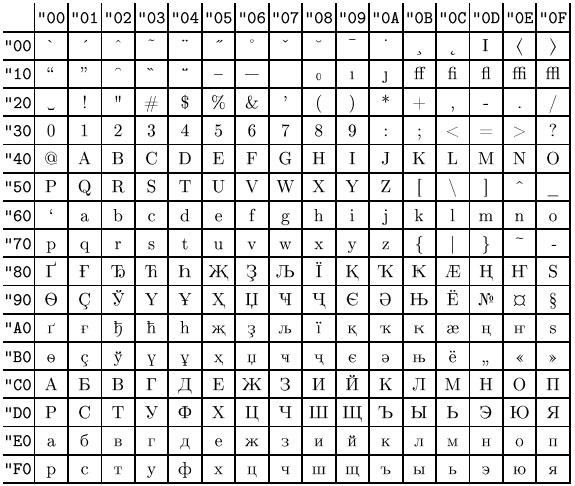
Описание специальных (управляющих) символов
Первоначально управляющие символы таблицы ASCII (диапазон 00-31, плюс 127) были разработаны для того, чтобы управлять устройствами аппаратных средств, таких как телетайп, ввод данных на перфоленту и др.Управляющие символы (кроме горизонтальной табуляции, перевода строки и возврата каретки) не используются в HTML-документах.
КодОписание
NUL, 00 NULL, пустой SOH, 01 Start Of Heading, начало заголовка STX, 02 Start of TeXt, начало текста ETX, 03 End of TeXt, конец текста EOT, 04 End of Transmission, конец передачи ENQ, 05 Enquire. Прошу подтверждения ACK, 06 Acknowledgement. Подтверждаю BEL, 07 Bell, звонок BS, 08 Backspace, возврат на один символ назад TAB, 09 Tab, горизонтальная табуляция LF, 0A Line Feed, перевод строкиСейчас в большинстве языков программирования обозначается как
VT, 0B Vertical Tab, вертикальная табуляция FF, 0C Form Feed, прогон страницы, новая страница CR, 0D Carriage Return, возврат кареткиСейчас в большинстве языков программирования обозначается как
SO, 0E Shift Out, изменить цвет красящей ленты в печатающем устройстве SI, 0F Shift In, вернуть цвет красящей ленты в печатающем устройстве обратно DLE, 10 Data Link Escape, переключение канала на передачу данных DC1, 11 DC2, 12DC3, 13DC4, 14 Device Control, символы управления устройствами NAK, 15 Negative Acknowledgment, не подтверждаю SYN, 16 Synchronization. Символ синхронизации ETB, 17 End of Text Block, конец текстового блока CAN, 18 Cancel, отмена переданного ранее EM, 19 End of Medium, конец носителя данных SUB, 1A Substitute, подставить. Ставится на месте символа, значение которого было потеряно или испорчено при передаче ESC, 1B Escape Управляющая последовательность FS, 1C File Separator, разделитель файлов GS, 1D Group Separator, разделитель групп RS, 1E Record Separator, разделитель записей US, 1F Unit Separator, разделитель юнитов DEL, 7F Delete, стереть последний символ.
Распространенные причины проблемы с кодировкойCommon causes of encoding issues
Проблемы с кодировкой возникают, если кодировка VS Code в целом или вашего файла скрипта не совпадает с кодировкой, ожидаемой в PowerShell.Encoding problems occur when the encoding of VS Code or your script file does not match the expected encoding of PowerShell. В PowerShell нет способа автоматически определить кодировку файла.There is no way for PowerShell to automatically determine the file encoding.
Проблемы с кодировкой более вероятны при использовании символов не из 7-разрядной кодировки ASCII.You’re more likely to have encoding problems when you’re using characters not in the 7-bit ASCII character set. Пример:For example:
- Расширенные небуквенные символы, такие как длинное тире (), неразрывный пробел () или левая двойная кавычка ().Extended non-letter characters like em-dash (), non-breaking space () or left double quotation mark ()
- Латинские символы с диакритикой (, )Accented latin characters (, )
- Нелатинские символы, такие как кириллица (, )Non-latin characters like Cyrillic (, )
- Символы иероглифического письма (, , ).CJK characters (, , )
Распространенные причины проблем с кодировкой:Common reasons for encoding issues are:
- Параметры кодировок по умолчанию VS Code и PowerShell не были изменены.The encodings of VS Code and PowerShell have not been changed from their defaults. В версиях до PowerShell 5.1 (включительно) кодировка по умолчанию отличается от используемой в VS Code.For PowerShell 5.1 and below, the default encoding is different from VS Code’s.
- Открыт другой редактор, и файл перезаписан в новой кодировке.Another editor has opened and overwritten the file in a new encoding. Это часто происходит с интегрированной средой сценариев.This often happens with the ISE.
- Файл возвращается в систему управления версиями в кодировке, отличающейся от той, которая ожидается в VS Code или PowerShell.The file is checked into source control in an encoding that is different from what VS Code or PowerShell expects. Это может произойти, когда участники совместной работы используют редакторы с различными конфигурациями кодировок.This can happen when collaborators use editors with different encoding configurations.
Как определить наличие проблемы с кодировкойHow to tell when you have encoding issues
Часто ошибки кодирования в скриптах представляются как ошибки синтаксического анализа.Often encoding errors present themselves as parse errors in scripts. Если вы видите странные последовательности символов в скрипте, это может быть проблемой.If you find strange character sequences in your script, this can be the problem. В примере ниже тире () отображается в виде символов :In the example below, an en-dash () appears as the characters :
Эта проблема возникает, так как VS Code кодирует символ в UTF-8 как байты .This problem occurs because VS Code encodes the character in UTF-8 as the bytes . Если эти байты декодируются в кодировке Windows-1252, они интерпретируются как символы .When these bytes are decoded as Windows-1252, they are interpreted as the characters .
Некоторые странные последовательности символов, которые можно видеть:Some strange character sequences that you might see include:
- вместо . instead of
- вместо . instead of
- вместо . instead of
- вместо (неразрывный пробел); instead of (a non-breaking space)
- вместо . instead of
Этот удобный справочник перечисляет распространенные шаблоны, которые указывают на проблему между кодировками UTF-8 и Windows-1252.This handy reference lists the common patterns that indicate a UTF-8/Windows-1252 encoding problem.
Подробное описаниеLong description
Юникод — это мировой стандарт кодировки символов.Unicode is a worldwide character-encoding standard. Система использует Юникод исключительно для обработки символов и строк.The system uses Unicode exclusively for character and string manipulation. Подробное описание всех аспектов Юникода см. в стандарте Юникода.For a detailed description of all aspects of Unicode, refer to The Unicode Standard.




Windows поддерживает Юникод и традиционные наборы символов.Windows supports Unicode and traditional character sets. Традиционные кодировки, например кодовые страницы Windows, используют 8-разрядные значения или сочетания 8-разрядных значений для представления символов, используемых в определенном языке или географических регионах.Traditional character sets, such as Windows code pages, use 8-bit values or combinations of 8-bit values to represent the characters used in a specific language or geographical region settings.
По умолчанию PowerShell использует набор символов Юникода.PowerShell uses a Unicode character set by default. Однако несколько командлетов имеют параметр кодирования , который может указывать кодировку для другой кодировки.However, several cmdlets have an Encoding parameter that can specify encoding for a different character set. Этот параметр позволяет выбрать конкретную кодировку символов, необходимую для взаимодействия с другими системами и приложениями.This parameter allows you to choose the specific the character encoding you need for interoperability with other systems and applications.
Следующие командлеты имеют параметр Encoding :The following cmdlets have the Encoding parameter:
-
Microsoft.PowerShell.ManagementMicrosoft.PowerShell.Management
- Add-ContentAdd-Content
- Get-ContentGet-Content
- Set-ContentSet-Content
-
Microsoft.PowerShell.UtilityMicrosoft.PowerShell.Utility
- Export-ClixmlExport-Clixml
- Export-CsvExport-Csv
- Export-PSSessionExport-PSSession
- Format-HexFormat-Hex
- Import-CsvImport-Csv
- Out-FileOut-File
- Select-StringSelect-String
- Send-MailMessageSend-MailMessage
Проблемы консолей Visual Studio
В Visual Studio имеется возможность подключения консолей, по умолчанию подключены командная строка для разработчика и Windows PowerShell для разработчика. К достоинствам можно отнести возможности определения собственных параметров консоли, отдельных от общесистемных, а также запуск консоли непосредственно в директории разработки. В остальном — это обычные стандартные консоли Windows, включая, как показано ранее, установленную кодовую страницу по умолчанию.
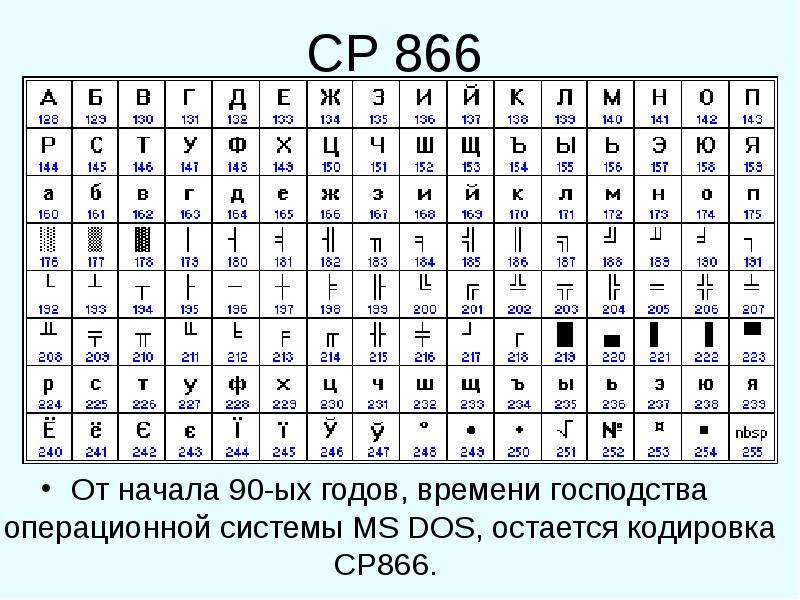
Отдельной опцией Visual Studio является встроенная односеансная консоль отладки, которая перехватывает команду Visual Studio на запуск приложения, запускается сама, ожидает компиляцию приложения, запускает его и отдает ему управление. Таким образом, отладочная консоль в течение всего рабочего сеанса находится под управлением приложения и возможность использования команд Windows или самой консоли, включая команду CHCP, не предусмотрена. Более того, отладочная консоль не воспринимает кодовую страницу по умолчанию, определенную в реестре, и всегда запускается в кодировке 437 или 866.
Анализ проблем консолей был бы не полон без ответа на вопрос — можно ли запустить консольное приложение без консоли? Можно — любой файл «.exe» запустится двойным кликом, и даже откроется окно приложения. Однако консольное приложение, по крайней мере однопоточное, по двойному клику запустится, но консольный режим не поддержит — все консольные вводы-выводы будут проигнорированы, и приложение завершится
Работа с кодировкой Windows 1251 в различных программных средах
Для начала, убедитесь, что ваша программная среда поддерживает кодировку Windows 1251. Это можно проверить, изучив документацию или настройки вашей среды разработки. Если ваша среда поддерживает данную кодировку, вы можете начать использовать ее в своих проектах.
Одним из основных моментов работы с кодировкой Windows 1251 является правильное чтение и запись файлов в этой кодировке. В большинстве сред разработки вы можете указать кодировку при открытии файла или сохранении файлов. Убедитесь, что при чтении и записи файлов вы указываете кодировку Windows 1251.
Если вы работаете с текстом в кодировке Windows 1251, обратите внимание на то, что некоторые символы могут отображаться неправильно, если ваша среда разработки или другие инструменты используют другую кодировку по умолчанию. Чтобы избежать таких проблем, убедитесь, что вы правильно указываете кодировку везде, где это необходимо
| Среда разработки | Как указать кодировку Windows 1251 |
|---|---|
| IntelliJ IDEA | File -> Settings -> Editor -> File Encodings |
| Eclipse | Window -> Preferences -> General -> Workspace |
| Visual Studio Code | File -> Preferences -> Settings -> Text Editor -> Files |
| Sublime Text | File -> Save with Encoding |
Если вы работаете с базой данных, убедитесь, что вы используете правильную кодировку при создании и чтении данных. Многие базы данных поддерживают кодировку Windows 1251, и вы можете указать ее в настройках базы данных или при создании таблиц.
Важно отметить, что кодировка Windows 1251 может вызвать проблемы с совместимостью, если ваше приложение должно работать с другими кодировками или с другими системами, которые используют другую кодировку. В таких случаях вам может потребоваться преобразование данных или изменение кодировки вашего приложения
В заключение, работа с кодировкой Windows 1251 может быть довольно простой, если вы знаете, как правильно установить и использовать эту кодировку в вашей программной среде. Будьте внимательны к указанию кодировки в различных ситуациях, чтобы избежать проблем с отображением символов и совместимостью с другими системами.
Пометка порядка байтов
Символ-пометка (BOM) — это сигнатура в Юникоде в первых нескольких байтах файла или текстового потока, указывающих, какая кодировка Юникода используется для данных. Дополнительные сведения см. в документации по метке порядка байтов .
в Windows PowerShell любая кодировка юникода, за исключением , всегда создает спецификацию. По умолчанию PowerShell Core имеет значение для всех текстовых выходных данных.
Для обеспечения оптимальной совместимости Избегайте использования спецификаций в файлах UTF-8. платформы unix и служебные программы unix-heritage, также используемые на платформах Windows, не поддерживают спецификации.
Аналогичным образом следует избегать кодирования. UTF-7 не является стандартной кодировкой Юникода и записывается без спецификации во всех версиях PowerShell.
создание сценариев PowerShell на платформе, похожем на Unix, или использовании кросс-платформенного редактора на Windows, например Visual Studio Code, приводит к созданию файла, закодированного с помощью . эти файлы прекрасно работают в PowerShell Core, но могут нарушить работу Windows PowerShell если файл содержит символы, отличные от Ascii.
Если в скриптах необходимо использовать символы, отличные от ASCII, сохраните их как UTF-8 с помощью BOM. без спецификации Windows PowerShell правильно интерпретирует скрипт как закодированный в устаревшей кодовой странице ANSI. И наоборот, файлы, имеющие СПЕЦИФИКАЦИю UTF-8, могут быть проблематичными для платформ, подобных Unix. Многие средства UNIX, такие как ,, и некоторые редакторы, например, не узнают, как обрабатывать спецификацию.
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.
UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей. Для этого необходимо вставить в тег head следующие данные
После символов «charset=» идет либо утф, либо виндовс, как в примере ниже
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.


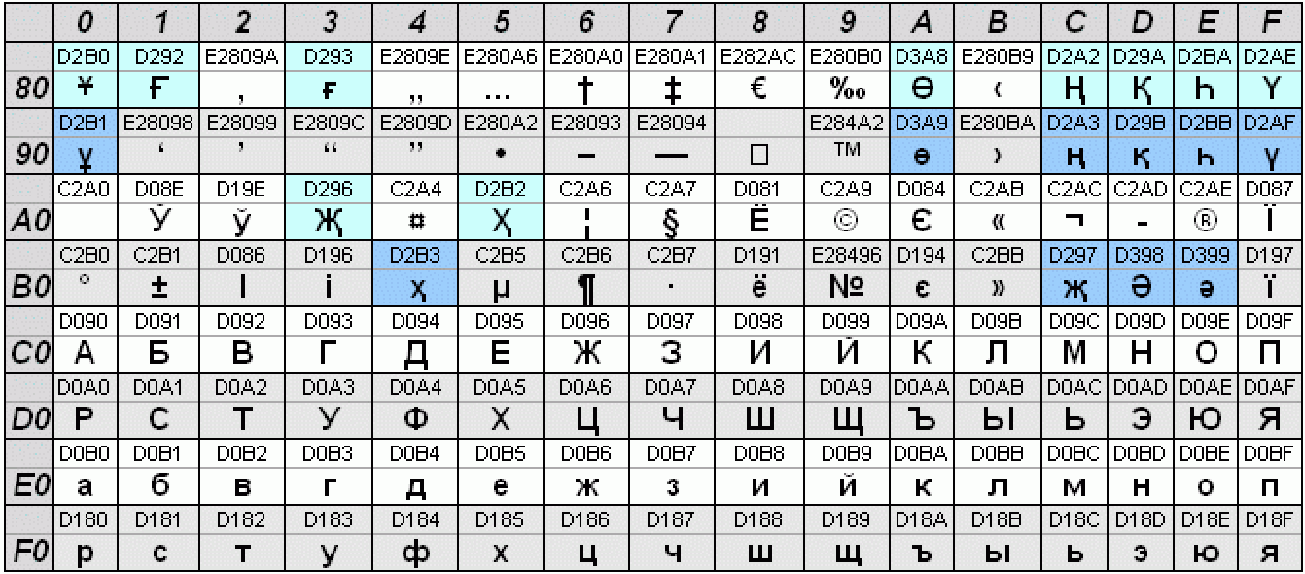



<meta http-equiv="Content-Type" content="text/html; charset=utf-8"> |
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова «Создание и Раскрутка сайта от А до Я».
Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова. Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.
Что-то я отошел от темы. Давайте вернемся к кодировкам.
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Решения проблемы с кодировкой в CMD. 1 Способ.
Для решения проблемы нужно просто использовать текстовой редактор, с помощью которого можно сохранить текст в кодировке «866». Для этих целей прекрасно подходит «Notepad++
» (Ссылку для загрузки Вы можете найти в моём Twitter-e).
Скачиваем и устанавливаем на свой компьютер «Notepad++
После запуска «Notepad++
» запишете в документ те же строки, которые мы уже ранние записывали в стандартный блокнот.
Теперь осталось сохранить документ с именем «2.bat» в правильной кодировке. Для этого идём в меню «Кодировки
>Кодировки >Кириллица >OEM-866 »
и теперь сохраняем файл с именем «2.bat» и запускаем его! Поле запуска результат на лицо.
Как видим, текст на Русском в CMD отобразился, как положено.
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.

Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
Предотвращение ошибки «неверная последовательность байт для кодировки utf8 0x00»
Ошибка «неверная последовательность байт для кодировки utf8 0x00» может возникать в процессе работы с текстовыми данными, когда используется кодировка UTF-8. Эта ошибка указывает на наличие неправильной последовательности байтов, которая не может быть интерпретирована как символ в UTF-8.
Существует несколько причин возникновения этой ошибки:
- Неправильное сохранение или передача данных в кодировке UTF-8.
- Использование недопустимых символов в кодировке UTF-8.
- Ошибка в работе с базой данных или другими источниками данных, где хранятся текстовые данные в кодировке UTF-8.
Для предотвращения ошибки «неверная последовательность байт для кодировки utf8 0x00» рекомендуется принять следующие меры:
- Убедитесь, что используется правильная кодировка при сохранении и передаче текстовых данных. Например, при сохранении данных на сервере, установите правильную кодировку в настройках сервера или при передаче данных укажите кодировку в заголовках запроса.
- Проверьте, что используемые символы допустимы в кодировке UTF-8. Некоторые символы могут быть запрещены или иметь специальное значение в UTF-8.
- Убедитесь, что работа с базой данных или другими источниками данных корректна и правильно учитывает кодировку текстовых данных. Проверьте настройки базы данных или других источников данных, чтобы быть уверенными в правильной работе с UTF-8.
Также можно применить следующие рекомендации:
- Используйте библиотеки или инструменты, которые обеспечивают корректную работу с кодировкой UTF-8. Некоторые языки программирования предоставляют встроенные функции для работы с UTF-8, которые могут снизить вероятность возникновения ошибки.
- Проводите тщательное тестирование своего приложения или программного обеспечения перед его выпуском или внедрением. Убедитесь, что вы включили проверку на корректность кодировки и обработку ошибок, связанных с кодировкой, чтобы избежать проблем в работе с текстовыми данными.
Соблюдение этих рекомендаций поможет предотвратить возникновение ошибки «неверная последовательность байт для кодировки utf8 0x00» и обеспечить корректную работу с UTF-8 кодировкой.
Ссылки
| Кодировки символов | ||
|---|---|---|
| Основы | алфавит • текст (файл • данные) • набор символов • конверсия | |
| Исторические кодировки | Докомп.: | семафорная (Макарова) • Морзе • Бодо • МТК-2 |
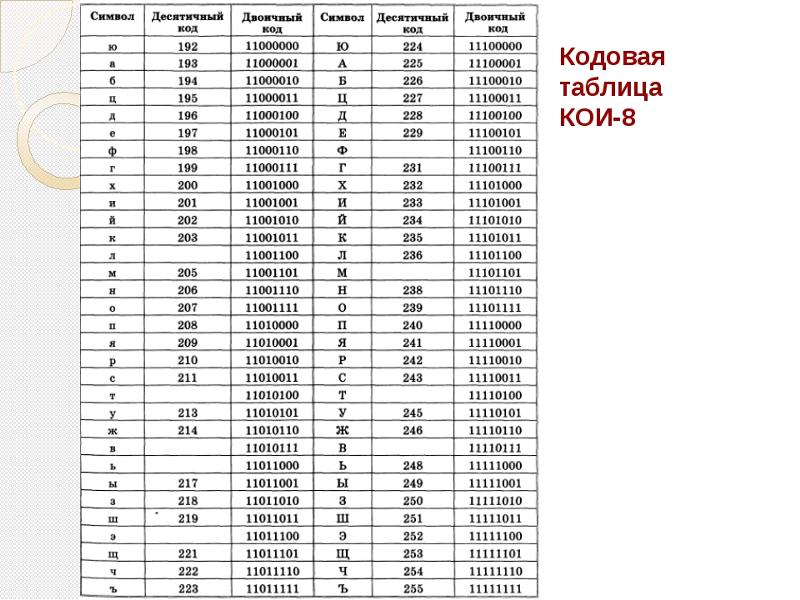
| Комп.: | 6-битная • УПП • RADIX-50 • EBCDIC (ДКОИ-8) • КОИ-7 • ISO 646 | |
| современное8-битноепредставление | символы | ASCII (управляющие • печатные) • не-ASCII (псевдографика) |
| 8-битные код.стр. | Кириллица: КОИ-8 • Основная кодировка • MacCyrillic | |
| ISO 8859 | 1 (лат.) • • • • 5 (кир.) • • • • • • • • • • 15 (€) • | |
| Windows | • 1251 (кир.) • • • • • • • • WGL4 | |
| IBM & DOS | • • • • 866 «альт.» • МИК | |
| Многобайтные | Традиционные | DBCS (GB2312) • HTML |
| Unicode | UTF-32 • UTF-16 • UTF-8 • список символов (кириллица) | |
| Связанные темы | интерфейс пользователя • раскладка клавиатуры • локаль • перевод строки • шрифт • транслит • нестандартные шрифты | |
| Утилиты | iconv • recode |
Декодер текста — переводчик кодировок utf 8 и windows 1251 онлайн
UTF-8 (Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-битный») — одна из общепринятых и стандартизированных кодировок текста, которая позволяет хранить символы в Unicode. Стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D. Кодировка нашла широкое применение в UNIX-подобных операционных системах и веб-пространстве. В качестве BOM использует последовательность байт EF16, BB16, BF16 (что является трёхбайтовой реализацией символа FEFF16). Одним из преимуществ является совместимость с ASCII — любые их 7-битные символы отображаются как есть, а остальные выдают пользователю мусор (шум). Поэтому в случае, если латинские буквы и простейшие знаки препинания (включая пробел) занимают существенный объём текста, UTF-8 даёт выигрыш по объёму в сравнении с UTF-16.
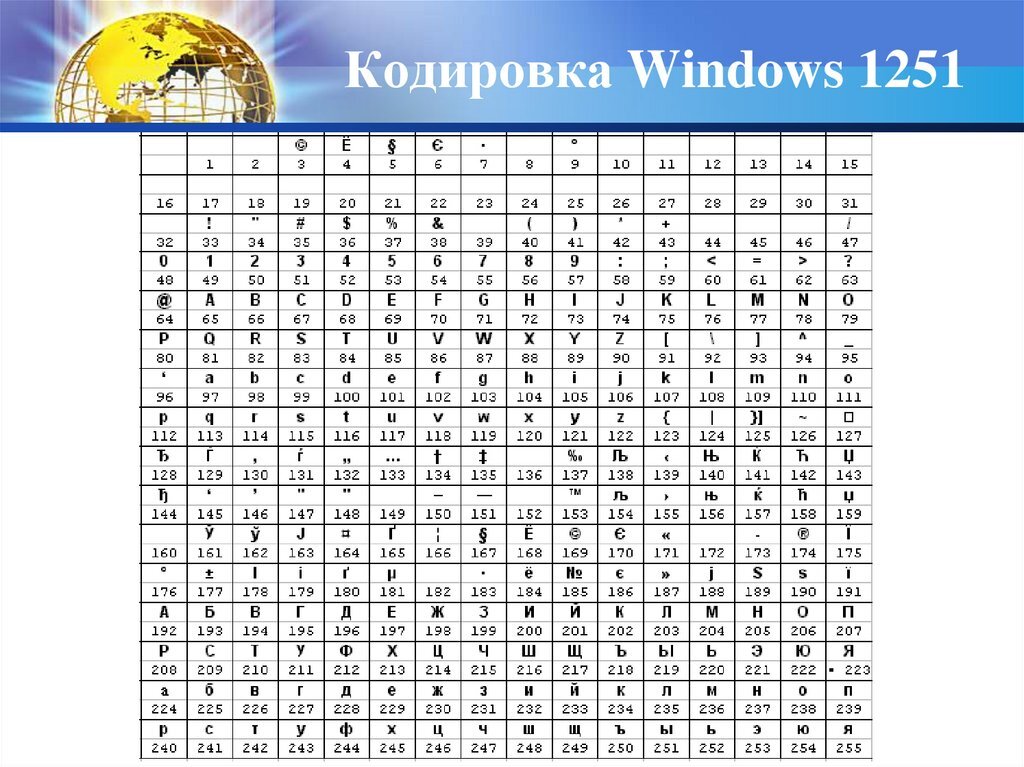
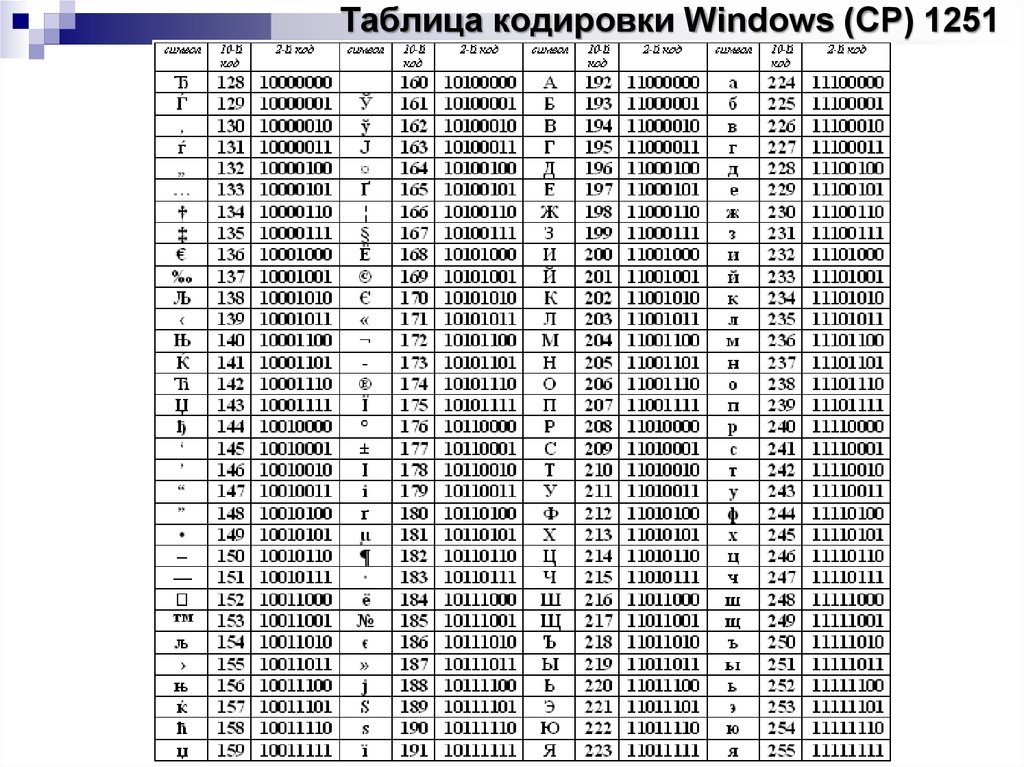
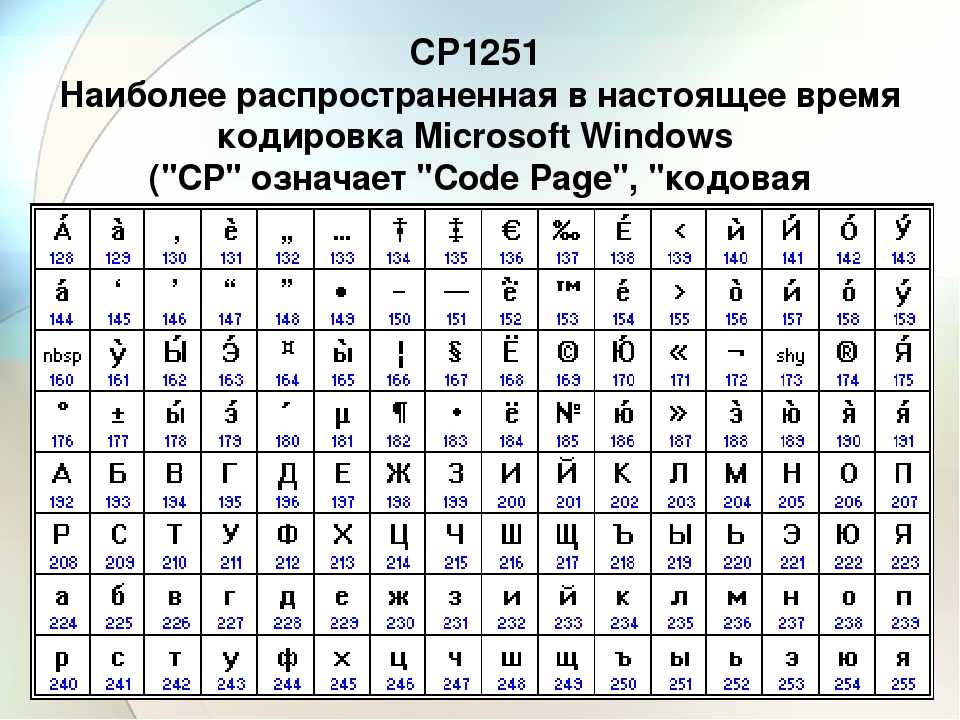
Windows-1251 (синоним CP1251) — является стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только знак — ударение); она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского, македонского и болгарского.
Универсальный онлайн декодер (переводчик кодировок)
Такой переводчик (сервис или программное обеспечение) еще называют как дешифратор, если Вам приходится работать с разными кодировками текста или возникли проблемы с кодировкой страниц в PHP (отображение в виде странной комбинации загадочных символов — «кракозябры»). Функциональный и универсальный сервис в режиме онлайн, автоматически поможет определить кодировку, покажет примеры всех комбинаций кодировок, чтобы вы могли выбрать подходящую и перевести текст из одной кодировки в другую. То есть универсальный декодер поможет перевести текст (предположим, что на кириллице) в другие международные форматы.
Данный декодер универсален, хотите закодировать текст для PHP или HTML страниц, а может быть в Java?
Все проблемы кодировок решаются раскодировкой (перекодировкой) путем декодера, но способ кодирования зависит от формата документа в котором тот был закодирован и для этого необходимо сменить формат самого документа, а не изобретать новые способы интерпритации. В случае с серверами используйте их конфигурацию — онлайн переводчик кодировок поможет узнать какая именно кодировка используется в вашем случае — вставьте скопированные символы в окно декодера.
- < Назад
- Вперёд >