
Десятичная система: удобство использования в повседневной жизни
Одно из главных преимуществ десятичной системы – ее простота и понятность. Все числа от 0 до 9 представлены отдельными символами, что облегчает их восприятие и запись. Большие числа образуются путем комбинации этих символов. Например, число 1234 состоит из цифр 1, 2, 3 и 4, записанных в определенном порядке.
Десятичная система также обладает удобством при выполнении различных операций, таких как сложение, вычитание, умножение и деление. Большие числа могут быть разделены на разряды и легко складываться или вычитаться по одному разряду за раз. Это позволяет проводить арифметические операции с большими числами без лишних сложностей.
В повседневной жизни десятичная система широко применяется при работе с деньгами. Десятичные доллары и центы легко понять и использовать при покупках, расчетах и ведении бюджета. Она также используется для измерения времени, например, 12-часовые и 24-часовые часы.
Более того, десятичная система удобна для выражения и измерения долей. Например, в процентах или долях можно указать, сколько процентов или какую часть составляет число относительно другого числа. Это помогает в анализе данных и сравнении различных величин.
В заключение, десятичная система представляет собой простую и понятную систему представления чисел, которая широко используется в повседневной жизни. Ее удобство и практичность делают ее незаменимой для большинства областей нашей деятельности.
Какой формат кодировки выбрать
Выбор формата кодировки зависит от типа текстового файла, который вы пытаетесь открыть. Наиболее часто используемыми форматами кодировки являются UTF-8, UTF-16 и ISO-8859-1.
Если файл содержит только латинский алфавит, то лучше всего использовать кодировку ISO-8859-1. Эта кодировка поддерживает только латинские символы и может быть открыта в большинстве текстовых редакторов.
Если файл содержит символы национальных алфавитов, то лучше всего использовать кодировку UTF-8. Эта кодировка может поддерживать любой символ с любого языка, а также поддерживает символы эмодзи и другие графические символы.
Если файл содержит символы в юникоде, то лучше всего использовать кодировку UTF-16. Она поддерживает все символы на всех языках и может быть использована в программировании.
Важно помнить, что при открытии файла в определенной кодировке необходимо убедиться, что этот же формат кодировки используется и в программе, которую вы используете для его открытия. Несоответствие форматов кодировки может привести к ошибкам или к неправильному отображению текста
Описание разных форматов кодировок
Кодировка символов — это способ представления символов в компьютерных системах. Существует несколько разных форматов кодировок, каждый из которых использует свой уникальный набор символов и правила преобразования. Ниже описаны некоторые из наиболее распространенных форматов кодировок.
- ASCII: первоначально разработана для представления символов на английском языке, ASCII используется везде, где необходимо представлять текст в чистом виде, без форматирования.
- UTF-8: стандартная кодировка символов в Интернете, UTF-8 использует переменную длину кодирования, что позволяет ей представлять символы всех языков.
- ISO-8859-1: разработана для представления символов на европейских языках, ISO-8859-1 используется в тех случаях, когда ASCII не содержит достаточно символов для требуемого языка.
- Windows-1251: разработана для представления символов русского языка, Windows-1251 используется на большинстве компьютеров в России и Украине.
Знание формата кодировки, используемой в файле, является важным при работе с текстовыми файлами, особенно в многоплатформенных приложениях.
Как выбрать подходящую кодировку
Кодировка – это способ записи и хранения текста в компьютере, а это часто приводит к проблемам при обмене информацией между различными системами. В таком случае выбор подходящей кодировки имеет большое значение.
Основными критериями выбора являются содержащиеся в тексте символы и язык, на котором написан текст. Например, unicode может использоваться для записи любых языков, включая редкие, а для записи русского языка используют кодировки windows-1251, ISO-8859-5 и UTF-8.
Если вы не знаете кодировку файла, существуют инструменты для её определения. В Java вы можете использовать класс CharsetDetector из библиотеки ICU4J для определения кодировки текста.
- UTF-8 — рекомендуется использовать везде, где это возможно, особенно в Интернете и в международном контексте;
- ISO-8859-1 — используется для западноевропейских языков с латинским алфавитом (английский, немецкий, французский и т.д.);
- Windows-1252 — дополнение к ISO-8859-1 с символом евро;
- KOI8-R — стандартная кодировка для русского языка, широко используется в Unix-системах;
- CP-1251 — кодировка, разработанная для Windows, используется для записи текста на русском языке и других языках, использующих кириллицу.
Таким образом, правильный выбор кодировки позволит избежать проблем с отображением текста, сохранение целостности данных и обмен информацией между компьютерными системами.
Какие инструменты можно использовать
Для определения кодировки файлов в архиве Java можно использовать несколько инструментов.
- Утилиты командной строки — такие, как zipinfo, unzip, jar, tar и др. Они позволяют просмотреть метаинформацию файла, включая кодировку.
- Интегрированные среды разработки — например, Eclipse, IntelliJ IDEA или NetBeans. Они предоставляют возможность просмотра содержимого архивов и определения кодировки каждого файла внутри архива.
- Сторонние утилиты и библиотеки — такие, как Apache Tika или ICU4J. Они могут автоматически определять кодировку текстовых файлов внутри архивов.
Выбор инструмента зависит от ваших предпочтений и требований проекта.
| Инструмент | Преимущества | Недостатки |
|---|---|---|
| Утилиты командной строки | Простота использования, быстрый доступ к метаинформации файла | Требуют знания командной строки, не позволяют автоматически определить кодировку |
| Интегрированные среды разработки | Удобство использования, возможность работать со всем проектом целиком | Требуют установки и настройки среды разработки |
| Сторонние утилиты и библиотеки | Автоматическое определение кодировки, поддержка различных форматов файлов | Требуют установки, возможны проблемы совместимости с проектом |
Средства командной строки
Командная строка предоставляет набор утилит, которые позволяют выполнять различные операции с файлами и директориями. С их помощью можно узнать кодировку файла в архиве Java.
Для начала необходимо открыть командную строку. На Windows это можно сделать, нажав Win+R и введя команду «cmd» в появившейся строке. На Linux и macOS командную строку можно открыть через терминал.
Для получения информации о файле в архиве Java необходимо выполнить следующие шаги:
- Перейти в директорию с архивом Java при помощи команды «cd».
- Извлечь нужный файл из архива с помощью утилиты «jar». Например, команда «jar xvf myArchive.jar myfile.txt» извлечет файл «myfile.txt» из архива «myArchive.jar».
- Получить информацию о кодировке файла с помощью утилиты «file». Например, команда «file -i myfile.txt» покажет кодировку файла «myfile.txt».
Таким образом, командная строка представляет мощный инструмент для работы с файлами и позволяет просто и быстро получить информацию о файле в архиве Java.
Бесплатные приложения для Windows
Windows — одна из самых популярных операционных систем, используемых миллионами пользователей по всему миру. Сегодня мы рассмотрим список бесплатных приложений, которые помогут вам улучшить работу с вашим Windows-компьютером.



Антивирусы и защита
- Avast Antivirus — одна из наиболее популярных бесплатных программных продуктов для защиты компьютера от вирусов и других вредоносных программ.
- Malwarebytes Anti-Malware — программное обеспечение, которое способно обнаруживать и удалять различные угрозы, включая вредоносные программы, трояны, руткиты, рекламное ПО и другие подобные программы.
- Windows Defender — приложение, встроенное в Windows 10, которое обеспечивает защиту компьютера от вирусов и других вредоносных программ.
Офисные приложения
- LibreOffice — бесплатный пакет офисных приложений, включающий текстовый редактор, электронные таблицы, презентационное программное обеспечение и другие полезные инструменты.
- OpenOffice — пакет офисных приложений с открытым исходным кодом, включающий схожие компоненты с LibreOffice.
- WPS Office Free — бесплатное приложение, включающее текстовый процессор и электронную таблицу.
Программы для работы с графикой и мультимедиа
- GIMP — редактор изображений с открытым исходным кодом, подходящий для широкого спектра задач обработки изображений.
- Inkscape — векторный редактор, способный работать с различными векторными форматами, такими как SVG и EPS.
- VLC media player — проигрыватель мультимедиа, способный воспроизводить видео и аудио в разных форматах, включая DVD, CD, MP3 и многие другие.
Системные утилиты
- CCleaner — приложение для очистки и оптимизации компьютера, удаляющее ненужные файлы и исправляющее ошибки реестра.
- Defraggler — приложение для дефрагментации жесткого диска, ускоряющее работу компьютера.
- WinDirStat — инструмент для анализа дискового пространства, позволяющий определить, какие файлы и папки занимают больше всего места на жестком диске.
Заключение
Мы рассмотрели несколько бесплатных приложений для Windows, которые помогут вам улучшить работу с вашим компьютером. Вы можете выбрать нужное приложение из этого списка или найти подходящую замену для своих потребностей.
Криптография
В особых случаях возникает необходимость в засекречивании информации, содержащейся в сообщениях или документации. Это нужно для того чтобы она не была прочтена сторонними людьми. Такое кодирование текста именуется защитой данных от несанкционированного доступа, при которой секретный текст зашифровывается. В далеком прошлом пытались скрывать данные посредством тайнописи.
Под шифрованием подразумевается процесс, при котором открытый текст преобразуется в зашифрованный. Дешифрование является полностью обратным процессом преобразования, цель которого — восстановление исходного текста. Шифрование тоже является кодированием, но с использованием засекреченного метода, известного лишь источнику данных и их получателю. Есть целая наука о методах шифрования, известная как криптография.
Криптография — это наука, изучающая принципы и методы передачи и приема данных, зашифрованных посредством специальных ключей. Ключи — это секретные данные, применяемые при шифровке и расшифровке информации.
Не нашли ответ?
Просто напиши,с чем тебе нужна помощь
Мне нужна помощь
Сайт w3c
На сайте w3c представлены официальные спецификации различных кодировок, включая UTF-8, UTF-16, ISO-8859-1 и другие. Также на сайте вы найдете информацию о правильном использовании каждой кодировки, ее преимуществах и недостатках.
Основные разделы сайта w3c, связанные с кодировками, включают информацию о различных типах символов и их кодировании, о правилах преобразования текста между различными кодировками, а также о способах определения кодировки для конкретного текста или файла.
Сайт w3c также предлагает ряд инструментов и рекомендаций по работе с кодировками, которые помогут вам узнать, какая кодировка используется на вашем сайте или в вашем файле. Благодаря этому ресурсу вы сможете легко разобраться с кодировками и решить возможные проблемы, связанные с их использованием.
Как узнать кодировку файла Python
Python — универсальный язык программирования, который обеспечивает поддержку различных форматов и кодировок текстовых файлов. Однако, иногда может возникнуть необходимость узнать кодировку конкретного файла. В этой статье мы рассмотрим несколько способов, которые помогут вам определить кодировку файла в Python.
1. Использование модуля chardet
Модуль chardet является отличным инструментом для автоматического определения кодировки текстовых файлов. Для использования этого модуля, вам необходимо установить его с помощью команды:
После установки модуля вы можете использовать его в своем коде для определения кодировки файла:
В этом примере мы импортируем модуль chardet и определяем функцию get_encoding, которая принимает путь к файлу и возвращает кодировку файла. Мы открываем файл в режиме чтения бинарного файла (‘rb’), считываем его содержимое и передаем его в функцию detect модуля chardet. Функция detect возвращает словарь с информацией о кодировке файла, и мы извлекаем кодировку из этого словаря. Затем мы выводим кодировку файла на экран.
2. Использование модуля filemagic
Еще одним способом определения кодировки файла является использование модуля filemagic. Для установки этого модуля, выполните следующую команду:
После установки модуля вы можете использовать его в коде:
В этом примере мы импортируем модуль magic и определяем функцию get_encoding, которая принимает путь к файлу и возвращает кодировку файла. Мы используем функцию from_file модуля magic для определения типа файла. Если файл является текстовым файлом, то мы извлекаем кодировку из строки результата. В противном случае, мы выводим сообщение о том, что файл не является текстовым файлом.
3. Использование модуля codecs
Модуль codecs предоставляет функции для работы с различными кодировками. Одной из таких функций является open, которая позволяет открывать файлы с указанием кодировки. В случае, если файл имеет неправильную кодировку, будет возникать исключение UnicodeDecodeError. Мы можем использовать это исключение для определения кодировки файла:
В этом примере мы определяем функцию get_encoding, которая принимает путь к файлу и возвращает кодировку файла. Мы открываем файл с использованием функции open модуля codecs и указываем кодировку utf-8. Если при открытии файла возникает исключение UnicodeDecodeError, значит файл имеет неправильную кодировку и мы устанавливаем кодировку как ‘не utf-8’. В противном случае, файл имеет кодировку utf-8.
Кодировки
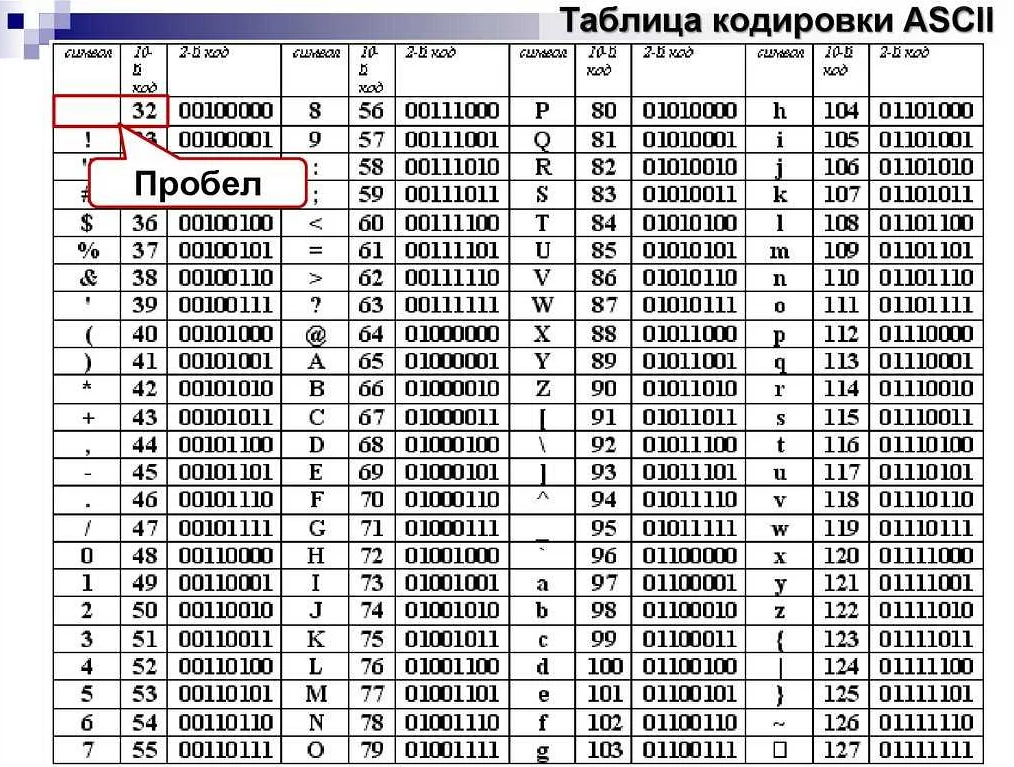
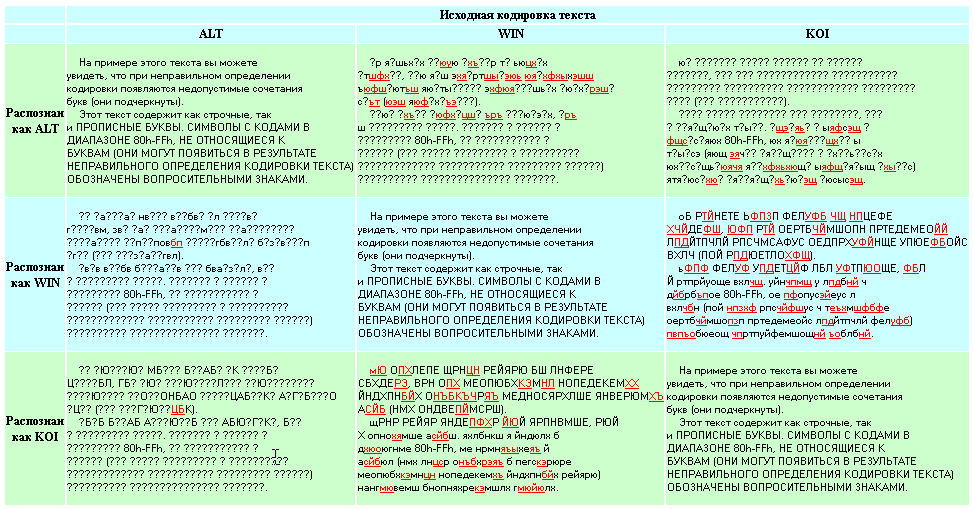
Итак, чтобы хранить символы не входящие в ASCII, необходимо было придумать новые кодировки. Поскольку до этого таблица ASCII была наиболее подходящей (были и другие), то она и пошла в основу новых кодировок. Поэтому следующие кодировки отличаются только значениями начиная с 80 (hex). Для наглядности оставлю только кириллические символы.

Так выглядела наиболее популярная кодировка под DOS. Примечательно что файлы в этой кодировке до сих пор встречаются. Как правило среди устаревшей архивной информации, в программах WinRar, Блокнот и WordPad, до сих пор есть опции «открыть как текст DOS», впрочем последними двумя мало кто пользуется =).
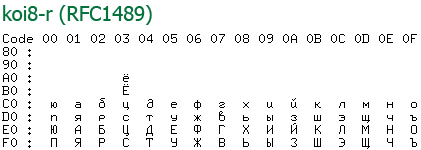
Кодировка koi8 была примечательна тем, что русские буквы там располагались на позициях английских звуков из нижней половины (т. е. ASCII). Это когда-то давно позволяло смягчить переход со старых серверов понимающие только ascii на новые, что было актуально среди почтовых серверов. Смысл был в том что если отправленное вами письмо приходило на старый сервер, то пользователю оно показывалось как транслит, что позволяло хоть как-то понять текст письма.

Самая популярная у нас в России однобайтная кодировка, на сегодняшний день, это именно «windows-1251». Разумеется популярность её целиком обусловлена популярностью Windows среди других операционных систем. Возможностей кодировки вполне хватает для использования её в широком круге задач. Например движок моего блога, по-умолчанию, использует для работы именно данную кодировку.

Я не могу не упомянуть о кодировке ISO, Удивительно, но несмотря на то что её никто никогда не использовал, эта кодировка является единственной кодировкой имеющей статус стандарта.
На примере данных кодировок видно, как один байт может хранить какое угодно символьное значение русского и английского языков, а также цифр и знаков пунктуации.
Но что делать когда этого не достаточно?
Многобайтные кодировки
Если вам хочется создать кодировку которая бы имела коды одновременно для русского и греческого алфавита? Одним байтом тут не отделаться. Появилась задача разработать кодировку один знак которой может занимать больше чем один байт, так как два байта могут принимать уже 2^16 = 65536 значений, а четыре байта аж 4294967296. Поэтому сначала придумали стандарт кодирования символов — Юникод, который включал бы в себя максимально полный перечень символов которые может принимать один знак.

Первая версия Юникода (Unicode 1991 г.) представляла собой 16-битную кодировку с фиксированной шириной символа; общее число разных символов было 216 (65 536).
Вторая версия Юникода (UCS-2), стала называться UTF-16, она позволяла гораздо расширить количество возможных значений, также используя для символов 16-битные последовательности (т. е. по 2 или по 4 байта на символ).
Кодировка UTF-32 (UCS-4) использует по 32 бита, или 4 байта на хранение одного символа. Строго говоря, стандарт Unicode не описывает символы со значениями выше 2^21, так что хватило бы и трёх байт, на символ, вероятно компьютеры работают несколько быстрее с мелкими блоками памяти кратными двум, или для того чтобы в сектор диска попадало кратное количество символов. Так или иначе это единственная из многобайтных кодировок с постоянной длиной. Помимо недостатка — использования четырёх байт на символ, у неё есть и очевидное преимущество — возможность прямой адресации к N-ному символу. В других кодировках требуется последовательное вычисление позиции каждого символа. Поэтому текстовые редакторы, внутри себя хранят всю информацию в виде UCS-4.
В 1992 году Кеном Томпсоном и Робом Пайком был изобретён формат UTF-8. Он отличается тем, что он ASCII совместим, и значения из таблицы Юникода могут занимать от 1 до 4х символов.
Символы UTF-8 получаются из Unicode следующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
| — | ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры | |
| — | кириллица, расширенная латиница, арабский, армянский, греческий, еврейский и коптский алфавит; сирийское письмо, тана, нко; МФА; некоторые знаки препинания | |
| — | все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы | |
| — | музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
Символы, в кодировке UTF-8, могут занимать до шести байт, но Unicode не определяет символов выше , поэтому символы Unicode могут иметь максимальный размер в 4 байта в UTF-8.
Что делать, если кодировку файла узнать не удалось
Если при использовании методов Java для определения кодировки файла возникли проблемы и вы не смогли узнать ее, можно воспользоваться несколькими способами для решения этой проблемы.
- Попробуйте использовать другие инструменты: Если метод, который вы использовали, не даёт результатов, можно попробовать использовать другой инструмент. Например, вместо метода Charset.defaultCharset(), используйте Charset.availableCharsets()
- Попробуйте использовать переход к другой кодировке: Если файл не удалось прочитать в текущей кодировке, можно попробовать использовать другую кодировку для прочтения файла. Например, если вы используете кодировку UTF-8, вы можете попробовать переключить на windows-1251
- Проверьте файл на наличие бинарных данных: Если файл содержит бинарные данные, то он может быть неконвертируемым в текст. В этом случае может помочь использование специальных инструментов для анализа бинарных данных.
Если вы выполнили все вышеперечисленные действия, но они не помогли, возможно, файл был поврежден и невозможно прочитать его в текущей кодировке. В этом случае необходимо проанализировать файл более подробно и попытаться восстановить его.
Попробовать использовать другой инструмент
Если вы столкнулись с проблемами определения кодировки файла в архиве Java и не можете найти решение, возможно стоит попробовать использовать другой инструмент. Существует множество бесплатных и платных приложений, которые могут помочь вам определить кодировку файла быстрее и легче.
Некоторые из наиболее популярных инструментов включают в себя Notepad++, Sublime Text, Eclipse и NetBeans. Эти приложения имеют целый набор инструментов, которые помогут вам найти кодировку файла, а также перекодировать его на нужную вам.
Еще одним полезным инструментом является онлайн-сервисы проверки кодировки, такие как Encode Explorer и Translit.ru. Вы можете загрузить файлы и проверить их кодировку онлайн, без необходимости скачивать и устанавливать профессиональное приложение.
Если вы использовали уже несколько инструментов, но все еще не получили необходимой информации, обратитесь к команде разработчиков соответствующего ПО. Возможно, они смогут помочь вам решить проблему.
Не забывайте, что большинство инструментов работает с файлами определенных форматов, поэтому убедитесь, что выбранный вами инструмент может работать с форматом файла, который вам нужен.
Использование других инструментов может занять некоторое время, но это может оказаться более эффективным решением, чем попытки найти кодировку файла методом проб и ошибок.
Спросить у разработчика или автора файла
Если вы не можете определить кодировку файла в архиве Java, возможно самый простой способ — спросить у разработчика или автора файла. Если файл является частью какого-либо проекта, то вы можете связаться с разработчиком, который знает кодировку используемых файлов в этом проекте.
Если файл получен из какого-либо внешнего источника, такого как почта или скачивание с Интернета, то вы можете проверить метаданные или описание файла для получения контактной информации автора. Некоторые авторы могут включить информацию о кодировке файла в описание перед его публикацией.
Если вы найдете автора файла, свяжитесь с ним и задайте вопрос о том, какая кодировка использовалась для создания файла. Если автор не знает, то вы можете попробовать использовать некоторые инструменты для определения кодировки, о которых мы говорили в предыдущих абзацах.
Выбор кодировки текста при открытии и сохранении файлов
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
- Общие сведения о кодировке текста
- Выбор кодировки при открытии файла
- Выбор кодировки при сохранении файла
- Поиск кодировок, доступных в Word
Общие сведения о кодировке текста
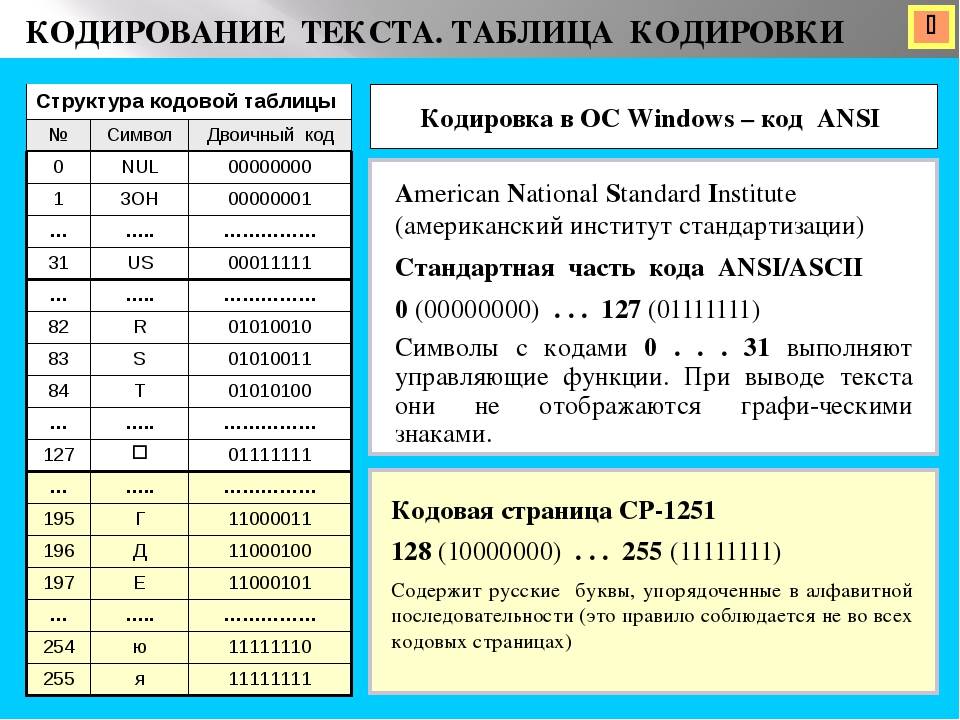
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
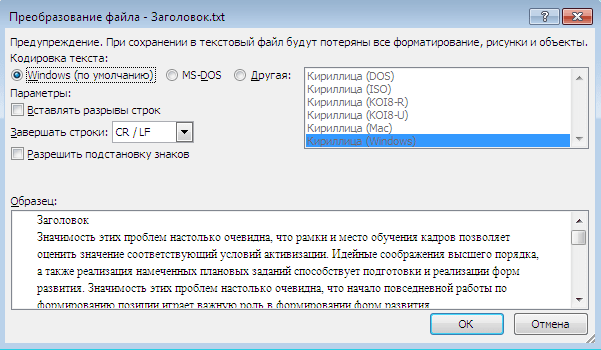
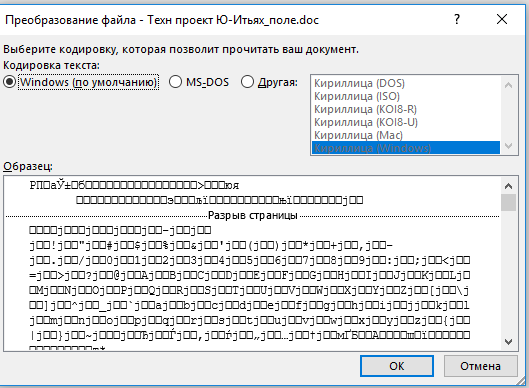
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
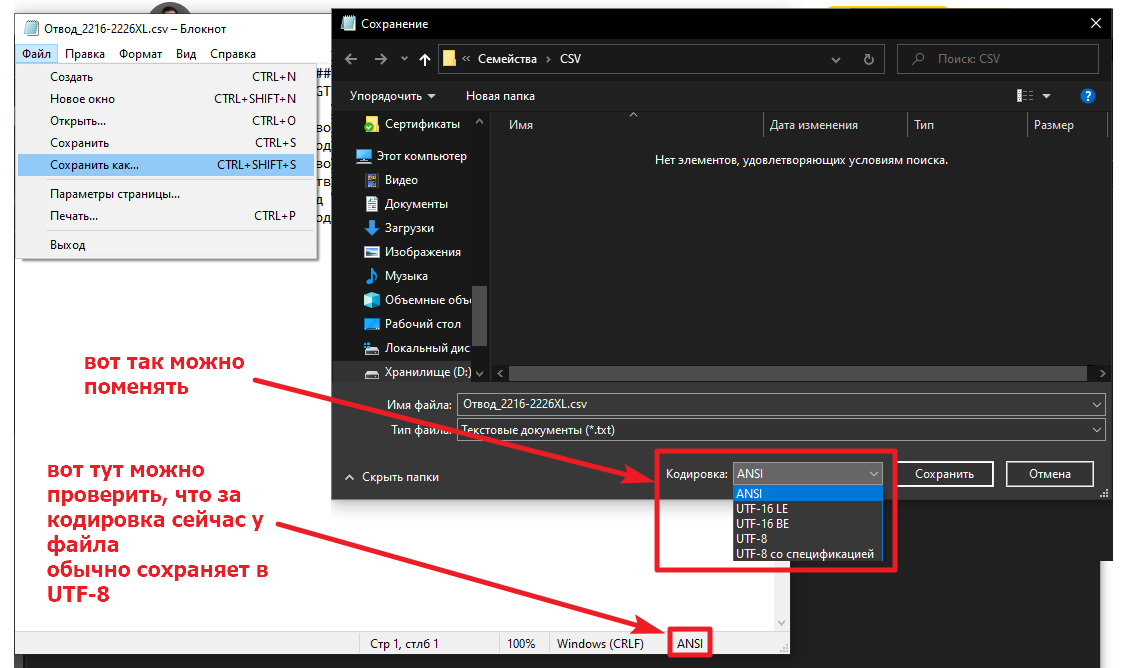
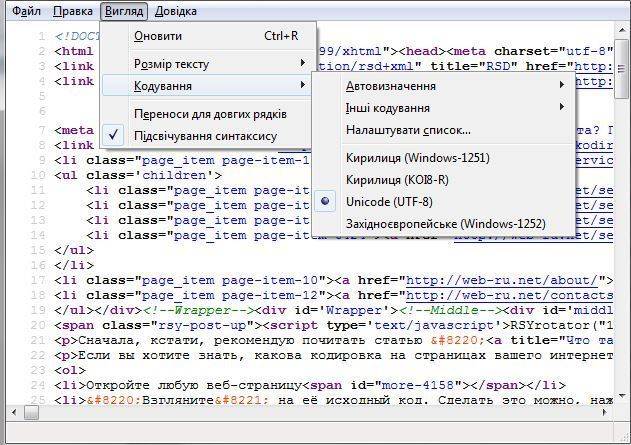

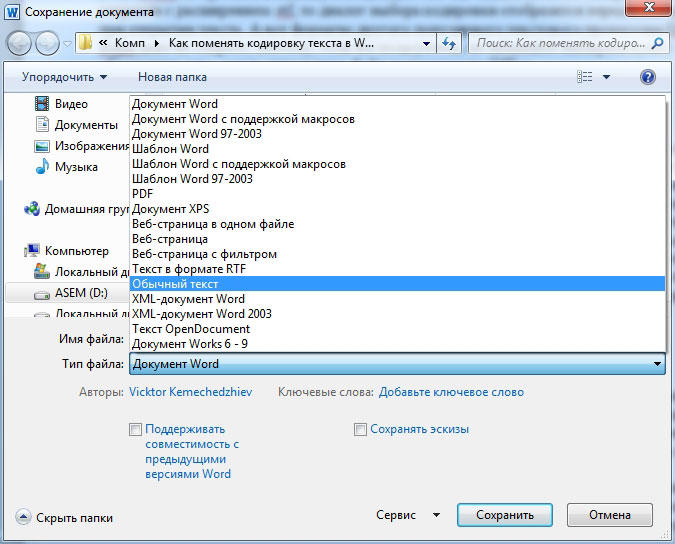
Выбор кодировки при открытии файла
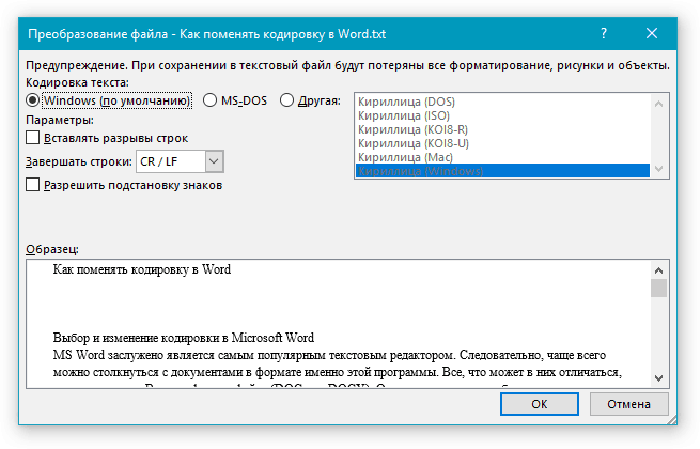
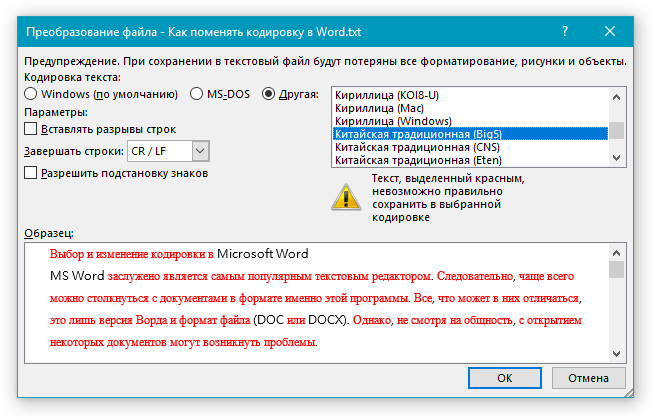
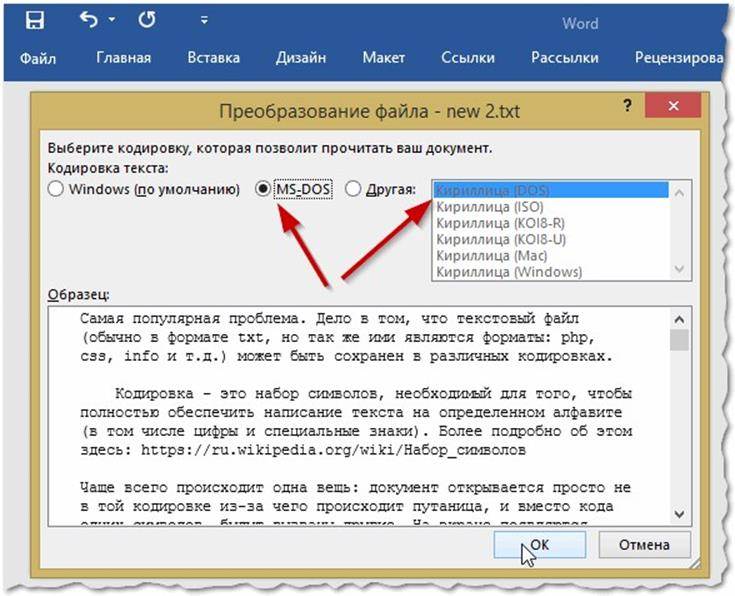
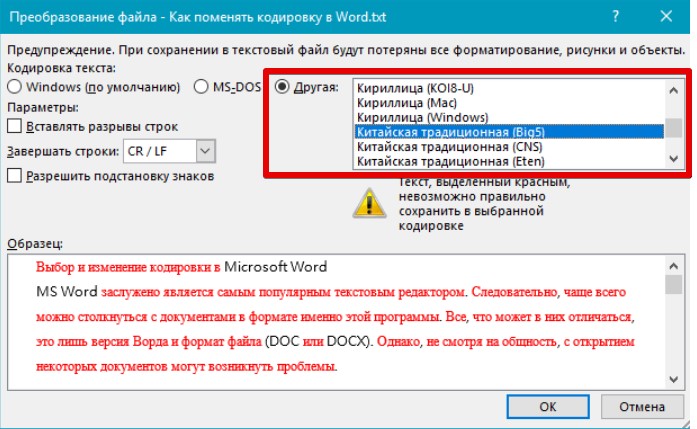
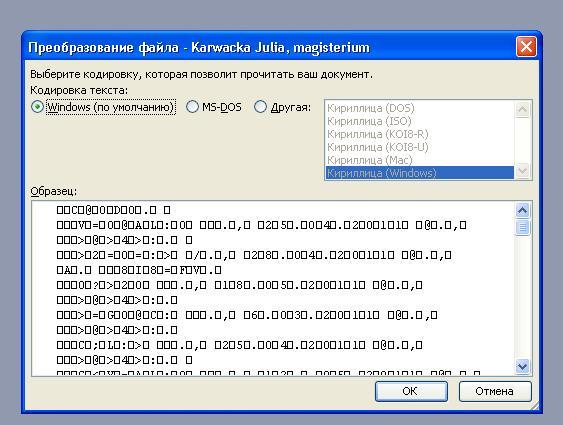
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
- Откройте вкладку Файл.
- Нажмите кнопку Параметры.
- Нажмите кнопку Дополнительно.
-
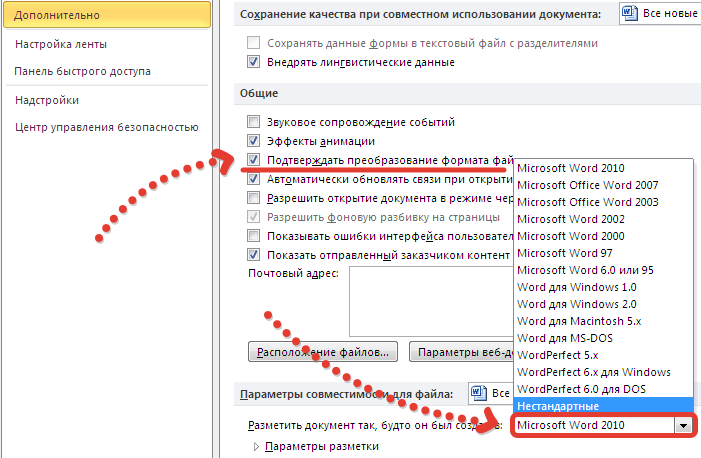
Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
Кодировка
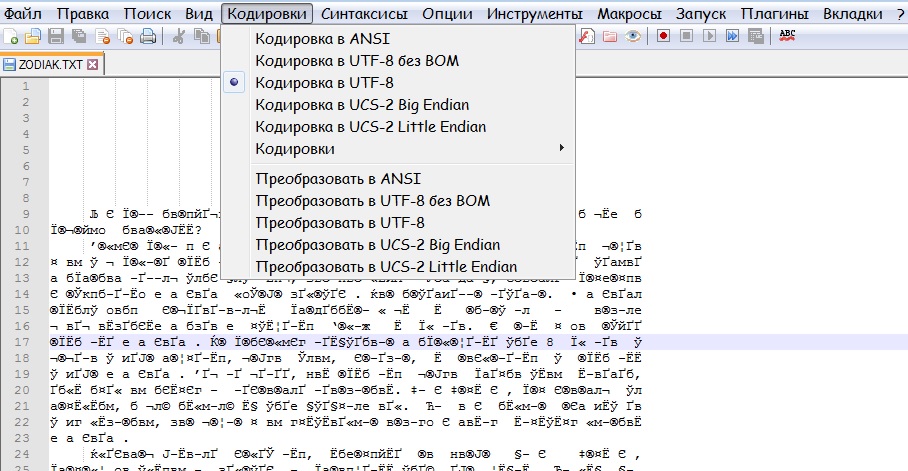
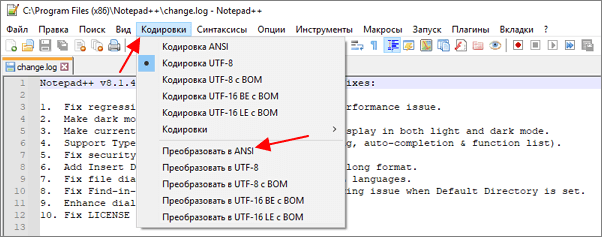
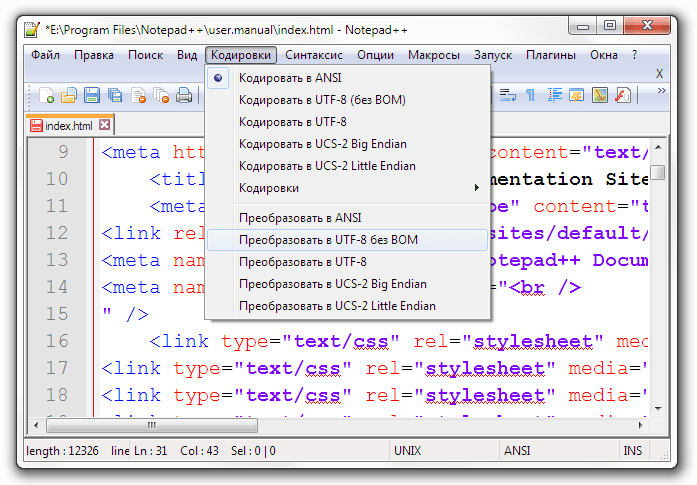
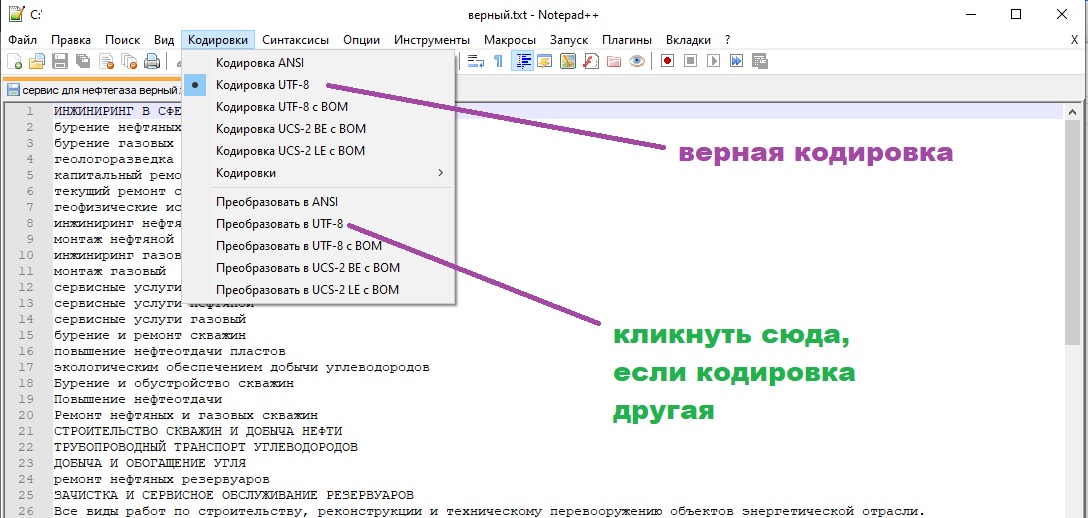
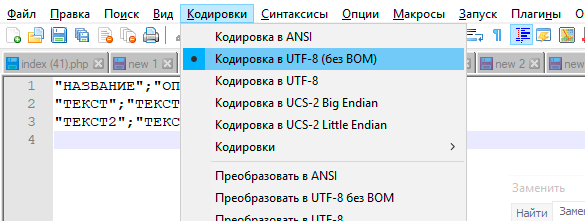
Текст может быть закодирован несколькими способами. Большинство текстовых файлов (старых) используют кодировку называемой ANSI, которая имеет ограничение по количеству доступных символов, но часто бывает достаточной, чтобы отобразить весь текст. Тем не менее, кодировки Unicode позволяют более полное количество символов, что позволяет в одном файле содержать символы сразу нескольких языков одновременно, за счет увеличения размера файла. Notepad++ пытается автоматически определить кодировку файла при открытии, и в то же время позволяет изменять её. Чтобы изменить то, в какой кодировке отображать документ (без изменения самого текста), выберите один из пунктов меню Кодировки→Просмотр в кодировке . . Чтобы преобразовать текст в другую кодировку, выберите один из пунктов меню Кодировки→Преобразовать в . .
Может случиться так, что вы сохраняете файл в определенной кодировке, но после его открытия снова, обнаруживается, что он в другой кодировке. Это происходит, потому что кодировка определяется по содержимому файла и некоторое содержимое является правильным для различных кодировок. Это наиболее заметно, если файл сохранен без специальной метки BOM (Byte Order Mark) указывающей используемую кодировку.
Notepad++ предлагает следующие кодировки: ANSI Старая кодировка, маленький размер файла, но подвержен ошибкам за счет использования различных кодовых страниц UTF-8 В кодировке Unicode большинство западных символов занимают один байт в файле, но для символов другого языка может занять больший размер, от 3 до 4 обычно. При сохранении 3 байта отводится метке BOM. UTF-8 без BOM Тоже что UTF-8, но без добавления метки BOM. Экономия трёх байт в итоге приводит к трудности обнаружения кодировки. Кроме того, именно эта кодировка используется для большинства веб-страниц. UTF-16 Little Endian Все символы размером два байта, пары следуют младшими байтами вперёд. При сохранении 2 байта отводится метке BOM. UTF-16 Big Endian Все символы размером два байта, пары следуют старшими байтами вперёд. При сохранении 2 байта отводится метке BOM.
Кроме того, начиная с версии 5.6, Notepad++ поддерживает изменение набора символов, который используется для отображения текста, именно так, как вы можете изменить его на большинстве веб-браузеров. Эти кодировки доступны во вложенном меню Кодировки→Кодировки ANSI (charset=. ) . Изначальная кодировка нового документа может быть любым видом Unicode, или любой из поддерживаемых форматов ANSI.
Notepad++ использует продвинутые методы анализа для оценки кодировки файла. Вы всегда можете выбрать правильную кодировку, если автоматический выбор оказался ошибочным. Когда файл сохраняется в сессию, текущая кодировка также сохраняется.