

GPU — наше все?
Несмотря на все преимущества, техника GPGPU имеет несколько проблем. Первая из них заключается в очень узкой сфере применения. GPU шагнули далеко вперед центрального процессора в плане наращивания вычислительной мощности и общего количества ядер (видеокарты несут на себе вычислительный блок, состоящий из более чем сотни ядер), однако такая высокая плотность достигается за счет максимального упрощения дизайна самого чипа.
В сущности основная задача GPU сводится к математическим расчетам с помощью простых алгоритмов, получающих на вход не очень большие объемы предсказуемых данных. По этой причине ядра GPU имеют очень простой дизайн, мизерные объемы кэша и скромный набор инструкций, что в конечном счете и выливается в дешевизну их производства и возможность очень плотного размещения на чипе. GPU похожи на китайскую фабрику с тысячами рабочих. Какие-то простые вещи они делают достаточно хорошо (а главное — быстро и дешево), но если доверить им сборку самолета, то в результате получится максимум дельтаплан. Поэтому первое ограничение GPU — это ориентированность на быстрые математические расчеты, что ограничивает сферу применения графических процессоров помощью в работе мультимедийных приложений, а также любых программ, занимающихся сложной обработкой данных (например, архиваторов или систем шифрования, а также софтин, занимающихся флуоресцентной микроскопией, молекулярной динамикой, электростатикой и другими, малоинтересными для линуксоидов вещами).
Вторая проблема GPGPU в том, что адаптировать для выполнения на GPU можно далеко не каждый алгоритм. Отдельно взятые ядра графического процессора довольно медлительны, и их мощь проявляется только при работе сообща. А это значит, что алгоритм будет настолько эффективным, насколько эффективно его сможет распараллелить программист. В большинстве случаев с такой работой может справиться только хороший математик, которых среди разработчиков софта совсем немного.
И третье: графические процессоры работают с памятью, установленной на самой видеокарте, так что при каждом задействовании GPU будет происходить две дополнительных операции копирования: входные данные из оперативной памяти самого приложения и выходные данные из GRAM обратно в память приложения. Нетрудно догадаться, что это может свести на нет весь выигрыш во времени работы приложения (как и происходит в случае с инструментом FlacCL, который мы рассмотрим позже).
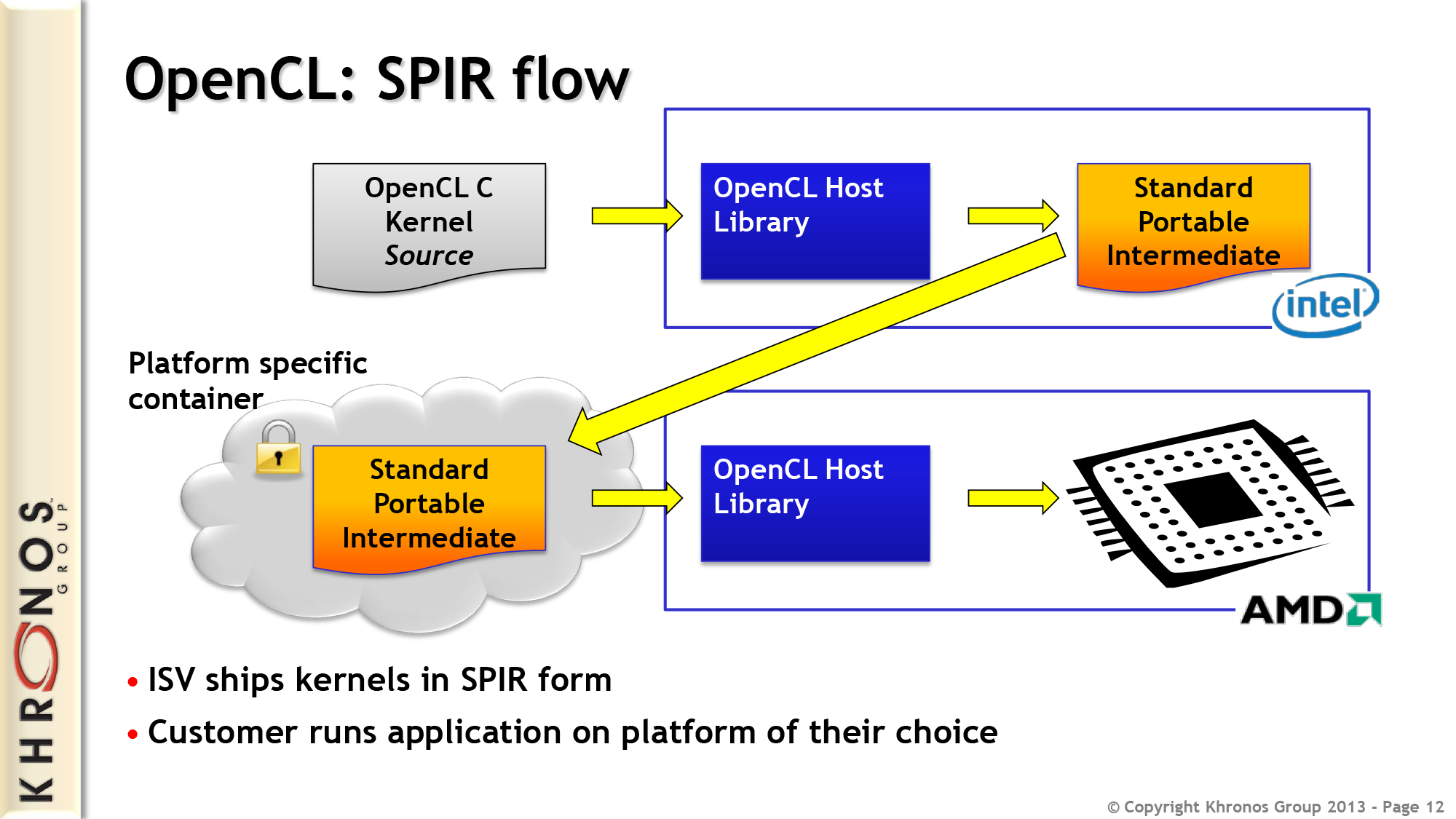
Но и это еще не все. Несмотря на существование общепризнанного стандарта в лице OpenCL, многие программисты до сих пор предпочитают использовать привязанные к производителю реализации техники GPGPU. Особенно популярной оказалась CUDA, которая хоть и дает более гибкий интерфейс программирования (кстати, OpenCL в драйверах nVidia реализован поверх CUDA), но намертво привязывает приложение к видеокартам одного производителя.
Альтернативные варианты использования OpenCL
Если у вас не найдено устройство с поддержкой OpenCL или вы не хотите использовать OpenCL, есть несколько альтернативных вариантов для выполнения вычислений:
- CUDA: Если у вас есть графический процессор NVIDIA, вы можете использовать CUDA для выполнения параллельных вычислений. CUDA поддерживает большинство функциональности, доступной в OpenCL, и предоставляет разработчикам возможность писать нативный код для графического процессора.
- DirectCompute: Если у вас есть графический процессор AMD или NVIDIA, вы можете использовать DirectCompute — технологию, разработанную Microsoft для выполнения параллельных вычислений на графических процессорах. DirectCompute также предоставляет разработчикам доступ к мощности графического процессора, но требует использования специфических API и инструментов.
- OpenMP: OpenMP — это API для создания параллельных программ на общесистемном уровне. Оно позволяет разработчикам использовать несколько процессоров или ядер для ускорения выполнения программы. OpenMP поддерживается на различных платформах и может быть использован совместно с другими технологиями параллельных вычислений.
- OpenACC: OpenACC является открытым стандартом для параллельных вычислений на графических процессорах и других устройствах. Он предоставляет разработчикам возможность параллельно выполнять код, использующий технологии, такие как OpenCL и CUDA, на разных платформах.
Это лишь некоторые из альтернативных вариантов использования OpenCL. В зависимости от ваших потребностей и доступных технологий, вы можете выбрать наиболее подходящий способ выполнения параллельных вычислений.
Рождение GPGPU
Мы все привыкли думать, что единственным компонентом компа, способным выполнять любой код, который ему прикажут, является центральный процессор. Долгое время почти все массовые ПК оснащались единственным процессором, который занимался всеми мыслимыми расчетами, включая код операционной системы, всего нашего софта и вирусов.
Позже появились многоядерные процессоры и многопроцессорные системы, в которых таких компонентов было несколько. Это позволило машинам выполнять несколько задач одновременно, а общая (теоретическая) производительность системы поднялась ровно во столько раз, сколько ядер было установлено в машине. Однако оказалось, что производить и конструировать многоядерные процессоры слишком сложно и дорого. В каждом ядре приходилось размещать полноценный процессор сложной и запутанной x86-архитектуры, со своим (довольно объемным) кэшем, конвейером инструкций, блоками SSE, множеством блоков, выполняющих оптимизации и т.д. и т.п. Поэтому процесс наращивания количества ядер существенно затормозился, и белые университетские халаты, которым два или четыре ядра было явно мало, нашли способ задействовать для своих научных расчетов другие вычислительные мощности, которых было в достатке на видеокарте (в результате даже появился инструмент BrookGPU, эмулирующий дополнительный процессор с помощью вызовов функций DirectX и OpenGL).
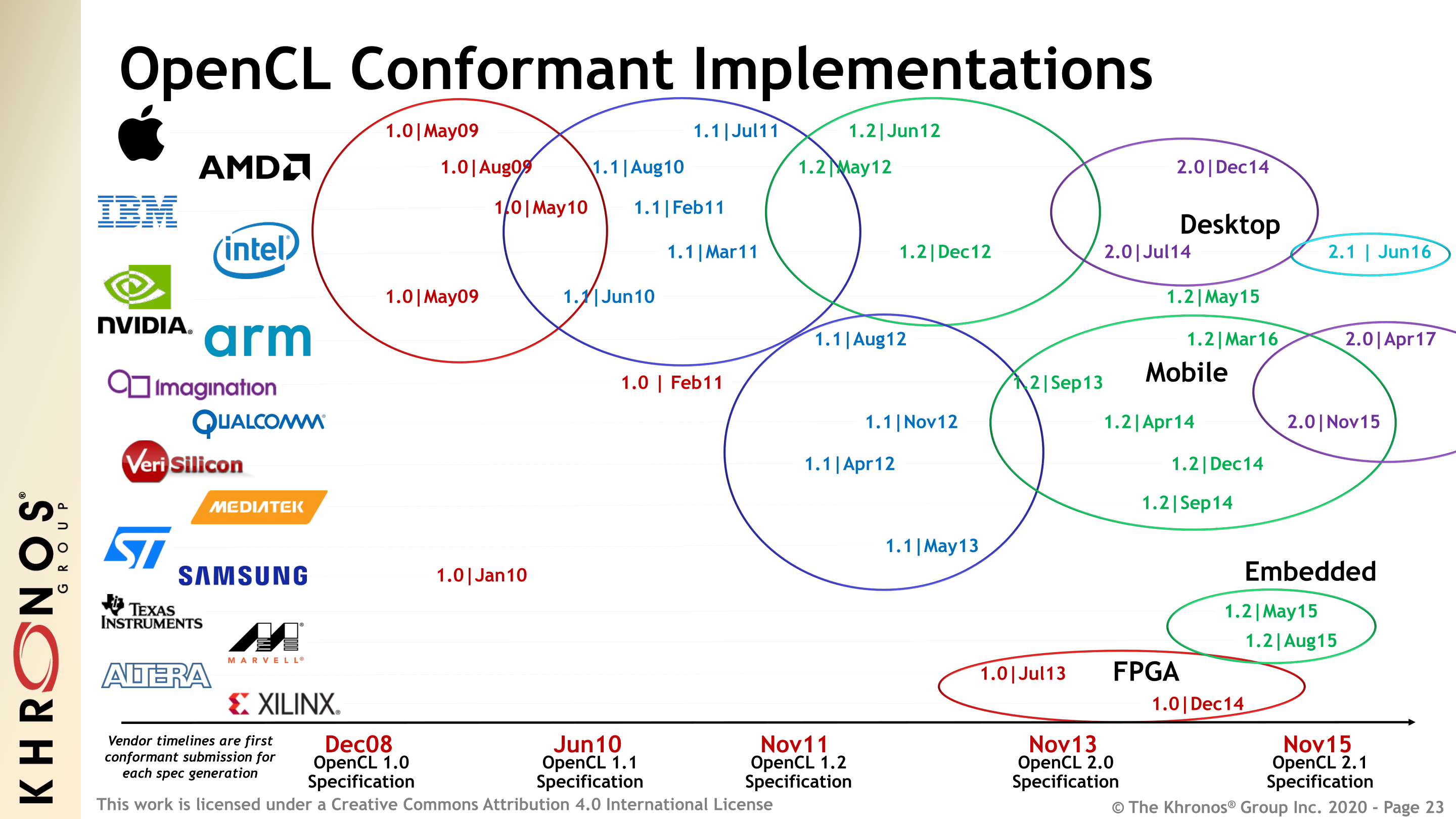
Графические процессоры, лишенные многих недостатков центрального процессора, оказались отличной и очень быстрой счетной машинкой, и совсем скоро к наработкам ученых умов начали присматриваться сами производители GPU (а nVidia так и вообще наняла большинство исследователей на работу). В результате появилась технология nVidia CUDA, определяющая интерфейс, с помощью которого стало возможным перенести вычисление сложных алгоритмов на плечи GPU без каких-либо костылей. Позже за ней последовала ATi (AMD) с собственным вариантом технологии под названием Close to Metal (ныне Stream), а совсем скоро появилась ставшая стандартом версия от Apple, получившая имя OpenCL.
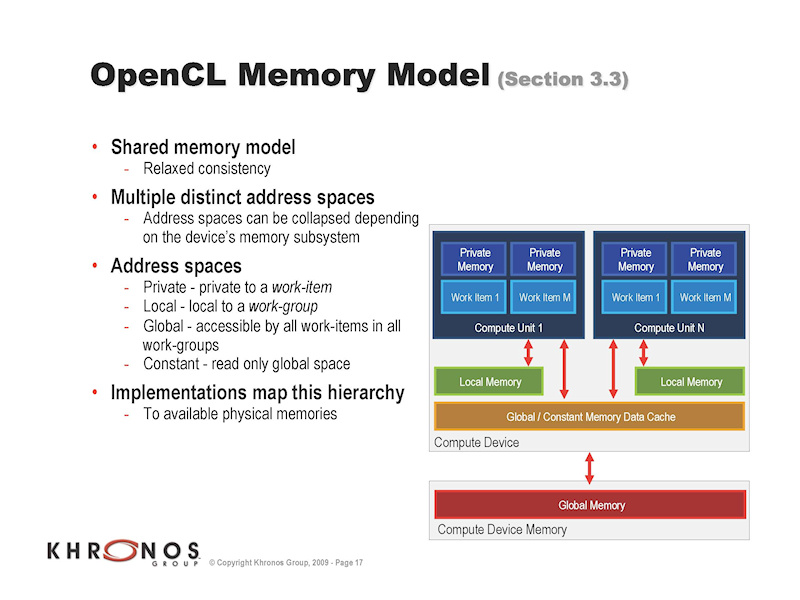
OpenCL-совместимое устройство GPU: техническая характеристика
OpenCL (Open Computing Language, открытый язык вычислений) — фреймворк для параллельных вычислений, который позволяет разработчикам использовать графические процессоры (GPU) для ускорения вычислений в различных областях, таких как научные исследования, компьютерное зрение, машинное обучение и другие.
OpenCL-capable GPU (графический процессор с поддержкой OpenCL) — это GPU, который может выполнять вычисления, используя OpenCL. Здесь рассмотрим технические характеристики OpenCL-совместимого устройства GPU.
Технические характеристики OpenCL-совместимого устройства GPU включают:
- Архитектура GPU: OpenCL-совместимый GPU имеет свою собственную архитектуру, которая определяет его структуру и способность выполнять параллельные вычисления.
- Количество ядер: GPU имеет множество ядер, которые могут выполнять вычисления одновременно. Чем больше ядер у GPU, тем больше вычислительной мощности он может предоставить для параллельных вычислений.
- Частота работы: Это частота, с которой работает GPU. Чем выше частота работы, тем быстрее GPU может выполнить вычисления.
- Объем памяти: GPU имеет собственную память, которая используется для хранения данных и промежуточных результатов. Объем памяти GPU влияет на количество данных, которые можно обрабатывать одновременно.
- Пропускная способность памяти: Пропускная способность памяти определяет скорость доступа к данным в памяти GPU. Чем выше пропускная способность памяти, тем быстрее GPU может получать данные для вычислений.
- Версия OpenCL: GPU может поддерживать различные версии OpenCL. Чем новее версия OpenCL, тем больше функций и оптимизаций может предоставить GPU для выполнения вычислений.
Знание технических характеристик OpenCL-совместимого устройства GPU позволяет разработчикам эффективно использовать его для ускорения вычислений и оптимизации процессов работы в различных областях науки и технологий.
Решение проблемы: возможные действия
Если при работе с программой или приложением возникает ошибка «No OpenCL capable GPU device was found», следуйте следующим действиям для ее устранения:
- Убедитесь, что ваш компьютер или устройство имеет совместимое с OpenCL графическое устройство (GPU). Для этого обратитесь к документации вашего компьютера или проверьте спецификации вашего устройства.
- Убедитесь, что на вашем компьютере или устройстве установлены последние драйверы для графического устройства от производителя. Драйверы обеспечивают поддержку OpenCL и исправления ошибок, поэтому обновленный драйвер может решить проблему. Посетите сайт производителя графического устройства, чтобы найти и загрузить последний драйвер.
- Перезапустите компьютер или устройство после установки или обновления драйверов для графического устройства. Иногда перезапуск может помочь активировать изменения и устранить проблему.
- Если вы добавили или обновили графическую карту или видеочип, убедитесь, что она правильно установлена и подключена к системе. Проверьте физическое подключение и убедитесь, что все кабели и разъемы надежно закреплены.
- Проверьте настройки программы или приложения, с которыми возникает ошибка. Некорректные настройки могут привести к ошибкам OpenCL. Проверьте, есть ли в настройках возможность включить поддержку OpenCL или изменить настройки графического устройства.
- Если все предыдущие действия не решили проблему, попробуйте обратиться к разработчикам программы или приложения за помощью. Они могут иметь дополнительные рекомендации или обновления, которые могут решить проблему.
ImageMagick и OpenCL
Поддержка OpenCL появилась в ImageMagick уже достаточно давно, однако по умолчанию она не активирована ни в одном дистрибутиве. Поэтому нам придется собрать IM самостоятельно из исходников. Ничего сложного в этом нет, все необходимое уже есть в SDK, поэтому сборка не потребует установки каких-то дополнительных библиотек от nVidia или AMD. Итак, скачиваем/распаковываем архив с исходниками:
Далее устанавливаем инструменты сборки:
Запускаем конфигуратор и грепаем его вывод на предмет поддержки OpenCL:
Правильный результат работы команды должен выглядеть примерно так:
Словом «yes» должны быть отмечены либо первые три строки, либо вторые (или оба варианта сразу). Если это не так, значит, скорее всего, была неправильно инициализирована переменная C_INCLUDE_PATH. Если же словом «no» отмечена последняя строка, значит, дело в переменной LD_LIBRARY_PATH. Если все окей, запускаем процесс сборки/установки:

![Opengl [xtreme3d wiki]](https://mtrufa.ru/wp-content/uploads/1/5/3/15371b6948e8f3156806507bf523bf4c.jpeg)


Проверяем, что ImageMagick действительно был скомпилирован с поддержкой OpenCL:
Теперь измерим полученный выигрыш в скорости. Разработчики ImageMagick рекомендуют использовать для этого фильтр convolve:
Некоторые другие операции, такие как ресайз, теперь тоже должны работать значительно быстрее, однако надеяться на то, что ImageMagick начнет обрабатывать графику с бешеной скоростью, не стоит. Пока еще очень малая часть пакета оптимизирована с помощью OpenCL.
Что есть сейчас?
В силу своей молодости, а также благодаря описанным выше проблемам, GPGPU так и не стала по-настоящему распространенной технологией, однако полезный софт, использующий ее возможности, существует (хоть и в мизерном количестве). Одними из первых появились крэкеры различных хэшей, алгоритмы работы которых очень легко распараллелить. Также родились мультимедийные приложения, например, кодировщик FlacCL, позволяющий перекодировать звуковую дорожку в формат FLAC. Поддержкой GPGPU обзавелись и некоторые уже существовавшие ранее приложения, самым заметным из которых стал ImageMagick, который теперь умеет перекладывать часть своей работы на графический процессор с помощью OpenCL. Также есть проекты по переводу на CUDA/OpenCL (не любят юниксоиды ATi) архиваторов данных и других систем сжатия информации. Наиболее интересные из этих проектов мы рассмотрим в следующих разделах статьи, а пока попробуем разобраться с тем, что нам нужно для того, чтобы все это завелось и стабильно работало.
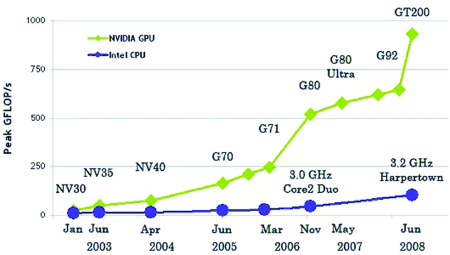 GPU уже давно обогнали x86-процессоры в производительности
GPU уже давно обогнали x86-процессоры в производительности
Во-первых, понадобится видеокарта, поддерживающая технологию CUDA или Stream. Необязательно, чтобы она была топовая, достаточно только, чтобы год ее выпуска был не менее 2009. Полный список поддерживаемых видюшек можно посмотреть в Википедии: en.wikipedia.org/wiki/CUDA и en.wikipedia.org/wiki/AMD_Stream_Processor. Также о поддержке той или иной технологии можно узнать, прочитав документацию, хотя в большинстве случаев будет достаточным взглянуть на коробку из под видеокарты или ноутбука, обычно на нее наклеены различные рекламные стикеры.
Во-вторых, в систему должны быть установлены последние проприетарные драйвера для видеокарты, они обеспечат поддержку как родных для карточки технологий GPGPU, так и открытого OpenCL.
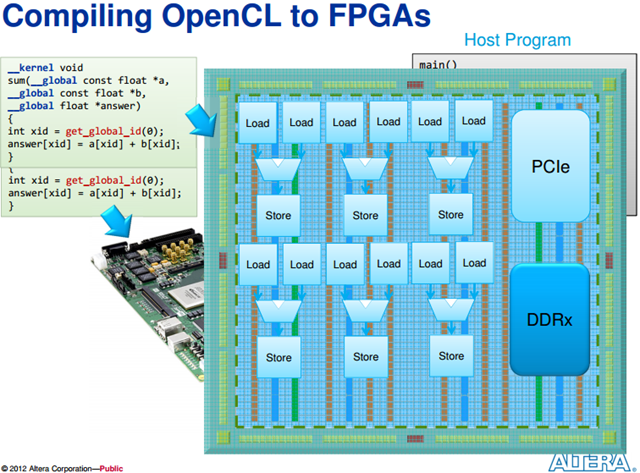
И в-третьих, так как пока дистрибутивостроители еще не начали распространять пакеты приложений с поддержкой GPGPU, нам придется собирать приложения самостоятельно, а для этого нужны официальные SDK от производителей: CUDA Toolkit или ATI Stream SDK. Они содержат в себе необходимые для сборки приложений заголовочные файлы и библиотеки.
MediaTek Dimensity 1080
MediaTek Dimensity 1080 – an 8-core chipset that was announced on October 11, 2022, and is manufactured using a 6-nanometer process technology. It has 2 cores Cortex-A78 at 2600 MHz and 6 cores Cortex-A55 at 2000 MHz.
Benchmarks
Performance tests in popular benchmarks
AnTuTu 10
The AnTuTu Benchmark measures CPU, GPU, RAM, and I/O performance in different scenarios MediaTek Dimensity 1080
| CPU | 177132 |
| GPU | 112841 |
| Memory | 106425 |
| UX | 139138 |
| Total score | 538246 |
GeekBench 6
The GeekBench test shows raw single-threaded and multithreaded CPU performance Single-Core Score Multi-Core Score
| Asset compression | 120.5 MB/sec |
| HTML 5 Browser | 63 pages/sec |
| PDF Renderer | 91.2 Mpixels/sec |
| Image detection | 45.8 images/sec |
| HDR | 75.8 Mpixels/sec |
| Background blur | 6.73 images/sec |
| Photo processing | 21.6 images/sec |
| Ray tracing | 3.29 Mpixels/sec |
Compute Score (GPU)
3DMark
A cross-platform benchmark that assesses graphics performance in Vulkan (Metal) 3DMark Wild Life Performance
| Stability | 99% |
| Graphics test | 13 FPS |
| Score | 2256 |
Gaming
Table of average FPS and graphics settings in mobile games
| PUBG Mobile | 57 FPS |
| Call of Duty: Mobile | 38 FPS |
| Fortnite | 27 FPS |
| Shadowgun Legends | 62 FPS |
| World of Tanks Blitz | 83 FPS |
| Genshin Impact | 37 FPS |
| Mobile Legends: Bang Bang | 86 FPS |
| Device | Xiaomi Redmi Note 12 Pro Plus 5G 1080 x 2400 |
We provide average results. FPS may differ, depending on game version, OS and other factors.
Smartphones
Click on the device name to view detailed information
| Phones with Dimensity 1080 | AnTuTu v10 |
|---|---|
| 1. Infinix Zero 5G 2023 | 545847 |
| 2. Samsung Galaxy A34 5G | 537149 |
| 3. Realme 10 Pro Plus | 535536 |
| 4. Xiaomi Redmi Note 12 Pro Plus 5G | 523594 |
| 5. Xiaomi Redmi Note 12 Explorer Edition | 521302 |
| 6. Xiaomi Redmi Note 12 Pro 5G | 516602 |
Specifications
Detailed specifications of the Dimensity 1080 SoC with Mali-G68 MP4 graphics
CPU
| Architecture | 2x 2.6 GHz – Cortex-A786x 2 GHz – Cortex-A55 |
| Cores | 8 |
| Frequency | 2600 MHz |
| Instruction set | ARMv8.2-A |
| Process | 6 nanometers |
| TDP | 4 W |
| Manufacturing | TSMC |
Graphics
| GPU name | Mali-G68 MP4 |
| Architecture | Valhall 2nd gen |
| GPU frequency | 800 MHz |
| Execution units | 4 |
| FLOPS | 686 Gigaflops |
| Vulkan version | 1.3 |
| OpenCL version | 2.0 |
Multimedia (ISP)
| Neural processor (NPU) | MediaTek APU 3.0 |
| Storage type | UFS 2.1, UFS 2.2, UFS 3.1 |
| Max display resolution | 2520 x 1080 |
| Max camera resolution | 1x 200MP |
| Video capture | 4K at 30FPS |
| Video playback | 4K at 30FPS |
| Video codecs | H.264, H.265, VP9 |
| Audio codecs | AAC, AIFF, CAF, MP3, MP4, WAV |
Connectivity
| 4G support | LTE Cat. 18 |
| 5G support | Yes |
| Download speed | Up to 2770 Mbps |
| Upload speed | Up to 1250 Mbps |
| Wi-Fi | 6 |
| Bluetooth | 5.2 |
| Navigation | GPS, GLONASS, Beidou, Galileo, QZSS, NAVIC |
Info
| Announced | October 2022 |
| Class | Mid range |
| Model number | MT6877V/TTZA |
| Official page | MediaTek Dimensity 1080 official site |
Comments
Anonymous user 26 September 2023 17:20 Antutu GPU score is absolutely wrong. It is at least 130 000 points JanMike 20 June 2023 01:49
I’m not that tech-savvy. I am experiencing unstable Tx and Rx. Can we change the Tx0 and Rx0 channel frequency? My Android is currently set to 2412MHz on both Tx and Rx. My phone is Infinix Zero 5g 2023.



Pfcnf 10 May 2023 07:04 Это тоже 920 MediaTek Critical chipset consumer 05 March 2023 15:09
The Mediatek Dimensity 1080 is so super duper good. The best chipset of all times. No iPhone processor will ever be better than this one. I totally agree with the 2 comments before mine which are absolutely not written by Mediatek employees.
oclHashcat или брутфорс по-быстрому
Как я уже говорил, одними из первых поддержку GPGPU в свои продукты добавили разработчики различных крэкеров и систем брутфорса паролей. Для них новая технология стала настоящим святым граалем, который позволил с легкостью перенести от природы легко распараллеливаемый код на плечи быстрых GPU-процессоров. Поэтому неудивительно, что сейчас существуют десятки самых разных реализаций подобных программ. Но в этой статье я расскажу только об одной из них — oclHashcat.
oclHashcat — это ломалка, которая умеет подбирать пароли по их хэшу с экстремально высокой скоростью, задействуя при этом мощности GPU с помощью OpenCL. Если верить замерам, опубликованным на сайте проекта, скорость подбора MD5-паролей на nVidia GTX580 составляет до 15800 млн комбинаций в секунду, благодаря чему oclHashcat способен найти средний по сложности восьмисимвольный пароль за какие-то 9 минут.
Программа поддерживает OpenCL и CUDA, алгоритмы MD5, md5($pass.$salt), md5(md5($pass)), vBulletin < v3.8.5, SHA1, sha1($pass.$salt), хэши MySQL, MD4, NTLM, Domain Cached Credentials, SHA256, поддерживает распределенный подбор паролей с задействованием мощности нескольких машин.
Автор не раскрывает исходники (что, в общем-то, логично), но у программы есть нормально работающая Linux-версия, которую можно получить на официальной страничке.
Далее следует распаковать архив:
И запустить программу (воспользуемся пробным списком хэшей и пробным словарем):
oclHashcat откроет текст пользовательского соглашения, с которым следует согласиться, набрав «YES». После этого начнется процесс перебора, прогресс которого можно узнать по нажатию <s>. Чтобы приостановить процесс, кнопаем <p>, для возобновления — <r>. Также можно использовать прямой перебор (например, от aaaaaaaa до zzzzzzzz):
И различные модификации словаря и метода прямого перебора, а также их комбинации (об этом можно прочитать в файле docs/examples.txt). В моем случае скорость перебора всего словаря составила 11 минут, тогда как прямой перебор (от aaaaaaaa до zzzzzzzz) длился около 40 минут. В среднем скорость работы GPU (чип RV710) составила 88,3 млн/с.
Архитектура
На базовом уровне, OpenGL — это просто спецификация, то есть документ, описывающий набор функций и их точное поведение. Производители оборудования на основе этой спецификации создают реализации — библиотеки функций, соответствующих набору функций спецификации. Реализация использует возможности оборудования, там где это возможно. Если аппаратура не позволяет реализовать какую-либо возможность, она должна быть эмулирована программно. Аппаратные реализации OpenGL на сегодняшний день существуют для платформ Windows, Unix (Linux, BSD, OSX), PlayStation 3, Android и др. Эти реализации обычно предоставляются изготовителями видеокарт и активно используют возможности последних. Существуют также чисто программные реализации OpenGL.
Стандарт OpenGL с появлением новых технологий позволяет отдельным производителям повышать функциональность библиотеки через механизм расширений. Расширения распространяются с помощью двух составляющих: заголовочный файл, в котором находятся прототипы новых функций и констант, а также драйвер устройства, поставляемого разработчиком. Каждый производитель имеет аббревиатуру, которая используется при именовании его новых функций и констант. Например, компания NVIDIA имеет аббревиатуру NV, которая используется при именовании ее новых функций, как, например, glCombinerParameterfvNV, а также констант: GL_NORMAL_MAP_NV. Может случиться так, что определенное расширение могут реализовать несколько производителей. В этом случае используется аббревиатура EXT, например, glDeleteRenderbuffersEXT. В случае же, когда расширение одобряется консорциумом ARB, оно приобретает аббревиатуру ARB и становится стандартным расширением. Обычно расширения, одобренные консорциумом, включаются в одну из последующих версий спецификации.
OpenGL ориентируется на следующие две задачи:
- скрыть сложности архитектуры 3D-ускорителя, предоставляя разработчику удобный API;
- скрыть различия в возможностях ускорителей, компенсируя недостающие функции при помощи программной эмуляции.
Основным принципом работы OpenGL является получение наборов векторных графических примитивов в виде точек, линий и многоугольников с последующей математической обработкой полученных данных и построением растровой картинки на экране и/или в памяти. Векторные трансформации и растеризация выполняются графическим конвейером (pipeline), который представляет из себя дискретный автомат. Абсолютное большинство команд OpenGL попадают в одну из двух групп: либо они добавляют графические примитивы на вход в конвейер, либо конфигурируют конвейер на различное исполнение трансформаций.
OpenGL является низкоуровневым, процедурным API, что вынуждает программиста диктовать точную последовательность шагов, чтобы построить результирующую растровую графику (императивный подход). Это является основным отличием от дескрипторных подходов, когда вся сцена передается в виде структуры данных (чаще всего дерева), которое обрабатывается и строится на экране. С одной стороны императивный подход требует от программиста глубокого знания законов трехмерной графики и математических моделей, с другой стороны дает свободу внедрения различных инноваций.
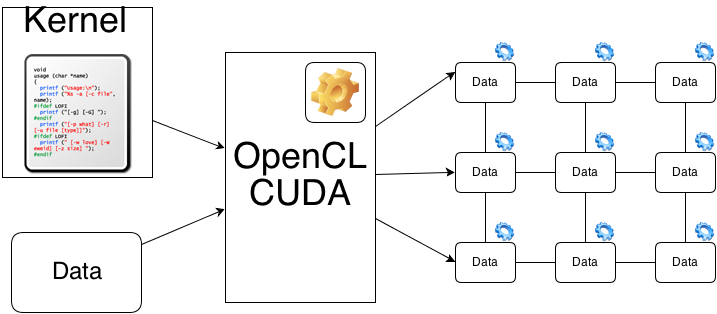
OpenCL: определение и назначение
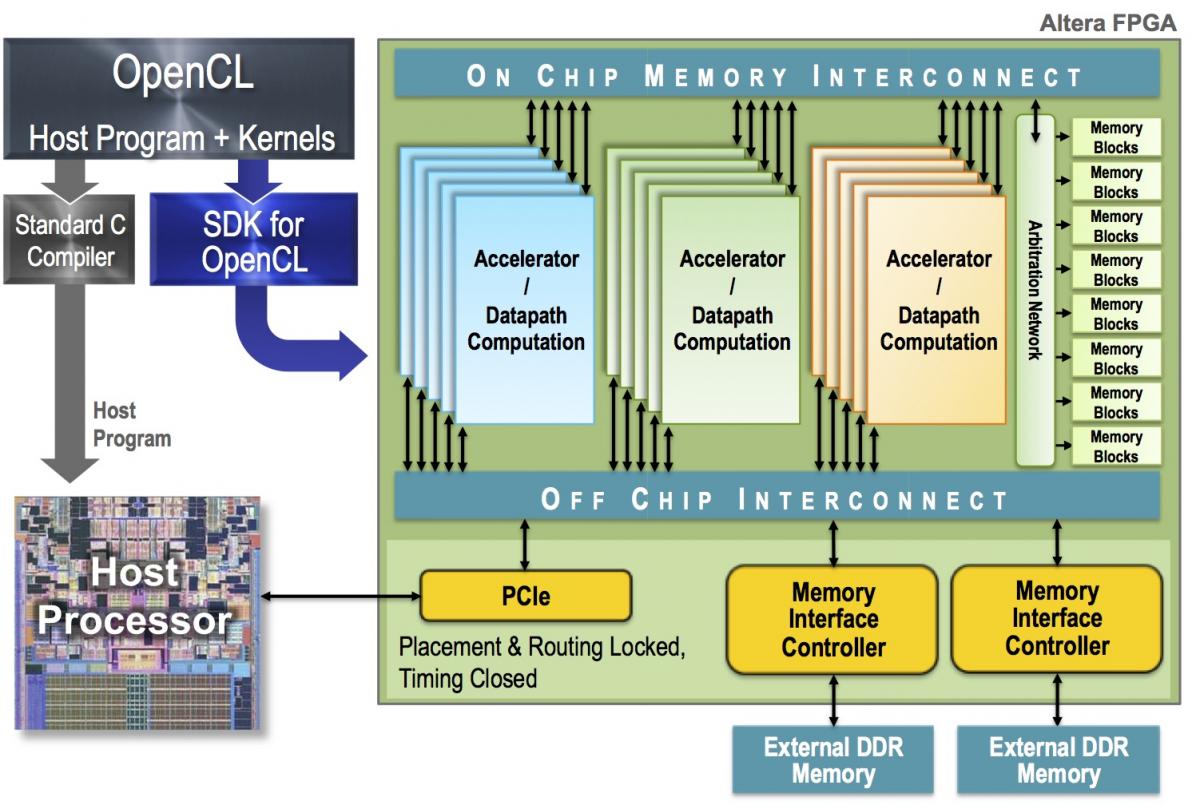
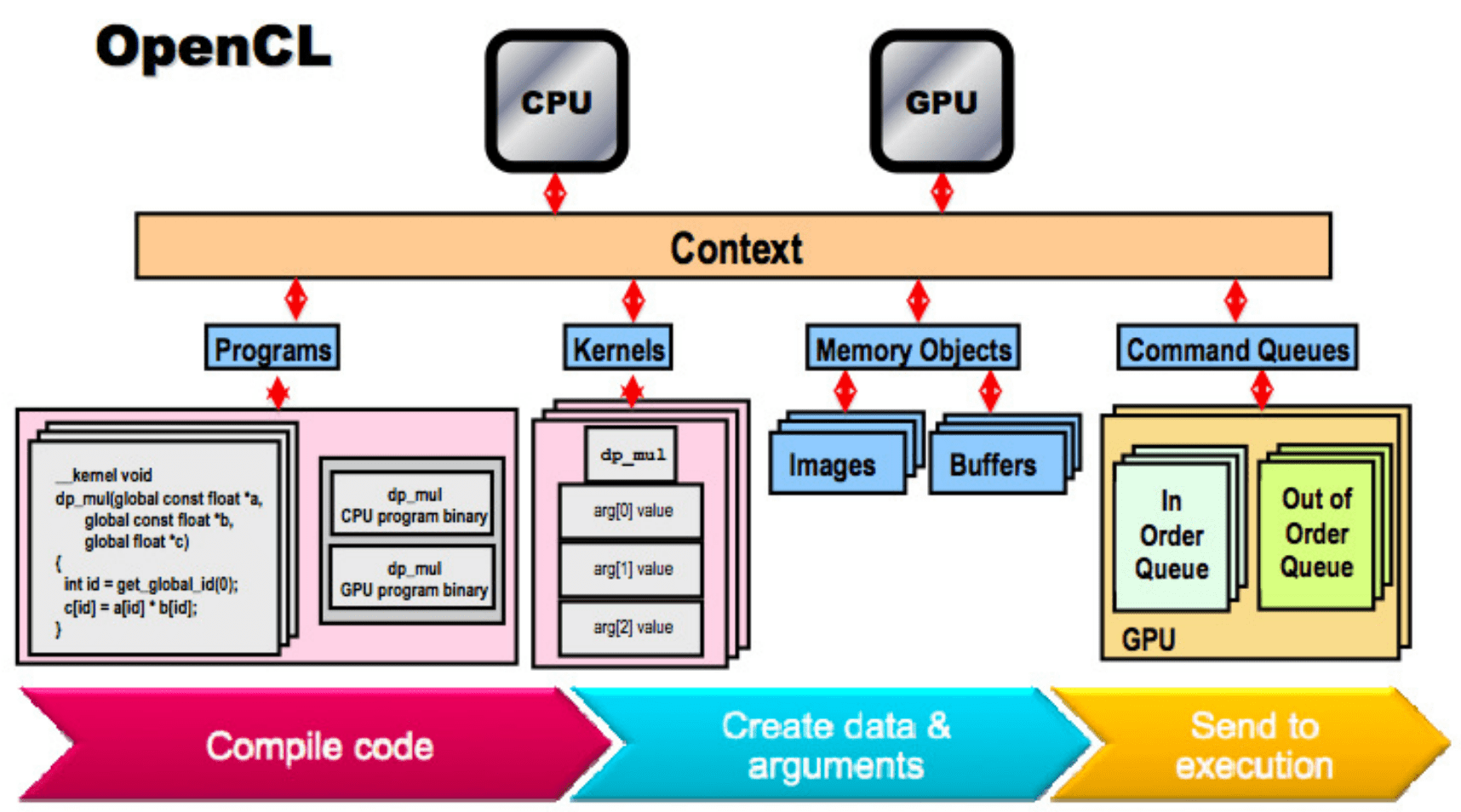
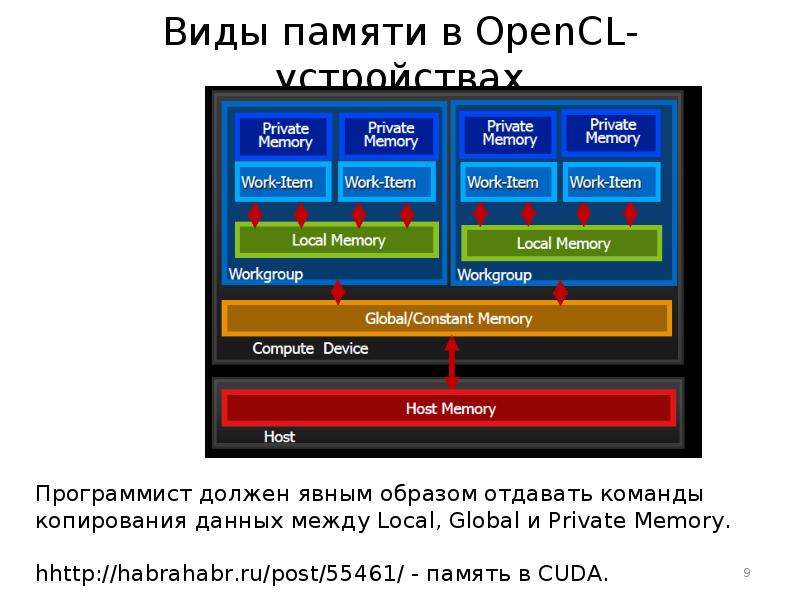
OpenCL (Open Computing Language) – это открытый стандарт для общего параллельного программирования на множестве устройств, включая графические процессоры (GPU), центральные процессоры (CPU), полевые программируемые вентильные матрицы (FPGA) и другие. OpenCL позволяет разработчикам создавать программы, которые могут выполняться одновременно на различных устройствах, используя их вычислительные мощности.
Основная задача OpenCL – обеспечить универсальный программный интерфейс для разработки параллельных вычислений, который мог бы использоваться на различных устройствах и платформах. За счет использования OpenCL, разработчики могут сократить время и усилия, необходимые для адаптации программы к конкретному оборудованию. OpenCL позволяет автоматически использовать доступные ресурсы устройства для параллельной обработки задач, что повышает скорость и эффективность вычислений.
Используя OpenCL, разработчики могут распределить задачи между различными вычислительными устройствами, такими как GPU и CPU, чтобы достичь наилучшей производительности. При этом, OpenCL предоставляет специальные инструменты для оптимизации и контроля процесса параллельной обработки, что позволяет эффективно использовать ресурсы устройства и достичь максимальной производительности в задачах, требующих высокой вычислительной мощности.
Преимущества использования OpenCL:
- Параллельная обработка задач на различных вычислительных устройствах, что позволяет сократить время выполнения и повысить производительность программы;
- Универсальность и переносимость программ, благодаря использованию общего стандарта OpenCL;
- Поддержка различных устройств и платформ, включая GPU, CPU, FPGA и другие;
- Использование мощностей устройства для параллельной обработки задач и оптимизации производительности программы;
- Простота и удобство разработки параллельных программ с использованием инструментов OpenCL.
Использование OpenCL в разработке программного обеспечения позволяет раскрыть потенциал параллельных вычислений и повысить производительность приложения. OpenCL активно применяется в таких областях, как научные и исследовательские вычисления, машинное обучение, компьютерное зрение, криптография и другие, где требуется обработка больших объемов данных и параллельное выполнение вычислительно сложных задач.
Ставим CUDA Toolkit
Идем по вышеприведенной ссылке и скачиваем CUDA Toolkit для Linux (выбрать можно из нескольких версий, для дистрибутивов Fedora, RHEL, Ubuntu и SUSE, есть версии как для архитектуры x86, так и для x86_64). Кроме того, там же надо скачать комплекты драйверов для разработчиков (Developer Drivers for Linux, они идут первыми в списке).



Запускаем инсталлятор SDK:
Когда установка будет завершена, приступаем к установке драйверов. Для этого завершаем работу X-сервера:
Открываем консоль <Ctrl+Alt+F5> и запускаем инсталлятор драйверов:
После окончания установки стартуем иксы:
Чтобы приложения смогли работать с CUDA/OpenCL, прописываем путь до каталога с CUDA-библиотеками в переменную LD_LIBRARY_PATH:
Или, если ты установил 32-битную версию:
Также необходимо прописать путь до заголовочных файлов CUDA, чтобы компилятор их нашел на этапе сборки приложения:
Все, теперь можно приступить к сборке CUDA/OpenCL-софта.