
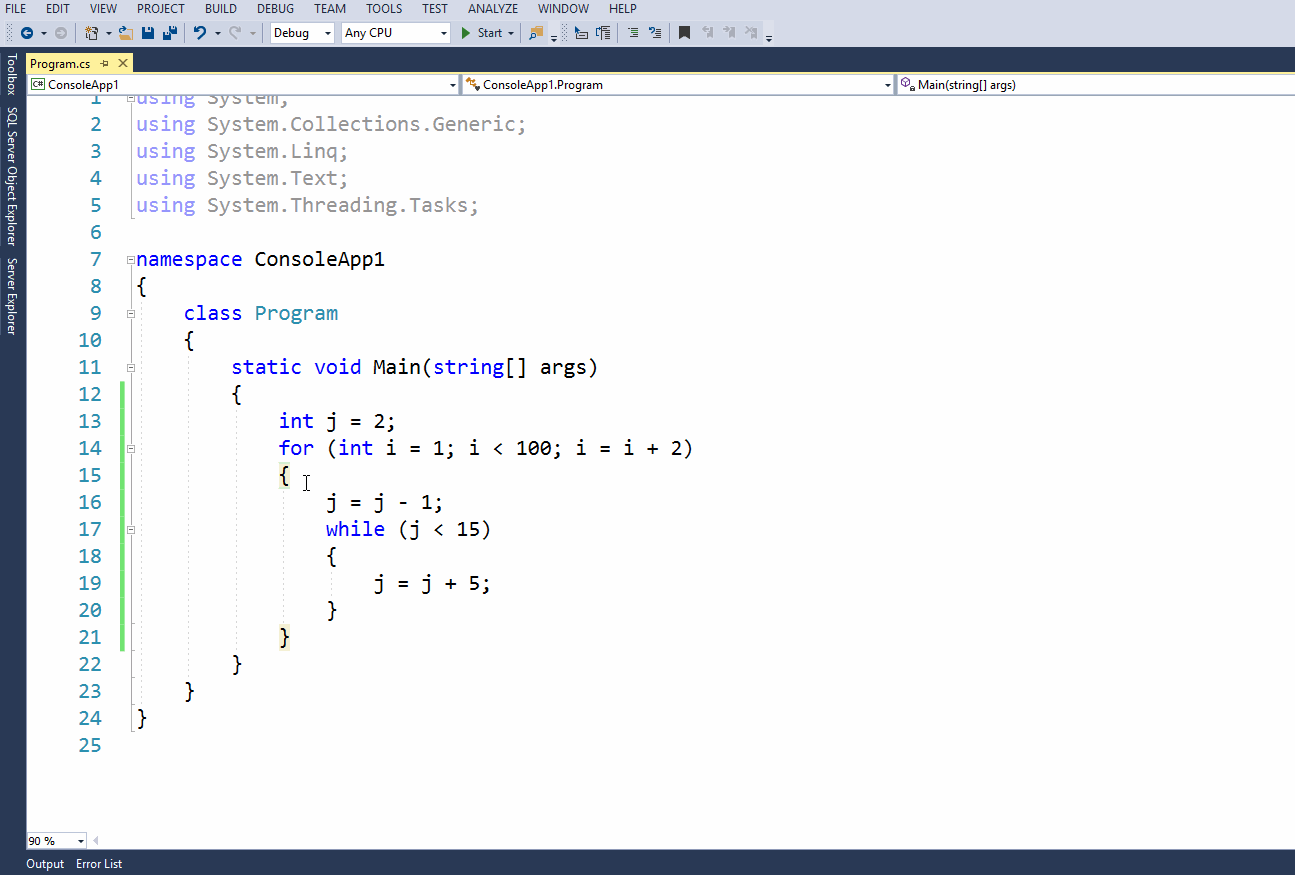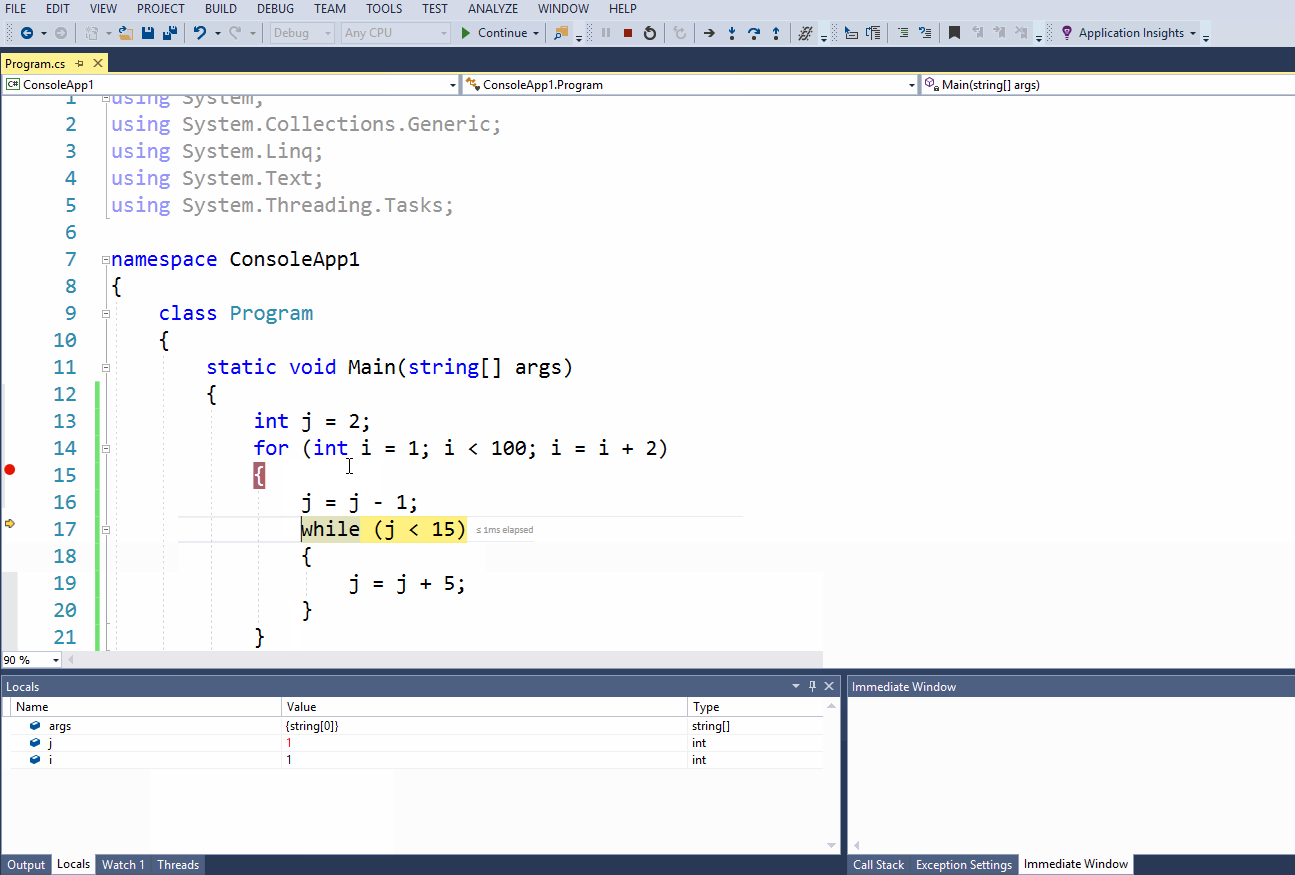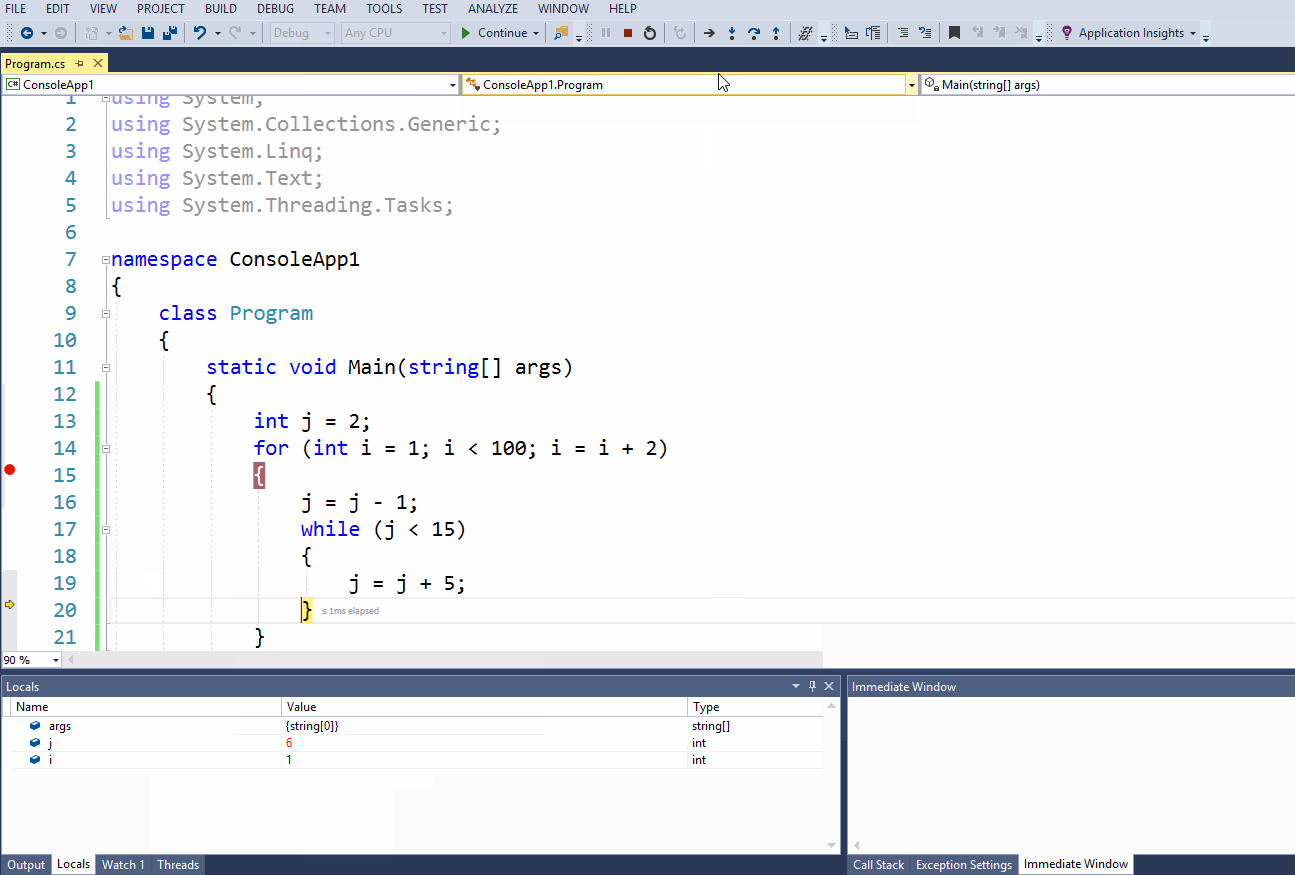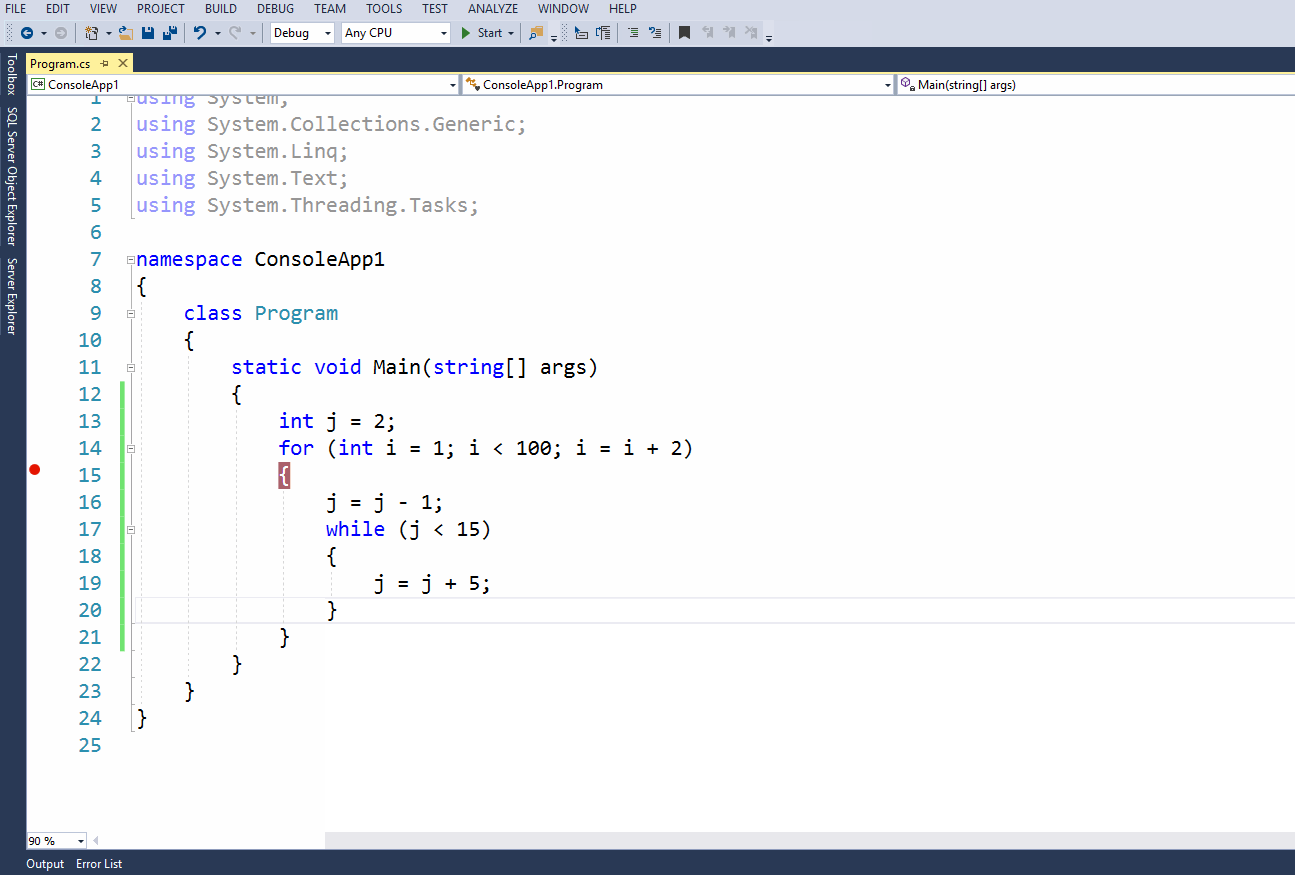
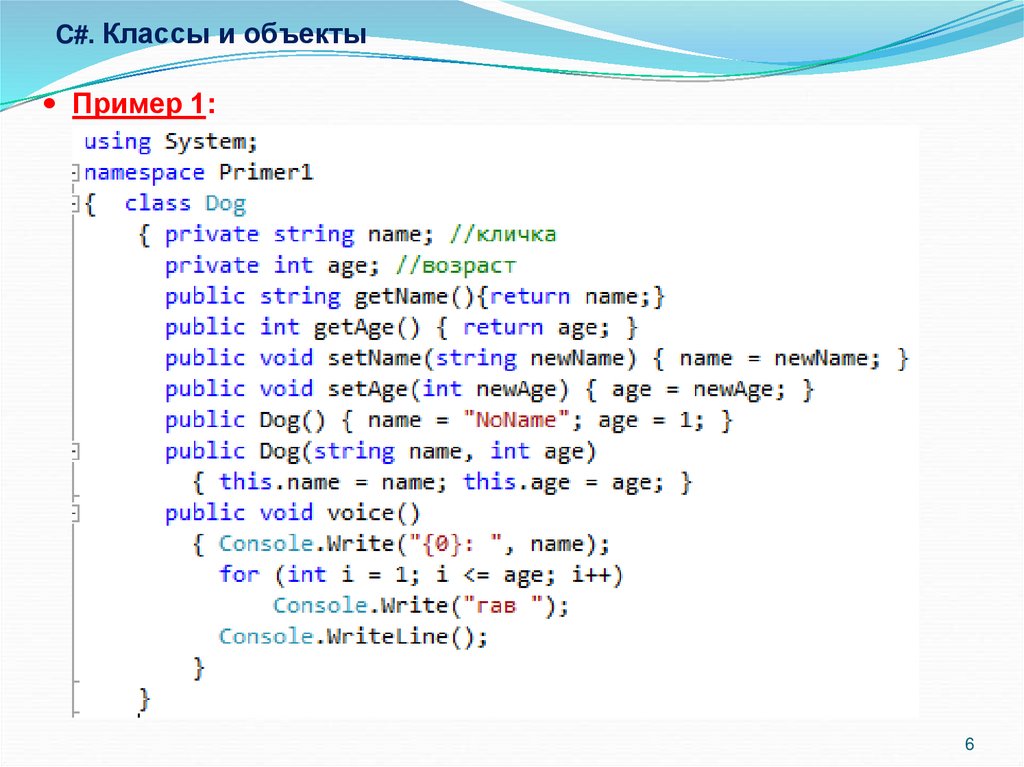
8.1 Введение
Разработка и реализация стандартных средств ввода/вывода
для языка программирования
зарекомендовала себя как заведомо
трудная работа. Традиционно
средства ввода/вывода
разрабатывались исключительно для
небольшого числа встроенных типов
данных. Однако в C++ программах
обычно используется много типов,
определенных пользователем, и
нужно обрабатывать ввод и вывод
также и значений этих типов.
Очевидно, средство ввода/вывода
должно быть простым, удобным,
надежным в употреблении,
эффективным и гибким, и ко всему
прочему полным. Ничье решение еще
не смогло угодить всем, поэтому у
пользователя должна быть
возможность задавать
альтернативные средства
ввода/вывода и расширять
стандартные средства ввода/вывода
применительно к требованиям
приложения.
C++ разработан так, чтобы у
пользователя была возможность
определять новые типы столь же
эффективные и удобные, сколь и
встроенные типы. Поэтому
обоснованным является требование
того, что средства ввода/вывода для
C++ должны обеспечиваться в C++ с
применением только тех средств,
которые доступны каждому
программисту. Описываемые здесь
средства ввода/вывода представляют
собой попытку ответить на этот
вызов.
Средства ввода/вывода связаны
исключительно с обработкой
преобразования типизированных
объектов в последовательности
символов и обратно. Есть и другие
схемы ввода/вывода, но эта является
основополагающей в системе UNIX, и
большая часть видов бинарного
ввода/вывода обрабатывается через
рассмотрение символа просто как
набор бит, при этом его
общепринятая связь с алфавитом
игнорируется. Тогда для
программиста ключевая проблема
заключается в задании соответствия
между типизированным объектом и
принципиально не типизированной
строкой.
Обработка и встроенных и
определенных пользователем типов
однородным образом и с гарантией
типа достигается с помощью одного
перегруженного имени функции для
набора функций вывода. Например:
put(cerr,"x = "); // cerr - поток вывода ошибок put(cerr,x); put(cerr,"\n");
Тип параметра определяет то, какая
из функций put будет вызываться для
каждого параметра. Это решение
применялось в нескольких языках.
Однако ему недостает лаконичности.
Перегрузка операции << значением «поместить в» дает более хорошую запись и
позволяет программисту выводить ряд объектов одним оператором. Например:
cerr << "x=" << x << " \n";
где cerr — стандартный поток вывода
ошибок. Поэтому, если x является int
со значением 123, то этот оператор
напечатает в стандартный поток
вывода ошибок
x = 123
и символ новой строки. Аналогично,
если X принадлежит определенному
пользователем типу complex и имеет
значение (1,2.4), то приведенный выше
оператор напечатает в cerr
x = 1,2.4)
Этот метод можно применять всегда,
когда для x определена операция <<, и пользователь может определять операцию << для нового типа.
8.1 Введение
Разработка и реализация стандартных средств ввода/вывода для
языка программирования зарекомендовала себя как заведомо трудная
работа. Традиционно средства ввода/вывода разрабатывались
исключительно для небольшого числа встроенных типов данных. Однако
в C++ программах обычно используется много типов, определенных
пользователем, и нужно обрабатывать ввод и вывод также и значений
этих типов. Очевидно, средство ввода/вывода должно быть простым,
удобным, надежным в употреблении, эффективным и гибким, и ко всему
прочему полным. Ничье решение еще не смогло угодить всем, поэтому у
пользователя должна быть возможность задавать альтернативные
средства ввода/вывода и расширять стандартные средства ввода/вывода
применительно к требованиям приложения.
C++ разработан так, чтобы у пользователя была возможность
определять новые типы столь же эффективные и удобные, сколь и
встроенные типы. Поэтому обоснованным является требование того, что
средства ввода/вывода для C++ должны обеспечиваться в C++ с
применением только тех средств, которые доступны каждому
программисту. Описываемые здесь средства ввода/вывода представляют
собой попытку ответить на этот вызов.
Средства ввода/вывода связаны исключительно с
обработкой преобразования типизированных объектов в
последовательности символов и обратно. Есть и другие схемы
ввода/вывода, но эта является основополагающей в системе UNIX, и
большая часть видов бинарного ввода/вывода обрабатывается через
рассмотрение символа просто как набор бит, при этом его
общепринятая связь с алфавитом игнорируется. Тогда для программиста
ключевая проблема заключается в задании соответствия между
типизированным объектом и принципиально не типизированной строкой.
Обработка и встроенных и определенных пользователем типов
однородным образом и с гарантией типа достигается с помощью одного
перегруженного имени функции для набора функций вывода. Например:
put(cerr,"x = "); // cerr - поток вывода ошибок put(cerr,x); put(cerr,"\n");
x = 123
x = 1,2.4)
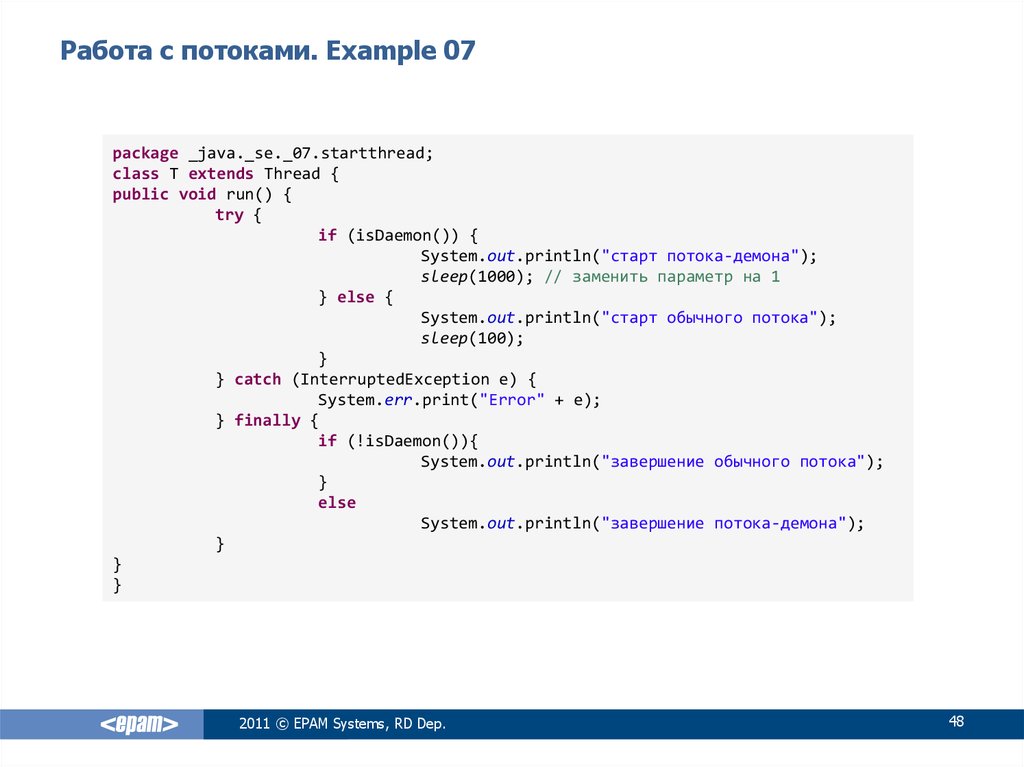
Проектирование многопоточных процессов в языке Си

В этом разделе рассмотрим подходы к созданию эффективных и надежных многопоточных процессов на языке Си. Работа с параллельными потоками позволяет оптимизировать производительность программы, а также использовать вычислительные ресурсы компьютера более эффективно.
Разработка многопоточных приложений требует особой организации кода и обработки синхронизации между потоками. В данном разделе мы рассмотрим различные механизмы синхронизации, такие как мьютексы, семафоры и условные переменные. Также будут рассмотрены возможности обработки ошибок и управления ресурсами при работе с потоками.
- Архитектура многопоточных процессов
- Механизмы синхронизации потоков
- Обработка ошибок и управление ресурсами
- Оптимизация производительности многопоточных процессов
В данном разделе вы найдете практические рекомендации и примеры кода, которые помогут вам разработать эффективные и надежные многопоточные процессы на языке Си. Понимание принципов работы потоков и умение применять их в своих проектах позволит вам создавать программы, обрабатывающие большие объемы данных и выполняющие сложные вычисления в параллельных потоках.
Роль параллельных исполнительных процессов в языке C

Память компьютера и его процессорная мощность позволяют выполнять несколько задач одновременно. Использование параллельных исполнительных процессов в языке C позволяет оптимизировать время выполнения программ, повысить их эффективность и масштабируемость.
- Увеличение производительности: параллельные потоки могут выполнять различные части программы одновременно, что позволяет использовать полную мощность процессора и ускоряет выполнение задач.
- Разделение задач: потоки позволяют разбить сложные задачи на более маленькие подзадачи, которые могут быть решены параллельно. Это упрощает разработку и реализацию программ.
- Взаимодействие и синхронизация: параллельные потоки могут обмениваться информацией и синхронизировать свою работу, что позволяет решать задачи совместно и эффективно.
- Параллельная обработка данных: использование потоков в языке C позволяет эффективно обрабатывать большие объемы данных, распределяя их между несколькими потоками для параллельной обработки.
- Улучшение интерактивности: параллельные потоки позволяют выполнять задачи в фоновом режиме, не блокируя пользовательский интерфейс, что улучшает отзывчивость программ.
Таким образом, использование параллельных исполнительных процессов в языке C является мощным инструментом для оптимизации работы программ, повышения эффективности и улучшения взаимодействия с пользователем.
Работа с файлами в си
В этой статье мы узнаем, как считывать данные из файлов и записывать информацию в файлы в программах си. Файлы в си используются для того, чтобы сохранять результат работы программы си и использовать его при новом запуске программы . Например можно сохранять результаты вычислений , статистику игр.
Чтобы работать с файлами в си необходимо подключить библиотеку stdio.h#include
Чтобы работать с файлом в си необходимо задать указатель на файл по образцуFILE *имя указателя на файл;
Например FILE *fin;
Задает указатель fin на файл
Дальше необходимо открыть файл и привязать его к файловому указателю. Для открытия файла в си на чтение используется командаИмя указателя на файл= fopen(«путь к файлу», «r»);
Например следующая командаfin = fopen(«C:\\Users\\user\\Desktop\\data.txt», «r»);
откроет файл data.txt, находящийся на рабочем столе по пути C:UsersuserDesktop Чтобы узнать путь к файлу можно выбрать файл мышью нажать на правую кнопку мыши и выбрать свойства файла. В разделе Расположение будет указан путь к файлу
Обратите внимание , что в си путь указывается с помощью двух слешей.
После работы с файлом в си , необходимо его закрыть с помощью командыfclose(имя указателя на файл)
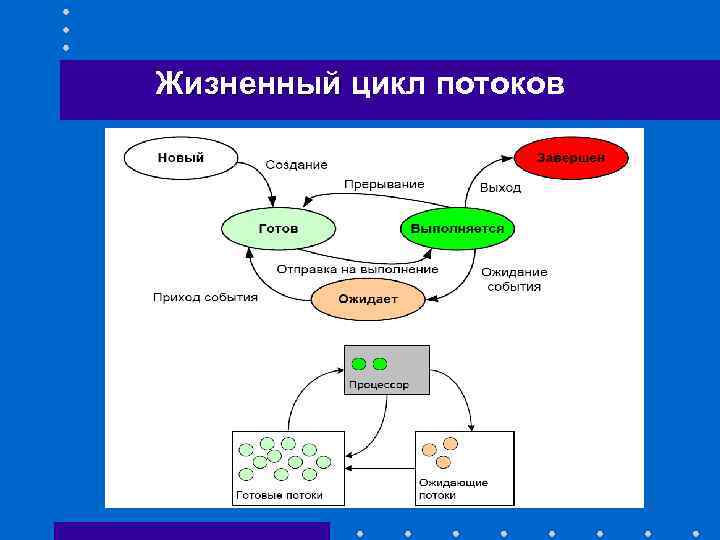
Потоки и параллельные вычисления
Параллельные вычисления основаны на идее разделения задач на небольшие участки, выполняемые независимо друг от друга. Подобное разделение позволяет выполнить несколько задач одновременно, что повышает эффективность программы за счет распределения вычислительных задач между разными потоками.
- Преимущества параллельных вычислений:
- Ускорение работы приложения за счет одновременного выполнения различных операций
- Повышение отзывчивости программы благодаря возможности выполнять несколько задач одновременно
- Эффективное использование многоядерных процессоров и многопроцессорных систем
Основные концепции параллельных вычислений:
- Параллелизм задач: разделение большой задачи на небольшие части, которые могут выполняться параллельно
- Синхронизация: управление доступом к общим ресурсам, чтобы избежать конфликтов и некорректных результатов
- Взаимодействие: передача данных и обмен информацией между потоками для выполнения совместных операций
Для работы с потоками в языке C доступны различные средства, включая библиотеки и механизмы синхронизации. Разрешение возможности параллельных вычислений требует правильного выбора подходящих инструментов и алгоритмов, а также аккуратного управления ресурсами приложения.
Использование параллельных вычислений и потоков в языке C может значительно улучшить производительность программы и повысить ее отзывчивость в современных вычислительных системах с многоядерными процессорами. Однако необходимо учитывать особенности алгоритмов и задач, чтобы эффективно использовать потоки и избежать возможных проблем, связанных с конкурентным доступом к общим ресурсам и синхронизацией операций.
8.8 Упражнения
- (*1.5) Считайте файл чисел с плавающей точкой, составьте из
пар считанных чисел комплексные числа и выведите комплексные
числа. - (*1.5) Определите тип name_and_address (имя_и_адрес).
Определите для него >. Скопируйте поток объектов
name_and_address. - (*2) Постройте несколько функций для запроса и чтения
различного вида информации. Простейший пример — функция
y_or_n() в Идеи: целое, число с плавающей точкой, имя файла, почтовый адрес, дата, личные данные и т.д. Постарайтесь
сделать их защищенными от дурака. - (*1.5) Напишите программу, которая печатает (1) все буквы в
нижнем регистре, (2) все буквы, (3) все буквы и цифры, (4) все
символы, которые могут встречаться в идентификаторах C++ на
вашей системе, (5) все символы пунктуации, (6) целые значения
всех управляющих символов, (7) все символы пропуска, (8) целые
значения всех символов пропуска, и (9) все печатаемые символы. - (*4) Реализуйте стандартную библиотеку ввода/вывода C
() с помощью стандартной библиотеки ввода/вывода C++
(). - (*4) Реализуйте стандартную библиотеку ввода/вывода C++
() с помощью стандартной библиотеки ввода/вывода C
(). - (*4) Реализуйте стандартные библиотеки C и C++ так, чтобы они
могли использоваться одновременно. - (*2) Реализуйте класс, для которого [] перегружено для
реализации случайного чтения символов из файла. - (*3) Как Упражнение 8, только сделайте, чтобы [] работало и
для чтения, и для записи. Подсказка: сделайте, чтобы []
возвращало объект «дескрипторного типа», для которого
присваивание означало бы присвоить файлу через дескриптор, а
неявное преобразование в char означало бы чтение из файла
через дескриптор. - (*2) Как Упражнение 9, только разрешите [] индексировать
записи некоторого вида, а не символы. - (*3) Сделайте обобщенный вариант класса, определенного в
Упражнении 10. - (*3.5) Разработайте и реализуйте операцию ввода по
сопоставлению с образцом. Для спецификации образца используйте
строки формата в духе printf. Должна быть возможность
попробовать сопоставить со вводом несколько образцов для
нахождения фактического формата. Можно было бы вывести класс
ввода по образцу из istream. - (*4) Придумайте (и реализуйте) вид образцов, которые намного
лучше.
Потоки в языке программирования C
Потоки в языке C представляют собой удобный способ работы с вводом и выводом данных․ Они позволяют программам обмениваться информацией с внешним миром․ В C потоки представляют собой абстракцию, которая представляет последовательность байтов, доступных для чтения или записи․ Они позволяют обрабатывать потенциально неограниченные объемы данных․
Потоки в Си исполняются последовательно, то есть одна операция чтения или записи выполняется после другой․ Однако, с помощью многопоточности, можно достичь параллельного выполнения кода и повысить производительность программы․ Многопоточность в Си позволяет создавать независимые пути исполнения и обеспечивает возможность одновременного выполнения различных задач․
Понятие потоков в языке C
В языке C потоки представляют собой удобный способ работы с вводом и выводом данных․ Они позволяют программам взаимодействовать с внешним миром и обмениваться информацией․ Потоки в C являются абстракцией, которая представляет собой последовательность байтов, доступных для чтения или записи․
Потоки в C могут быть ориентированы на ввод, вывод или как комбинация обоих․ Стандартные потоки ввода-вывода в C ⏤ это stdin, stdout и stderr, которые соответствуют стандартному вводу, стандартному выводу и выводу ошибок соответственно․
Работа с потоками в C осуществляется с помощью функций стандартной библиотеки, таких как printf, scanf, fopen, fclose и других․ Они позволяют осуществлять чтение и запись данных с помощью потоков, управлять их открытием и закрытием, а также выполнять другие операции, связанные с работой с потоками․
Примеры использования многопоточности в языке C
Многопоточность в языке C позволяет создавать параллельные пути исполнения и повышать производительность программы․ Вот несколько примеров использования многопоточности в C⁚
- Создание потоков для выполнения различных задач, например, вычислений или обработки данных․
- Использование потоков для параллельной обработки больших объемов данных, ускоряя выполнение программы․
- Использование потоков для одновременной обработки сетевых запросов или обработки пользовательского ввода-вывода․
- Использование потоков для создания многопользовательских приложений или игр, которые требуют параллельной обработки․
Многопоточность в C реализуется с помощью библиотеки pthreads, которая предоставляет функции для создания, управления и синхронизации потоков․ Это позволяет программистам эффективно использовать ресурсы компьютера и повышать производительность своих приложений․
Оператор fscanf()
Для считывания слова из файла в си используется команда fscanf(). Эта команда аналогична команде ввода информации с клавиватуры в си scanf() только первый параметр это указатель на файлfscanf(указатель на файл,»%формат ввода данных1% форматввода данных2…»,&перменная1,&переменная2…);
Например команда fscanf(fin,»%d%d%d»,&a,&b,&c);
считает из файла, который привязан к указателю на файл fin строку из трех целочисленных переменных
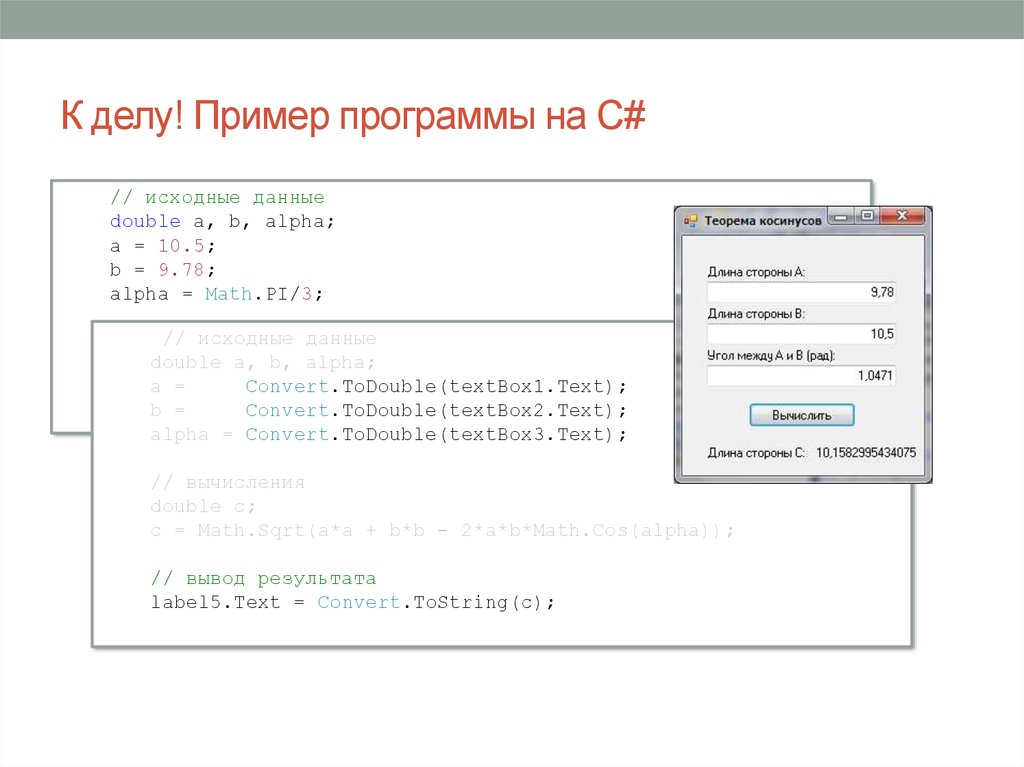
Разберем пример программы, которая считывает из текстового файла data.txt в которые записаны три столбца цифр информацию и записывает ее в массивы. Для каждого столбца информации свой массив. Подробно о работе с массивами в Си.#include <stdio.h>
#include <conio.h>
main()
{ int a;
int b;
int c;
int i;
// определяем указатель на файл
FILE *fin;
// открываем файл на чтение
fin = fopen(«C:\\Users\\user\\Desktop\\data.txt», «r»);
// построчное считывание из файла
for (i=0;i<3;i++)
{
// считывание строки из трех значений файла и запись в массивы
fscanf(fin,»%d%d%d»,&a,&b,&c);
}
// вывод массивов на экран
for (i=0;i<3;i++)
{
printf(«%d %d %d\n»,a,b,c);
}
getch();
// закрытие файла
fclose(fin);
}





Создание и управление потоками в С
В языке С можно создавать и управлять потоками выполнения с помощью библиотеки pthreads (POSIX threads). Потоки позволяют выполнять несколько задач или операций одновременно, что повышает эффективность работы программы.
Для создания потока необходимо выполнить следующие шаги:
- Включить заголовочный файл <pthread.h>.
- Объявить переменную типа pthread_t, которая будет представлять поток.
- Создать поток с помощью функции pthread_create.
Пример кода:
В данном примере создается один поток, функция thread_function является точкой входа в поток и содержит код, который будет выполняться внутри потока. После создания потока, функция pthread_join ожидает завершения выполнения потока.
Для работы с потоками также важно знать, как передавать и получать данные между потоками:
- Синхронизация потоков — с помощью мьютексов, условных переменных и семафоров можно управлять доступом к общим данным, чтобы избежать гонок данных.
- Взаимодействие между потоками — потоки могут обмениваться данными, используя различные механизмы, такие как очереди сообщений, разделяемая память или файлы.
Правильное управление потоками и синхронизация доступа к общим данным — это важные аспекты при разработке многопоточных программ в С. Они помогают избежать ошибок и обеспечить корректное взаимодействие между потоками.
Таким образом, создание и управление потоками в С с помощью библиотеки pthreads позволяет эффективно использовать многопоточность для выполнения параллельных задач и повысить производительность программы.
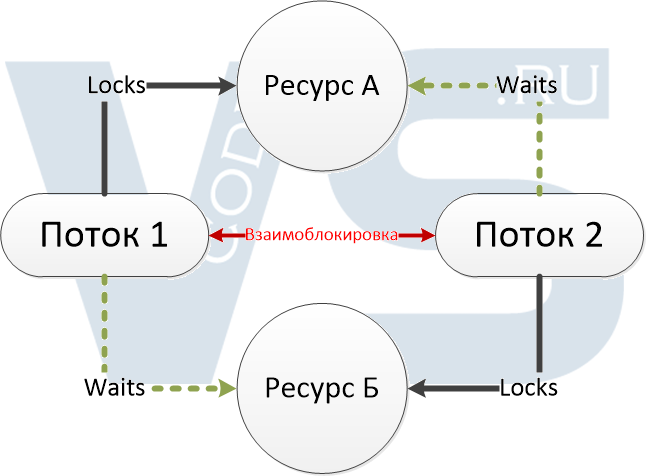
Синхронизация и многопоточность
В C присутствует поддержка работы с потоками и многопоточностью, что позволяет решать задачи параллельно. Однако, при работе с несколькими потоками может возникнуть проблема с синхронизацией доступа к общим ресурсам. Для предотвращения конфликтов и обеспечения корректной работы потоков существуют различные средства синхронизации.
Синхронизация доступа к общим данным может осуществляться с помощью таких средств, как:
- Мьютексы (mutex) — объекты, предназначенные для ограничения доступа к общему ресурсу только одному потоку в определенный момент времени. Путем блокировки и разблокировки мьютекса потоки синхронизируют свои действия. Мьютекс может находиться в двух состояниях: заблокированном и разблокированном.
- Семафоры (semaphore) — объекты, предназначенные для контроля доступа к общему ресурсу нескольким потокам одновременно, определенным количеством потоков. Семафор используется для управления количеством разрешений на доступ к ресурсу.
- Условные переменные (condition variable) — объекты, позволяющие потокам дожидаться выполнения определенного условия перед продолжением своей работы. Условные переменные позволяют реализовывать более сложные сценарии синхронизации и взаимодействия между потоками.
- Барьеры (barrier) — объекты, которые позволяют определенному количеству потоков синхронизироваться на определенном этапе выполнения программы. Барьеры блокируют потоки до тех пор, пока не будут выполнены определенные условия для продолжения работы.
Правильное использование этих и других средств синхронизации позволяет создавать безопасные и эффективные программы с многопоточной обработкой. Однако, неправильное использование средств синхронизации может привести к проблемам, таким как состояние гонки (race condition), блокировки (deadlock) и взаимная блокировка (deadlock).
При разработке программ с использованием многопоточности, особенно в C, необходимо учитывать особенности работы с потоками и правильно применять средства синхронизации для избежания проблем и обеспечения корректной и эффективной работы.
8.8 Упражнения
- (*1.5) Считайте файл чисел с плавающей точкой,
составьте из пар считанных
чисел комплексные числа и
выведите комплексные числа. - (*1.5) Определите тип name_and_address (имя_и_адрес).
Определите для него << и >>.
Скопируйте поток объектов name_and_address. - (*2) Постройте несколько функций для запроса
и чтения различного вида
информации. Простейший пример —
функция y_or_n() в
Идеи: целое, число с плавающей
точкой, имя файла, почтовый
адрес, дата, личные данные и т.д.
Постарайтесь сделать их
защищенными от дурака. - (*1.5) Напишите программу,
которая печатает (1) все буквы в
нижнем регистре, (2) все буквы, (3)
все буквы и цифры, (4) все
символы, которые могут
встречаться в идентификаторах
C++ на вашей системе, (5) все
символы пунктуации, (6) целые
значения всех управляющих
символов, (7) все символы
пропуска, (8) целые значения
всех символов пропуска, и (9) все
печатаемые символы. - (*4) Реализуйте стандартную
библиотеку ввода/вывода C () с
помощью стандартной
библиотеки ввода/вывода C++ (). - (*4) Реализуйте стандартную
библиотеку ввода/вывода C++ () с
помощью стандартной
библиотеки ввода/вывода C (). - (*4) Реализуйте стандартные
библиотеки C и C++ так, чтобы они
могли использоваться
одновременно. - (*2) Реализуйте класс, для
которого [] перегружено для
реализации случайного чтения
символов из файла. - (*3) Как Упражнение 8,
только сделайте, чтобы []
работало и для чтения, и для
записи. Подсказка: сделайте,
чтобы [] возвращало объект
«дескрипторного типа», для
которого присваивание
означало бы присвоить файлу
через дескриптор, а неявное
преобразование в char означало
бы чтение из файла через дескриптор. - (*2) Как Упражнение 9, только разрешите []
индексировать записи
некоторого вида, а не символы. - (*3) Сделайте обобщенный вариант класса, определенного в Упражнении 10.
- (*3.5) Разработайте и реализуйте операцию ввода по
сопоставлению с образцом. Для
спецификации образца
используйте строки формата в
духе printf. Должна быть
возможность попробовать
сопоставить со вводом
несколько образцов для
нахождения фактического
формата. Можно было бы вывести
класс ввода по образцу из istream. - (*4) Придумайте (и реализуйте) вид образцов, которые намного лучше.
Назад]
[] [Вперед
Используются технологии uCoz
8.6 Буферизация
При задании операций ввода/вывода мы никак не касались
типов файлов, но ведь не все
устройства можно рассматривать
одинаково с точки зрения стратегии
буферизации. Например, для ostream,
подключенного к символьной строке,
требуется буферизация другого
вида, нежели для ostream, подключенного
к файлу
С этими проблемами можно
справиться, задавая различные
буферные типы для разных потоков в
момент инициализации (обратите
внимание на три конструктора
класса ostream). Есть только один набор
операций над этими буферными
типами, поэтому в функциях ostream нет
кода, их различающего
Однако
функции, которые обрабатывают
переполнение сверху и снизу,
виртуальные. Этого достаточно,
чтобы справляться с необходимой в
данное время стратегией
буферизации. Это также служит
хорошим примером применения
виртуальных функций для того, чтобы
сделать возможной однородную
обработку логически эквивалентных
средств с различной реализацией.
Описание буфера потока в выглядит так:
struct streambuf { // управление буфером потока
char* base; // начало буфера
char* pptr; // следующий свободный char
char* qptr; // следующий заполненный char
char* eptr; // один из концов буфера
char alloc; // буфер, выделенный с помощью new
// Опустошает буфер:
// Возвращает EOF при ошибке и 0 в случае успеха
virtual int overflow(int c =EOF);
// Заполняет буфер
// Возвращет EOF при ошибке или конце ввода,
// иначе следующий char
virtual int underflow();
int snextc() // берет следующий char
{
return (++qptr==pptr) ? underflow() : *qptr&0377
}
// ...
int allocate() // выделяет некоторое пространство буфера
streambuf() { /* ... */}
streambuf(char* p, int l) { /* ... */}
~streambuf() { /* ... */}
};
Обратите внимание, что здесь определяются указатели, необходимые
для работы с буфером, поэтому обычные посимвольные действия можно
определить (только один раз) в виде максимально эффективных inline-
функций. Для каждой конкретной стратегии буферизации необходимо
определять только функции переполнения overflow() и underflow().
Например:
struct filebuf : public streambuf {
int fd; // дескриптор файла
char opened; // файл открыт
int overflow(int c =EOF);
int underflow();
// ...
// Открывает файл:
// если не срабатывает, то возвращает 0,
// в случае успеха возвращает "this"
filebuf* open(char *name, open_mode om);
int close() { /* ... */ }
filebuf() { opened = 0; }
filebuf(int nfd) { /* ... */ }
filebuf(int nfd, char* p, int l) : (p,l) { /* ... */ }
~filebuf() { close(); }
};
int filebuf::underflow() // заполняет буфер из fd
{
if (!opened || allocate()==EOF) return EOF;
int count = read(fd, base, eptr-base);
if (count <1) return EOF;
qptr=base;
pptr=base + count;
return *qptr & 0377;
}
8.3 Файлы и Потоки
Потоки обычно связаны с файлами.
Библиотека потоков создает
стандартный поток ввода cin,
стандартный поток вывода cout и
стандартный поток ошибок cerr.
Программист может открывать другие
файлы и создавать для них потоки.
8.3.1 Инициализация Потоков Вывода
ostream имеет конструкторы:
class ostream {
// ...
ostream(streambuf* s); // связывает с буфером потока
ostream(int fd); // связывание для файла
ostream(int size, char* p); // связывет с вектором
};
Главная работа этих конструкторов — связывать с потоком буфер.
streambuf — класс, управляющий буферами; он описывается в ,
как и класс filebuf, управляющий streambuf для файла. Класс filebuf
является производным от класса streambuf.


Описание стандартных потоков вывода cout и cerr, которое
находится в исходных кодах библиотеки потоков ввода/вывода,
выглядит так:
// описать подходящее пространство буфера
char cout_buf
// сделать "filebuf" для управления этим пространством
// связать его с UNIX'овским потоком вывода 1 (уже открытым)
filebuf cout_file(1,cout_buf,BUFSIZE);
// сделать ostream, обеспечивая пользовательский интерфейс
ostream cout(&cout_file);
char cerr_buf;
// длина 0, то есть, небуферизованный
// UNIX'овский поток вывода 2 (уже открытый)
filebuf cerr_file()2,cerr_buf,0;
ostream cerr(&cerr_file);
Примеры двух других конструкторов ostream можно найти в
и .
8.3.2 Закрытие Потоков Вывода
Деструктор для ostream сбрасывает буфер с помощью
открытого члена функции ostream::flush():
ostream::~ostream()
{
flush(); // сброс
}
Сбросить буфер можно также и явно. Например:
cout.flush();
8.3.3 Открытие Файлов
Точные детали того, как открываются и закрываются файлы,
различаются в разных операционных
системах и здесь подробно не
описываются. Поскольку после
включения становятся доступны cin,
cout и cerr, во многих (если не во всех)
программах не нужно держать код для
открытия файлов. Вот, однако,
программа, которая открывает два
файла, заданные как параметры
командной строки, и копирует первый во второй:
#include <iostream.h>
void error(char* s, char* s2)
{
cerr << s << " " << s2 << "\n";
exit(1);
}
main(int argc, char* argv[]) {
if (argc !=3)
error("неверное число параметров","");
filebuf f1;
if (f1.open(argv,input)==0)
error("не могу открыть входной файл",argv);
istream from(&f1);
filebuf f2;
if (f2.open(argv,output)==0)
error("не могу создать выходной файл",argv);
ostream to(&f2);
char ch;
while (from.get(ch)) to.put(ch);
if (!from.eof() !! to.bad())
error("случилось нечто странное","");
}
Последовательность действий при создании ostream для именованного
файла та же, что используется для стандартных потоков: (1) сначала
создается буфер (здесь это делается посредством описания filebuf);
(2) затем к нему подсоединяется файл (здесь это делается
посредством открытия файла с помощью функции filebuf::open()); и,
наконец, (3) создается сам ostream с filebuf в качестве параметра.
Потоки ввода обрабатываются аналогично.
Файл может открываться в одной из двух мод:
enum open_mode { input, output };
Действие filebuf::open() возвращает 0, если не может открыть файл в
соответствие с требованием. Если пользователь пытается открыть
файл, которого не существует для output, он будет создан.
Перед завершением программа проверяет, находятся ли потоки в
приемлемом состоянии (см. ).
При завершении программы открытые файлы неявно закрываются.
Файл можно также открыть одновременно для чтения и записи, но в
тех случаях, когда это оказывается необходимо, парадигма потоков
редко оказывается идеальной. Часто лучше рассматривать такой файл
как вектор (гигантских размеров). Можно определить тип, который
позволяет программе обрабатывать файл как вектор; см. .
8.3.4 Копирование Потоков
Есть возможность копировать потоки. Например:
cout = cerr;
В результате этого получаются две переменные, ссылающиеся на один и
тот же поток. Главным образом это бывает полезно для того, чтобы
сделать стандартное имя вроде cin ссылающимся на что-то другое
(пример этого см. в )
8.4.4 Инициализация Потоков Ввода
Естественно, тип istream, так же как и ostream, снабжен
конструктором:
class istream {
// ...
istream(streambuf* s, int sk =1, ostream* t =0);
istream(int size, char* p, int sk =1);
istream(int fd, int sk =1, ostream* t =0);
};
Параметр sk задает, должны пропускаться пропуски или нет. Параметр
t (необязательный) задает указатель на ostream, к которому
прикреплен istream. Например, cin прикреплен к cout; это значит,
что перед тем, как попытаться читать символы из своего файла, cin
выполняет
cout.flush(); // пишет буфер вывода
С помощью функции istream::tie() можно прикрепить (или открепить,
с помощью tie(0)) любой ostream к любому istream. Например:
Вариант «простой»[править]
Первая программа, которую мы рассмотрим, — это «Hello World» — программа, которая выведет на экран строку текста «Hello, World!» («Здравствуй, мир!») и закончит своё выполнение.
#include<stdio.h>
intmain(void)
{
puts("Hello, World!");
return;
}
Посмотрим на неё внимательно. Первая строка — —
означает «включи заголовок ». В этом заголовке объявляются функции, связанные с вводом и выводом данных.
Аббревиатуру stdio можно перевести как стандартный ввод-вывод (англ. standard input/output). Буква «h» после точки означает заголовок (англ. ). В заголовках (которые как правило представлены отдельными заголовочными файлами) обычно объявляются предоставляемые соответствующими им библиотеками функции, типы данных, константы и определения препроцессора.
Далее идёт определение функции . Оно начинается с объявления:
intmain(void)
что значит: «функция с именем , которая возвращает целое число (число типа от англ. ) и у которой нет аргументов »
В качестве варианта, стандарт допускает определение функции как функции двух аргументов ( и — имена, разумеется, могут быть произвольными), что используется для получения доступа к аргументам командной строки из программы. В данном случае, эта возможность не требуется, поэтому функция определена как безаргументная (что также явно разрешено стандартом.)
Английское слово можно перевести как «пустота». Далее открываются фигурные скобки и идёт тело функции, в конце фигурные скобки закрываются. Функция — главная функция программы, именно с нее начинается выполнение программы.
Тело функции, в свою очередь, определяет последовательность действий, выполняемых данной функцией — логику функции. Наша функция выполняет одно единственное действие:
puts("Hello, World!");
Это действие, в свою очередь, есть вызов функции стандартной библиотеки. В результате выполнения этого вызова, на (которым, скорее всего, окажется экран или окно на экране) печатается строка .


Затем идёт команда , которая завершает выполнение функции с возвратом значения 0, определяемого стандартом (для функции ) как код успешного завершения.
8.5 Работа со Строками
Можно осуществлять действия, подобные вводу/выводу,
над символьным вектором,
прикрепляя к нему istream или ostream.
Например, если вектор содержит
обычную строку, завершающуюся
нулем, для печати слов из этого
вектора можно использовать
приведенный выше копирующий цикл:
void word_per_line(char v[], int sz)
/*
печатет "v" размера "sz" по одному слову на строке
*/
{
istream ist(sz,v); // сделать istream для v
char b2; // больше наибольшего слова
while (ist>>b2) cout << b2 << "\n";
}
Завершающий нулевой символ в этом случае интерпретируется как символ конца файла.
В помощью ostream можно отформатировать сообщения, которые не нужно печатать тотчас же:
char* p = new char; ostream ost(message_size,p); do_something(arguments,ost); display(p);
Такая операция, как do_something, может писать в поток ost,
передавать ost своим подоперациям и т.д. с помощью стандартных
операций вывода. Нет необходимости делать проверку не переполнение,
поскольку ost знает свою длину и когда он будет переполняться, он
будет переходить в состояние _fail. И, наконец, display может
писать сообщения в «настоящий» поток вывода. Этот метод может
оказаться наиболее полезным, чтобы справляться с ситуациями, в
которых окончательное отображение данных включает в себя нечто
более сложное, чем работу с традиционным построчным устройством
вывода. Например, текст из ost мог бы помещаться в располагающуюся
где-то на экране область фиксированного размера.