
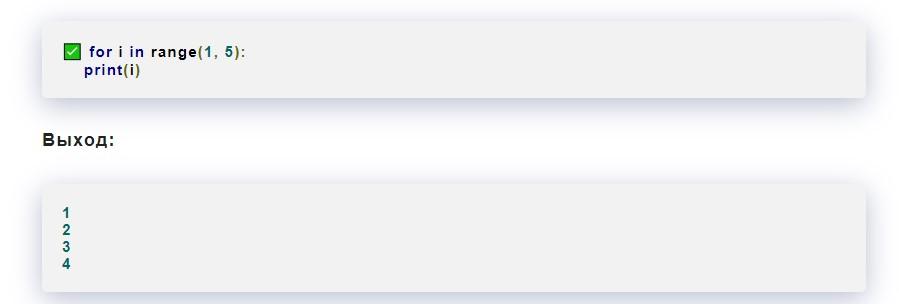
Best practices for writing clean code and avoiding Pylint errors
1. Use descriptive and meaningful variable names: Avoid using one-letter variable names and choose descriptive names that accurately reflect their purpose. 2. Keep function and method lengths short: Try to keep functions and methods short and focused. A good rule of thumb is to limit functions to a maximum of 20 lines of code. 3. Use spaces around operators and after commas: Add a space after commas and around operators like + or - to improve readability. 4. Avoid unnecessary code redundancies: Make sure to remove any redundant code and avoid repeating the same instructions throughout the code. 5. Use exception handling: Catching and handling exceptions in your code is important for detecting and handling errors gracefully. 6. Stick with a consistent coding style: Establish a consistent coding style across your project and document it for others to follow. 7. Make use of docstrings: Using docstrings to describe functions and methods will help others understand how to use your code. 8. Use pylint to check your code: Pylint can be used to clean up your code. Run the pylint command on your code to identify problematic areas and make improvements. 9. Isolate complex code into functions: Isolating complex code into its own function can make it easier to understand and modify later on. 10. Follow the "Single Responsibility Principle": Each function, class, and module should have a single, well-defined responsibility.
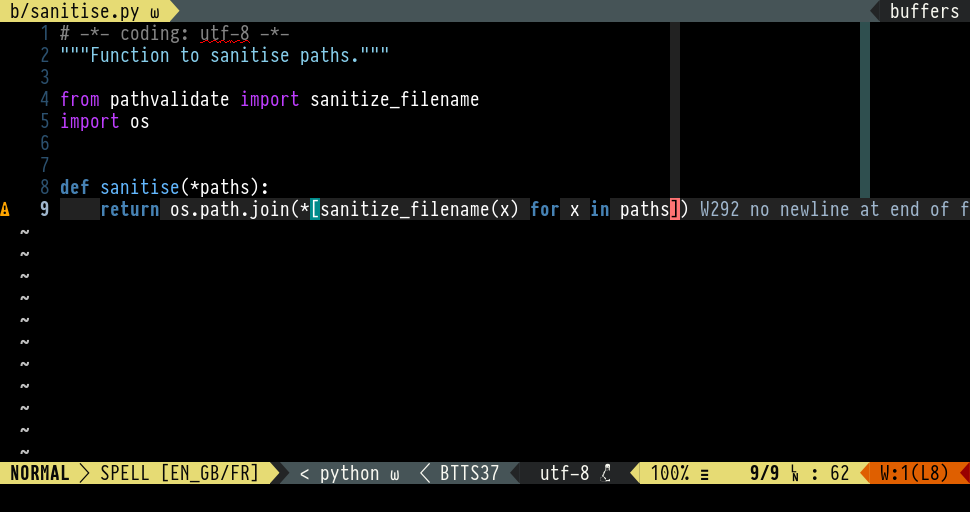
What’s the point in adding a new line to the end of a file?
I thought this would be a C-programmers-only problem, but github displays a message in the commit view:
for a PHP file. I understand the preprocessor thing explained in this thread, but what has this to do with PHP? Is it the same include() thing or is it related to the \r\n vs \n topic? What is the point in having a new line at the end of a file?
asked Aug 14, 2011 at 19:29
Philipp Stephan Philipp Stephan
3,270 2 2 gold badges 15 15 silver badges 8 8 bronze badges
Duplicate from SO: stackoverflow.com/questions/729692/…
Dec 31, 2018 at 12:55
If you cat the file, the next prompt will be appended to the final «line» if it does not end with a newline.
Jul 4, 2019 at 1:24
7 Answers 7
It’s not about adding an extra newline at the end of a file, it’s about not removing the newline that should be there.
A text file, under unix, consists of a series of lines, each of which ends with a newline character ( \n ). A file that is not empty and does not end with a newline is therefore not a text file.
Utilities that are supposed to operate on text files may not cope well with files that don’t end with a newline; historical Unix utilities might ignore the text after the last newline, for example. GNU utilities have a policy of behaving decently with non-text files, and so do most other modern utilities, but you may still encounter odd behavior with files that are missing a final newline¹.
With GNU diff, if one of the files being compared ends with a newline but not the other, it is careful to note that fact. Since diff is line-oriented, it can’t indicate this by storing a newline for one of the files but not for the others — the newlines are necessary to indicate where each line in the diff file starts and ends. So diff uses this special text \ No newline at end of file to differentiate a file that didn’t end in a newline from a file that did.
By the way, in a C context, a source file similarly consists of a series of lines. More precisely, a translation unit is viewed in an implementation-defined as a series of lines, each of which must end with a newline character (n1256 §5.1.1.1). On unix systems, the mapping is straightforward. On DOS and Windows, each CR LF sequence ( \r\n ) is mapped to a newline ( \n ; this is what always happens when reading a file opened as text on these OSes). There are a few OSes out there which don’t have a newline character, but instead have fixed- or variable-sized records; on these systems, the mapping from files to C source introduces a \n at the end of each record. While this isn’t directly relevant to unix, it does mean that if you copy a C source file that’s missing its final newline to a system with record-based text files, then copy it back, you’ll either end up with the incomplete last line truncated in the initial conversion, or an extra newline tacked onto it during the reverse conversion.
¹ Example: the output of GNU sort on non-empty files always ends with a newline. So if the file foo is missing its final newline, you’ll find that sort foo | wc -c reports one more byte than cat foo | wc -c . The read builtin of sh is required to return false if the end-of-file is reached before the end of the line is reached, so you’ll find that loops such as while IFS= read -r line; do . ; done skip an unterminated line altogether.
13 Answers 13
It indicates that you do not have a newline (usually ‘
‘ , aka CR or CRLF) at the end of file.
That is, simply speaking, the last byte (or bytes if you’re on Windows) in the file is not a newline.
The message is displayed because otherwise there is no way to tell the difference between a file where there is a newline at the end and one where is not. Diff has to output a newline anyway, or the result would be harder to read or process automatically.
Note that it is a good style to always put the newline as a last character if it is allowed by the file format. Furthermore, for example, for C and C++ header files it is required by the language standard.
It’s not just bad style, it can lead to unexpected behavior when using other tools on the file.
Here is test.txt :
There is no newline character on the last line. Let’s see how many lines are in the file:
Maybe that’s what you want, but in most cases you’d probably expect there to be 2 lines in the file.
Also, if you wanted to combine files it may not behave the way you’d expect:
Finally, it would make your diffs slightly more noisy if you were to add a new line. If you added a third line, it would show an edit to the second line as well as the new addition.

The only reason is that Unix historically had a convention of all human-readable text files ending in a newline. At the time, this avoided extra processing when displaying or joining text files, and avoided treating text files differently to files containing other kinds of data (eg raw binary data which isn’t human-readable).
Because of this convention, many tools from that era expect the ending newline, including text editors, diffing tools, and other text processing tools. Mac OS X was built on BSD Unix, and Linux was developed to be Unix-compatible, so both operating systems have inherited the same convention, behaviour and tools.
Windows wasn’t developed to be Unix-compatible, so it doesn’t have the same convention, and most Windows software will deal just fine with no trailing newline.
But, since Git was developed for Linux first, and a lot of open-source software is built on Unix-compatible systems like Linux, Mac OS X, FreeBSD, etc, most open-source communities and their tools (including programming languages) continue to follow these conventions.
There are technical reasons which made sense in 1971, but in this era it’s mostly convention and maintaining compatibility with existing tools.
Проблема разделения строки в открытом файле Python
Возникшая проблема заключается в том, что при открытии файла в Python не удается правильно определить линию разрыва. Это может привести к некорректной обработке текста и проблемам при чтении данных.
При открытии файла в режиме чтения, Python использует свой стандартный алгоритм разделения строки при чтении содержимого файла. Однако, в некоторых случаях этот алгоритм может работать неправильно, особенно когда файл создан на другой операционной системе или использует иные символы для разделения строк.
Для решения этой проблемы можно использовать специальный параметр при открытии файла. Установка указывает Python на то, что строки должны разделяться любыми символами, что полезно в случае, когда файл использует нестандартные символы перевода строки.
Ниже приведена таблица с примером использования параметра :
| Код | Значение | Результат |
|---|---|---|
| Пустая строка | Строки разделяются любыми символами | |
| (стандартный символ перевода строки) | Строки разделяются только символом перевода строки | |
| (символы перевода строки для Windows) | Строки разделяются символами перевода строки, используемыми для Windows |
Использование параметра может помочь в правильной обработке содержимого файла и избежать проблем с разделением строк в Python.
Решение проблемы
Если в Python не работает команда print, то причиной может быть различное программное обеспечение, которое блокирует вывод текста в консоль. Для решения этой проблемы нужно применить одно из нескольких решений.
- Перенаправление вывода: можно перенаправить вывод из консоли в файл. Это можно сделать с помощью команды python file.py > output.txt. Это создаст файл output.txt и записать туда вывод программы. Это может быть полезно при диагностике проблем с программой.
- Обновление IDE: В вашей среде разработки может быть проблема, приводящая к блокированию вывода в консоли. Попробуйте обновить свою IDE до последней версии, чтобы исправить проблему.
- Отключение буферизации: Может возникнуть проблема с буферизацией вывода, что означает, что вывод пишется в буфер, а не немедленно в консоль. Для решения этой проблемы можно использовать метод flush, чтобы сбросить буфер и принудительно вывести все данные в консоль.
Если ни одно из этих решений не помогло, проверьте правильность установки Python на вашем компьютере или свяжитесь с командой поддержки разработчиков Python для получения дополнительной помощи.
Проверка синтаксиса и правильности кодировки
Частая причина ошибок с командой print в Python — неправильный синтаксис. Чтобы избежать таких ошибок, нужно внимательно проверять код на наличие правильных скобок, запятых, кавычек и других символов. Например, в случае указания несуществующей переменной, Python выдаст ошибку «NameError: name ‘название переменной’ is not defined».
Еще одной причиной ошибок может быть неправильная кодировка. Если вы используете не ту кодировку, которая предназначена для вашей программы, то команда print может работать неправильно. Для правильной работы принта в Python рекомендуется использовать кодировку UTF-8, которая поддерживает все символы из разных языков и даже эмодзи.
Для проверки кодировки можешь использовать команду sys.getdefaultencoding(). Если тебе нужно изменить текущую кодировку на UTF-8, можно использовать следующий код:
import sys
reload(sys)
sys.setdefaultencoding(‘utf-8’)
Не забывайте, что в Python все строки имеют тип Unicode, поэтому при работе с текстом лучше всего использовать Unicode-символы.
Использование стабильной версии Python
Часто причиной ошибок с командой print в Python является использование устаревших версий языка. В новых версиях Python может быть изменено поведение этой команды, а некоторые старые версии могут иметь ошибки и уязвимости связанные с командой print.
Поэтому стоит использовать стабильные и поддерживаемые версии Python, например, Python 3.9. Новые версии идут вместе с улучшенным функционалом и исправлением ошибок, присущих предыдущим версиям.
Перед установкой и использованием Python следует проверить, что вы скачиваете и устанавливаете версию, которая соответствует вашей операционной системе, а также проверить, что вы получаете профессиональную помощь, если столкнетесь с проблемами.
Установка и использование стабильной версии Python позволяет избежать многих ошибок и проблем, связанных со старыми или несовместимыми версиями Питона, в том числе и с ошибками при работе командой print.
Использование других команд для вывода информации
Если у вас возникают проблемы с использованием команды print в Python, есть другие команды, которые можно использовать для вывода информации.
Команда input
Команда input позволяет пользователю ввести информацию из консоли. Например:
name = input(«Введите ваше имя: «)
В этом случае пользователь будет приглашен ввести свое имя. После ввода значения, оно будет присвоено переменной name.


![[решено] unexpected eof while parsing ошибка синтаксиса python](https://mtrufa.ru/wp-content/uploads/c/8/f/c8f1508c6c99f783ab18f17b9bcc3f91.jpeg)
Команда format
Команда format используется для форматирования вывода информации. Например:
print(«Ваше имя: {}, ваш возраст: {}».format(name, age))
В этом случае вместо {} будут подставлены значения переменных name и age.
Команда write
Команда write используется для записи информации в файл. Например:
with open(«file.txt», «w») as f:
f.write(«Привет, мир!»)
В этом случае будет создан файл file.txt и в него будет записано сообщение «Привет, мир!».
Команда print является одной из основных команд в Python для вывода информации, но если она не работает, можно использовать другие команды, такие как input, format и write.
Что такое ошибка «No newline at end of file» в Python и как её исправить
Ошибка «No newline at end of file» (нет символа новой строки в конце файла) является одной из наиболее распространенных ошибок, которые могут возникнуть при разработке программ на языке Python. Эта ошибка указывает на отсутствие символа новой строки (CR или LF) в конце файла.
Символ новой строки в конце файла является стандартным соглашением о форматировании кода в Python. Он требуется интерпретатором Python для правильного чтения и интерпретации файла. В случае отсутствия этого символа интерпретатор может выдать сообщение об ошибке «No newline at end of file».
Сама ошибка не является критической, и код может комpилироваться и запускаться без ошибок. Однако, в целях поддержания единообразия и удобочитаемости кода рекомендуется исправить эту ошибку.
Для исправления ошибки «No newline at end of file» в Python вам необходимо просто добавить символ новой строки в конец файла. Для этого вы можете воспользоваться текстовыми редакторами с функцией автоматического добавления символов новой строки.
Также существуют специализированные инструменты, которые могут автоматически исправлять подобные ошибки во всех файлах проекта. Некоторые IDE (интегрированные среды разработки) также имеют возможность автоматического исправления ошибок форматирования кода, включая устранение отсутствия символа новой строки в конце файла.
Важно отметить, что символ новой строки может отличаться в зависимости от операционной системы. Например, в операционных системах Windows используется символ новой строки CR+LF (возврат каретки + перевод строки), а в Unix-подобных системах — только LF (перевод строки)
Если вы работаете в командной строке или терминале, то вам нужно добавить символ новой строки, соответствующий вашей операционной системе.
Суммируя
- Ошибка «No newline at end of file» указывает на отсутствие символа новой строки в конце файла в Python.
- Добавление символа новой строки в конец файла является стандартным соглашением о форматировании кода в Python.
- Для исправления ошибки требуется добавить символ новой строки в конец файла.
- Используйте текстовые редакторы с функцией автоматического добавления символов новой строки или специализированные инструменты для автоматического исправления ошибок во всем проекте.
- Учтите, что символ новой строки может отличаться в зависимости от операционной системы.
#Fixing Newline Issues in Python File Writing: Simple Solutions for Appending Content Correctly
It seems like your file already has a newline character at the end, causing the appended content to start on a new line. This can be due to various reasons, such as how text editors handle newlines or if the file was created with Python and ended with a newline.
To address this, you can use a context manager when opening files to en proper handling. Here’s a suggestion:
This approach reads the file, removes any trailing newline characters, appends your content, and writes it back to the file, ensuring it ends correctly without extra newlines.
If you’re appending to an empty file and still facing issues, it could be because the initial string you’re appending has a newline character at the end. You can check this by printing the line before appending. If there’s a newline, you can remove it using .
Another approach is to open the file, go to the end, move one character before the end, and then write your content. Here’s how you can do it:
This method ens your content is appended to the last line without adding extra newlines. However, note that the effectiveness of this approach may vary across different operating systems.
I wanna add the ‘=’ + result to the file at the end of the current line. But it goes to a new line and prints it there.Why does this happen?thanks Im just appending the line to this new file but for some reason it seperates the first part — then new line — then the second part now, what changes the value of line is when I do the += ‘=’ + str(result).And yes ,I read the line from the original fileIs there anyway to go around that?
Самые распространенные SyntaxError
Неверный синтаксис не всегда легко определить. Существуют некоторые ошибки the Python рассматриваемой категории, которые могут вызвать трудности при поиске и отладке. Далее предстоит изучить общие и наиболее встречающиеся invalid syntax.
Пунктуационные сбои
Сообщение «Missing punctuation error» может ввести в замешательство программистов-новичков. Ниже можно увидеть фрагмент кода the Python, при обработке которого возникает характерное сообщение об обнаруженной неполадке:
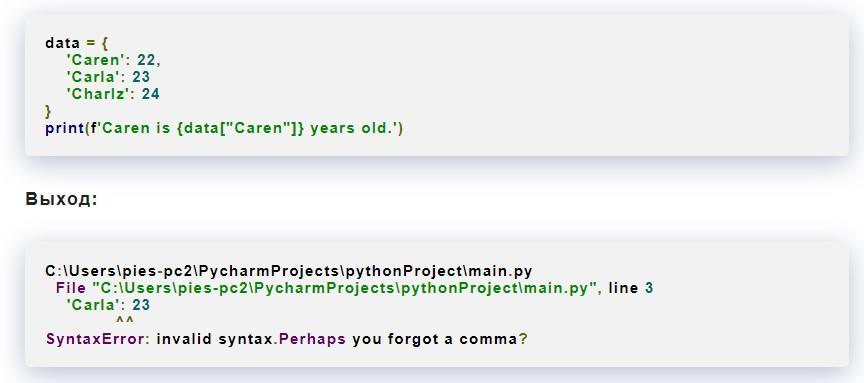
Обычно пунктуационные неполадки относятся к строке, которая идет после фактически совершенной ошибки в the Python. Здесь – это недостающий знак препинания (запятая) во второй строке определения. Для исправления нужно переписать код the Python и расставить все знаки препинания по местам:
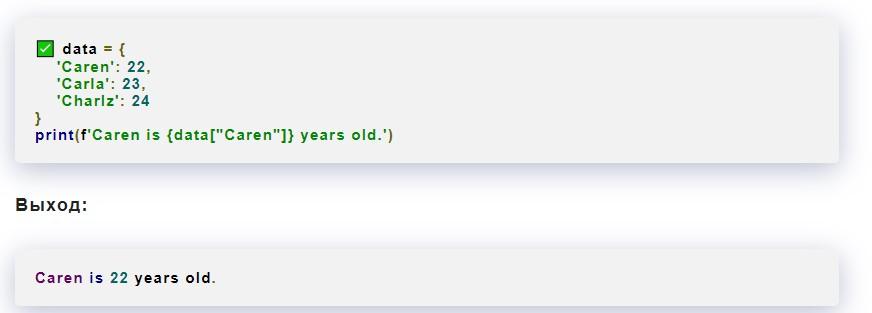
Выше – исправленный фрагмент приложения и результат его корректной обработки.
Недостающие кавычки и скобки
Invalid Syntax в the Python может встречаться из-за того, что в процессе написания приложения программист не поставил кавычки (любого типа) или скобки в нужных местах. Вот наглядный пример соответствующего сбоя:

Здесь отсутствуют открывающие и закрывающие скобки в функции print (). Круглые скобки необходимы для вызова функции. Они ставятся даже тогда, когда аргументы, передаваемые в команду, отсутствуют.

Данную неполадку легко исправить. Все, что нужно разработчику – это найти «проблемное» место и поставить круглые скобки в функцию печати. Исправленный код the Python будет выглядеть так:

Syntax error: invalid-syntax-error возникает также при отсутствующих квадратных скобках. Они используются для того, чтобы определить список в the Python. Каждая открывающая скобка должна, согласно действующим правилам синтаксиса, иметь закрывающую скобку:
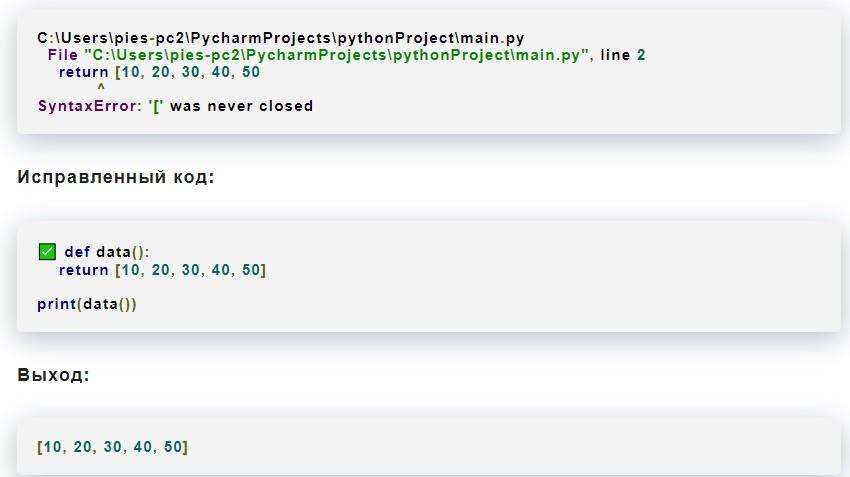
Выше можно увидеть наглядный пример неполадки в the Python, связанной с квадратными скобками и исправленный фрагмент соответствующего приложения.
Неправильно написанные ключевые слова
В каждом языке разработки программного обеспечения имеются зарезервированные синтаксисом слова. Они называются ключевыми. Применяются для вызова определенных функций, методов, а также использования различных инструментов. Неполадки, связанные с неправильным применением ключевых слов, тоже считаются одними из самых распространенных. Они обычно относятся к invalid syntax.
Вот примеры ключевых слов the Python:
- while;
- for;
- break;
- continue.
Опечатка, допущенная при написании ключевого слова the Python, может привести к прерыванию работы всего приложения. Выглядеть соответствующая ситуация будет примерно так:
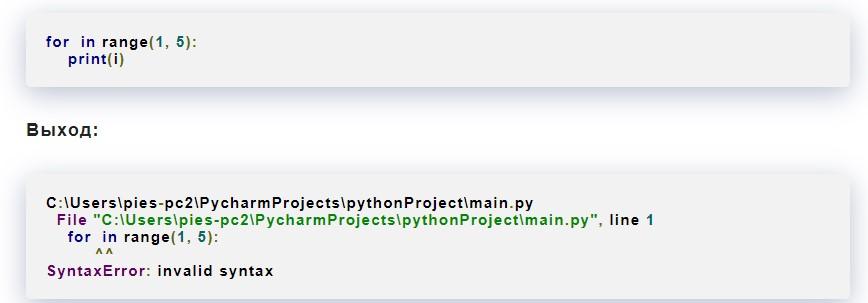
Возникают орфографические ошибки в keywords в основном тогда, когда разработчик торопится и быстро пишет программный код. Именно поэтому рекомендуется всегда проверять корректность синтаксиса.
Выше – пример исправленного фрагмента с invalid syntax и результат его обработки в the Python.
Неправильное применение ключей
Ключевые слова в языке программирования используются для реализации некоторых функций и команд. Неправильная их реализация, даже при отсутствии орфографический ошибок – это тоже сбой в программе.



Ниже – наглядный пример неправильного применения break:
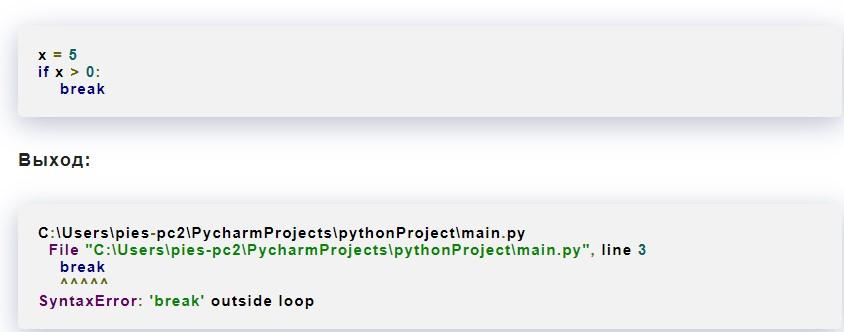
The Python использует ключевое слово break для экстренного завершения цикла. Воспользоваться им за пределами loop в программном коде нельзя. Это повлечет за собой неправильный синтаксис.

Исправить данную syntaxerror: invalid-syntax легко. Достаточно просто добавить в исходный код цикл, в котором будет допустимо применение ключевого слова break.
Append text to a file using “with”
In the previous examples, we used “with” to open a file. With this word, the file is opened and closed immediately after leaving the scope. You can check it using the “closed” property.
|
1 |
importos file_path=’D://file.txt’ file_exists=os.path.isfile(file_path) withopen(file_path,’a’)asf f.write(‘First line.\n’) f.write(‘Second line.\n’) print(f.closed) print(f.closed) |
Two print functions print whether the file is closed or not. If it’s closed, it returns True, otherwise False.
The first print is inside the scope, so it prints False as the file is not closed, in the next print, the code is out of the scope, so the function prints True.
Command
If your language does not support such lint, or you want to check non-code files, use a custom command to find files not ending with newline (credit):
find . -type f | xargs -L1 bash -c 'test "$(tail -c1 "$0")" && echo "No newline at end of $0"'
It works like this:
- find prints all file names recursively.
- . is where to start from, the current directory in this case. You can also add your code directory here. You can add multiple directories separated by space.
- -type f limits the results to ordinary files and not directories.
- | takes the output of the previous command and directs it as input to the following command instead of printing. This is called piping.
- xargs takes lines from input and runs a given command on them.
- -L1 means to run the command on each input line separately (otherwise it glues them).
- bash -c ‘test «$(tail -c1 «$0″)» && echo «No newline at end of $0″‘ is what xargs runs on each input line (file path). So effectively this is ran for each file:
bash -c 'test "$(tail -c1 "$0")" && echo "No newline at end of $0"' file_path
bash -c string means to run string as a command and make everything after it available to that command as positional arguments. Here string is ‘test «$(tail -c1 «$0″)» && echo «No new line at end of $0″‘ After the string comes file_path , so it is available to that command as the positional argument of $0 . So bash will effectively run this:
test "$(tail -c1 "file_path")" && echo "No newline at end of file_path"
- test with a string after it checks if that string is not empty. It exits with a non-zero code (error) if it is empty and a zero code (OK) otherwise. && only continues to the next command if the previous one exited with zero code. It means that echo «No newline at and of file_path» will only be printed if the string passed to test is not empty.
- «$(something)» means that something will be executed as a command, and its output inserted between the quotes. It means to execute tail -c1 «file_path» and to to pass its result as an argument to test .
- tail -c1 «file_path» takes the last 1 byte from the given file. So it is either newline character or some other byte. And this byte is what is passed to test as an argument. A string beginning with a newline character is treated by test as empty, no matter how long it is. So for newline character test exits with a non-zero code. Any other character means a non-empty string, it makes test exit with zero code and to continue to echo .
Что означает «TabError: непоследовательное использование табуляции и пробелов в отступе»?
проблема
Эта ошибка возникает только при попытке смешать символы табуляции и пробелы в качестве символов отступа. Как уже было сказано выше, Python не позволит вашей программе содержать сочетание табуляций и пробелов и вызовет конкретное исключение если обнаружит, что у вас есть. Например, в приведенной ниже программе сочетание отступов и пробелов используется для отступа:
Вот изображение, которое визуально показывает пробелы в вышеуказанной программе. Серые точки — это пробелы, а серые стрелки — это вкладки:
Мы можем видеть, что у нас действительно смешанные пробелы и вкладки для отступа.
Особые случаи
Примечание. Python не всегда если вы смешиваете табуляции и пробелы в своей программе. Если отступ программы однозначен, Python позволит смешивать табуляцию и пробелы. Например:
А иногда Python просто давится смесь вкладок и пространств и ошибочно поднимает исключения, когда будет более подходящим. Другой пример:
Как видите, выполнение вашего кода таким образом может привести к таинственным ошибкам. Несмотря на то, что программа визуально выглядит нормально, Python запутался, пытаясь разобрать вкладки и пробелы, используемые для отступа, и допустил ошибку.
Это отличные примеры, которые демонстрируют, почему никогда не смешивать табуляции и пробелы и использовать флаги интерпретатора и при использовании Python 2.
исправлять
Если ваша программа короткая, возможно, самое простое и быстрое решение — просто заново сделать отступ в программе. Убедитесь, что каждый оператор имеет отступ с четырьмя пробелами для каждого уровня отступа (см. Как сделать отступ для моего кода?).
Однако, если у вас уже есть большая программа, в которую вы смешали табуляцию и пробелы, есть автоматизированные инструменты, которые можно использовать для преобразования всех ваших отступов в просто пробелы.
Многие редакторы, такие как PyCharm и SublimeText, имеют опции для автоматического преобразования вкладок в пробелы. Есть также несколько онлайн-инструментов, таких как Tabs To Spaces или Browserling, которые позволяют быстро переопределить ваш код. Есть также инструменты, написанные на Python. Например, autopep8 может автоматически переопределить ваш код и другие ошибки отступа.
Однако даже самые лучшие инструменты не всегда могут исправить все ошибки, связанные с отступами, и вам придется исправлять их вручную
Поэтому важно всегда правильно делать отступы с самого начала
Reading Large Files #
The and methods work great with small files. But what if your file has thousands or millions of lines in it? In such cases using or may result in memory hogs. A better approach would be to use loops and read file data in small chunks. For example:
python101/Chapter-18/reading_large_file_demo1.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
f = open("readme.md", "r")
chunk = 10 # specify chunk size
data = ""
# keep looping until there is data in the file
while True
data = f.read(chunk)
print(data, end="")
# if end of file is reached, break out of the while loop
if data == ""
break
f.close()
|
Output:
1 2 3 |
First Line Second Line Third Line |
Here we are using an infinite loop to iterate over the contents of the file. As soon as the end of file is reached, the method returns an empty string (), if condition in line 12, evaluates to true and statement causes the loop to terminate.
Python also allows us to use for loop to loop through the file data using file object as follows:
python101/Chapter-18/reading_large_files_using_for_loop.py
1 2 3 4 5 6 |
f = open("readme.md", "r")
for line in f
print(line, end="")
f.close()
|
Output:
1 2 3 |
First Line Second Line Third Line |
TextIOWrapper class #
The file object returned by function is an object of type . The class provides methods and attributes which helps us to read or write data to and from the file. The following table lists some commonly used methods of class.
| Method | Description |
|---|---|
| Reads the specified number of characters from the file and returns them as string. If is omitted then it reads the entire file. | |
| Reads a single line and returns it as a string. | |
| Reads the content of a file line by line and returns them as a list of strings. | |
| Writes the string argument to the file and returns the number of characters written to the file. | |
| Moves the file pointer to the given offset from the origin. | |
| Returns the current position of the file pointer. | |
| Closes the file |
Понимание многострочных операторов
Многострочные операторы в программировании используются для написания более читаемого кода и упрощения структуры программы. Они позволяют разделить длинные строки кода на несколько строк, что делает код более удобным для чтения и отладки.
Однако, при использовании многострочных операторов нужно учитывать особенности языка программирования. E902 tokenerror eof in multi-line statement — это ошибка, которая может возникнуть при неправильном использовании многострочных операторов в языке программирования Python.
В языке Python, каждая инструкция должна быть записана на отдельной строке. Если инструкция состоит из нескольких строк, то ее необходимо разделить на отдельные строки с помощью специального символа продолжения строки «\» или использовать скобки, фигурные или круглые, для создания многострочных блоков.
Ошибка E902 tokenerror eof in multi-line statement указывает на то, что Python встретил конец файла, но ожидал завершения многострочного оператора. Это может быть вызвано неправильным разделением строк в многострочном операторе или неправильным использованием специального символа продолжения строки «\».
Чтобы исправить эту ошибку, необходимо внимательно проверить многострочный оператор и убедиться, что все строки правильно разделены и символы продолжения строки «\» используются корректно. Также стоит проверить, есть ли все необходимые закрывающие скобки или другие символы, которые должны завершать многострочный оператор.
Ниже приводится пример правильного использования многострочного оператора в Python:
В этом примере многострочный оператор используется для записи условного выражения, которое охватывает две строки кода. Символ продолжения строки «\» указывает на то, что условное выражение продолжается на следующей строке. При правильном использовании многострочных операторов в Python таких ошибок, как E902 tokenerror eof in multi-line statement, можно избежать.
What is Python flake?
Flake8 is a Python library that wraps PyFlakes, pycodestyle and Ned Batchelder’s McCabe script. It is a great toolkit for checking your code base against coding style (PEP8), programming errors (like “library imported but unused” and “Undefined name”) and to check cyclomatic complexity.
Why does pep 8 say no new line at end of file?
I got a warning that said “PEP 8: no new line at end of file”. Could this have anything to do with why it is not working the way it should? I’ve attempted to print the number before using break. I expected the program to stop when the user types 10 in the input. It continues to ask for numbers instead of stopping.


What do you need to know about PEP8?
INTRODUCTION pep8 is a tool to check your Python code against some of the style conventions inPEP 8. •Features •Disclaimer •Installation •Example usage and output •Configuration •Error codes •Related tools 1.1Features •Plugin architecture: Adding new checks is easy. •Parseable output: Jump to error location in your editor.
Why do I get PEP 8 error in PyCharm?
The warning pops up to keep your code in accordance with the unofficial PEP8 guidelines for writing good Python code. You can disable the warning in PyCharm’s settings. So pep 8 errors are a separate errors from pycharm ?
What does no new line at end of file mean in PyCharm?
Don’t worry about it. It’s a warning that literally means you don’t have a new line at the end of your file. The warning pops up to keep your code in accordance with the unofficial PEP8 guidelines for writing good Python code. You can disable the warning in PyCharm’s settings.
No newline at end of file python как исправить
вот и я думаю нафига оно нужно, столько нервов попорчено было по незнанке.
после каждой строки с этой ругней понажимай enter
Подтвердите свой е-майл
Регистрация: 27.07.2009
Сообщений: 437
Нужно это для директив препроцессору, располагающихся в конце файла. Вот кто бы объяснил мне, при чём тут директивы и скобка с начала строки?
| Похожие темы | ||||
| Тема | Автор | Раздел | Ответов | Последнее сообщение |
| что значит эта ошибка на борланд с++ | Nani | Помощь студентам | 1 | 13.06.2009 23:36 |
| Что значит ошибка и как исправить? | Pirotexnik | Общие вопросы Delphi | 2 | 26.03.2009 19:52 |
| unexpected end of file while looking for precompiled header directive | StakanpORTvejna | Общие вопросы C/C++ | 7 | 10.06.2008 17:52 |
| объясните что значит 3й параметр в выражении | MadBeef | Помощь студентам | 1 | 21.05.2008 16:21 |
| Что значит эта ошибка (password dialog) | мазер | Помощь студентам | 4 | 05.01.2007 13:11 |
Writing Data to the Text File #
The following program demonstrates how to write data to the the file:
python101/Chapter-18/writing_to_file.py
1 2 3 4 5 6 7 |
f = open("readme.md", "w")
f.write("First Line\n")
f.write("Second Line\n")
f.write("Third Line\n")
f.close()
|
In line 1, we are using method to open the text file in write mode. If the file doesn’t exists, the method will create the file. If the file already exists, then it’s data will be overwritten. Run the program and then open file. It should look like this:
python101/Chapter-18/readme.md
1 2 3 |
First Line Second Line Third Line |
Let’s take a close look at how method writes data to the file.
All read and write operations in a file begins at file pointer. What is file pointer ? A file pointer is simply a marker which keeps track of the number of bytes read or written in a file. This pointer automatically moves after every read or write operation.
When a file is opened the file pointer points at the beginning of the file. The function begins writing at the current file position and then increments the file pointer. For example, the following figure shows the position of file pointer after each write operation.
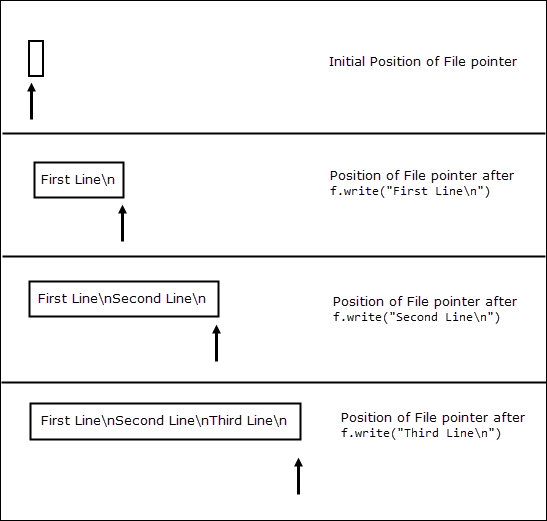
Note that unlike function, method do not print newline character () at the end of string automatically. We can also use function to write data to the file. Let’s take a closer look at the signature of the using the function.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
>>>
>>> help(print)
Help on built-in function print in module builtins
print(...)
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments
file a file-like object (stream); defaults to the current sys.stdout.
sep string inserted between values, default a space.
end string appended after the last value, default a newline.
flush whether to forcibly flush the stream.
>>>
|
Notice the fourth parameter in the function signature i.e . By default, points to the standard output means it will print data to the screen. To output data to a file just specify the file object. The following program uses function instead of to write data to the file.
python101/Chapter-18/writing_data_using_print_function.py
1 2 3 4 5 6 7 |
f = open("readme.md", "w")
print("First Line", file=f)
print("Second Line", file=f)
print("Third Line", file=f)
f.close()
|
This program produces the same output as before, the only difference is that, in this case the newline character () is automatically added by the function.