
Writing a lexer for a new programming language in python
I have no idea how/where to start. I’m supposed to be using python, and more specifically, the ply library. So far, all I’ve done in create a list of tokens that will be part of the language. That list is given below:
I’ve obviously got a long way to go, seeing as I also need to write a parser and an interpreter.
I’ve got a few questions:
- How do I use the ply library?
- Is this a good start, and if so, what do I go from this?
- Are there any resources I can use to help me with this.
I’ve tried googling stuff on writing new programming languages, but I haven’t yet found anything satisfactory

1 Answer 1
Assuming that you already have Ply installed, you should start with exploring the tutorials on the official Ply website. They are well written and easy to follow.
Ply requires token definitions to begin with. You have already done that. However, the complexities increase when your lexer has to differentiate between say a string like «forget» and a reserved keyword like for . The library provides good support for variable precedence to resolve grammar ambiguity. This can be as easy as defining the precedence as tuples:
However, I recommend you should read more about lexers and yacc before deep diving into the more advanced features like expressions and precedence in Ply. For a start, you should build a simple numerical lexer that successfully parses integers, operators and bracket symbols. I’ve reduced the token definition to suit this purpose. The following example has been modified from the official tutorials.
Library import & Token definition:
Define regular expression rules for simple tokens: Ply uses the re Python library to find regex matches for tokenization. Each token requires a regex definition. We first define regex definitions for simple tokens. Each rule declaration begins with the special prefix t_ to indicate that it defines a token.
Define regular expression rules for more complex tokens like data types such as int, float and newline characters to track line numbers. You will notice that these definitions are quite similar to the above.
Add some error handling for invalid characters:
Build the lexer:
Test the lexer with some input data, tokenize and print tokens:
You can add this example code to a Python script file like new_lexer.py and run it like python new_lexer.py . You should get the following output. Note that the input data consisted of newline( ‘\n’ ) characters that were successfully ignored in the output.
There are many other features you can make use of. For instance, debugging can be enabled with lex.lex(debug=True) . The official tutorials provide more detailed information around these features.
I hope this helps to get you started. You can extend the code further to include reserved keywords like if , while and string identification with STRING , character identification with CHAR . The tutorials cover the implementation of reserved words by defining a key-value dictionary mapping like this:
extending the tokens list further by defining the reserved token type as ‘ID’ and including the reserved dict values: tokens.append(‘ID’) and tokens = tokens + list(reserved.values()) . Then, add a definition for t_ID as above.
There are many resources available to learn about lexers, parsers and compilers. You should start with a good book that covers the theory and implementation. There are many books available that cover these topics. I liked this one. Here’s another resource that may help. If you’d like to explore similar Python libraries or resources, this SO answer may help.
Самое интересное
Мы создадим три разных функции, каждая из которых будет отвечать за одну задачу. Но прежде давайте подготовим шаблонный код.
Шаг 2. Инициализация модулей
Для использования импортированных модулей нужно их инициализировать и создать объекты:
Здесь является объектом класса .
Модуль — это похититель голосов. Он крадет разные голоса и сохраняет их в свойстве .
Мужской голос установлен по умолчанию с индексом 0. Нам нужен приятный женский голос. Для его получения мы используем метод . Женский голос хранится в индексе 1.
Теперь перейдем далее и создадим методы, которые помогут ассистенту говорить и слушать.
Шаг 3. Создание метода talk() для преобразования текста в речь
Здесь — это имя метода, который получает параметр . Текстом может быть любая строка, которую нам нужно преобразовать в речь, чтобы помощник заговорил.
Далее мы просто передаем его в метод и вызываем метод через созданный выше объект . Принцип действия должен быть вам понятен, потому что вы уже знаете основы . Теперь ваш помощник получил возможность говорить.
Теперь мы наделим его даром слушать и понимать наши команды, создав для этого метод, который будет обрабатывать распознавание речи.
Шаг 4. Создание метода take_command() для распознавания речи
Для обработки возможных ошибок микрофона и прочих мы обертываем его в блок .
Остальное очень похоже на то, что мы делали ранее. Модуль предоставляет различные механизмы распознавания речи, которые и делают всю работу. Здесь мы применили механизм от Google, для чего был использован метод из класса .
Мы уже на полпути к цели, и основная часть проекта у нас позади.
Как видно из функции выше, распознанная речь сохраняется и возвращается в переменной . Теперь нужно только проверить, что хранится в этой переменной и выполнить соответствующее действие.
Шаг 5. Создание метода run_alexa() для ответа
Здесь нужно понять несколько моментов:
1) Получение требуемой части: предположим, что вас преследует навязчивая строчка из песни, и вы решили ее послушать, приказав Alexa: “Play ”. Для этой команды в данном проекте мы просто удаляем слово и получаем часть :
Результат мы просто сохраняем в переменной .
2) pywhatkit.playonyt(): для его использования понадобится установить и импортировать модуль . PyWhatKit — это библиотека Python для отправки сообщений WhatsApp в определенное время, но в ней есть и ряд других функций, которые помогут нам с автоматизацией. Этот модуль предоставляет метод , который позволит воспроизводить желаемые песни прямо на YouTube.
Модуль этот тоже сторонний и требует установки:
И последующего импорта:
3) datetime.datetime.now(): для использования этого метода сначала нужно импортировать модуль . Он является встроенным модулем Python, который позволит нам управлять датами и временем. Метод возвращает текущее время.
Импортируйте модуль:
4) wikipedia.summary(): для применения этого метода потребуется установить и импортировать модуль Wikipedia. Wikipedia — это библиотека Python, предоставляющая возможность доступа и парсинга данных из Википедии. Она поможет нам находить нужную информацию и возвращать ее в качестве вывода. Метод запрашивает данные из сводного раздела этого ресурса.
Опять же, это сторонний модуль, который нужно установить:
И импортировать:
5) pyjokes.get_joke(): для использования этого метода нужно установить и импортировать модуль Pyjokes. Он позволит генерировать случайные однострочные шутки для программистов, которые помощник сможет обработать.
Этот сторонний модуль мы также устанавливаем:
И импортируем:
Вот и все!
Аналогичным образом можно добавить и другие библиотеки, расширив возможности помощника.
В функции выше сначала происходит вызов метода , который начинает прослушивать команды и сохранять их в переменной :
Помимо этого, чтобы помощник заговорил, мы вызываем метод и передаем ему нужные данные.
Шаг 6. Начальный вызов функции
В завершении мы вызываем метод , который запускает нашего помощника.
Теперь у вас есть собственная Alexa!
Аналогичным образом, обладая минимальными навыками работы с Python и используя другие модули, можно добавлять дополнительные возможности, сделав ее не просто умным, но также интересным и красивым виртуальным помощником.
Chunking
Chunking is a process of extracting phrases from unstructured text. Instead of just simple tokens which may not represent the actual meaning of the text, it’s beneficial to use phrases such as “South Africa” as a single word instead of ‘South’ and ‘Africa’ separate words.
Here’s how you can do noun phrase chunking in NLTK:


import nltk
from nltk import pos_tag
from nltk.tokenize import word_tokenize
from nltk.chunk import RegexpParser
sentence = "The big cat ate the little mouse who was after fresh cheese"
# PoS tagging
tagged = pos_tag(word_tokenize(sentence))
# Define your grammar using regular expressions
grammar = ('''
NP: {<DT>?<JJ>*<NN>} # NP
''')
chunk_parser = RegexpParser(grammar)
result = chunk_parser.parse(tagged)
print(result)
Output:
(S (NP The/DT big/JJ cat/NN) ate/VBD (NP the/DT little/JJ mouse/NN) who/WP was/VBD after/IN (NP fresh/JJ cheese/NN))
In this code, we first tokenized and PoS tagged our sentence. Then we defined a grammar for a noun phrase (NP) to be any optional determiner (DT) followed by any number of adjectives (JJ) and then a noun (NN).
Then we created a chunk parser with this grammar using , and finally parsed our tagged sentence.
Необходимые инструменты для создания лексера
Прежде чем приступить к созданию лексера на языке Python, вам понадобятся следующие инструменты:
- Python: Убедитесь, что на вашем компьютере установлен Python. Вы можете скачать и установить его с официального сайта Python.
- Текстовый редактор: Вы можете использовать любой текстовый редактор для написания кода лексера. Рекомендуется использовать редакторы, специально созданные для разработки на Python, такие как PyCharm или VS Code.
- Библиотека PLY: PLY (Python Lex-Yacc) — это набор инструментов для написания лексических и синтаксических анализаторов на Python. Она позволяет легко определять токены и правила грамматики для вашего лексера.
Установка PLY производится с помощью менеджера пакетов pip. Откройте терминал и выполните следующую команду:
| pip install ply |
После установки этих инструментов вы будете готовы начать создание своего лексера на Python.
Шаг 4: Напишите синтаксический анализатор
Синтаксический анализатор — это часть компилятора, которая производит анализ исходного кода на предмет соответствия формальным грамматикам языка программирования. Он получает на вход токены, которые были созданы лексическим анализатором, и строит дерево разбора, которое представляет собой дерево синтаксических правил и операций.
Для написания синтаксического анализатора необходимо определить правила синтаксиса языка и построить для него контекстно-свободную грамматику (CFG). Грамматика состоит из терминальных и нетерминальных символов, правил и аксиомы.
После определения грамматики стоит написание синтаксического анализатора, который будет работать с этой грамматикой. Используя различные подходы и алгоритмы (например, LL(1) или LALR), анализатор будет проверять соответствие правилам грамматики и строить дерево разбора.
Если синтаксический анализатор обнаруживает ошибки в коде, он должен возвращать сообщения об этих ошибках. В случае, если все правила синтаксиса соблюдены, синтаксический анализатор может перейти к следующему шагу — генерации кода.
Написание синтаксического анализатора — это важный этап разработки компилятора. Хороший анализатор должен быть точным и эффективным, что поможет избежать многих ошибок, которые возникают при компиляции программ. Следуя правильной методологии и используя правильные инструменты, можно создать качественный синтаксический анализатор на Python.
Что такое синтаксический анализ
Синтаксический анализ — это процесс анализа структуры кода, направленный на определение соответствия кода грамматике языка программирования. Синтаксический анализатор проверяет, соответствует ли набор токенов, полученных от лексического анализатора, правилам грамматики.
Во время синтаксического анализа происходит построение дерева разбора — структуры данных, которая показывает, как элементы кода связаны друг с другом.
Существует два типа синтаксического анализа: восходящий и нисходящий. Восходящий анализ использует метод рекурсивного спуска и постепенно строит дерево разбора. Нисходящий анализ, наоборот, начинает с корня дерева разбора и постепенно сворачивает его до того, как получится последовательность токенов.
Синтаксический анализатор играет важную роль в работе компилятора, так как именно здесь происходит проверка корректности написания кода.
Как написать синтаксический анализатор на Python
Синтаксический анализатор — это компонент компилятора, который проходит по исходному коду и определяет его структуру согласно правилам языка программирования. Например, синтаксический анализатор может проверять, является ли каждое выражение правильно сформированным или не синтаксически корректным.
В Python существуют различные способы создания синтаксических анализаторов. Один из них — использование библиотеки ANTLR, которая генерирует код на Python на основе грамматики, описывающей структуру языка программирования. Другой способ — использование модуля ast, встроенного в стандартную библиотеку Python. Модуль ast предоставляет функции для преобразования исходного кода в дерево синтаксического разбора.
При написании синтаксического анализатора на Python важно учитывать особенности языка, а именно гибкость и динамическую типизацию. Следует также помнить о том, что синтаксический анализатор работает не только с правильно сформированным кодом, но и с ошибочным, поэтому необходимо учесть возможности обработки ошибок при создании анализатора
Создание синтаксического анализатора — важный компонент процесса компиляции. С помощью правильно разработанного синтаксического анализатора можно упростить процесс написания и обработки кода, соблюдать стандарты языка и повышать производительность при выполнении программ.
Часть 2: парсинг токенизированного ввода с помощью Yacc
В этом разделе объясняется, как обрабатывается входной токен из части 1 — это делается с помощью контекстно-свободных грамматик (CFG). Грамматика должна быть указана, а токены обрабатываются в соответствии с грамматикой. Под капотом парсер использует LALR-парсер.
Сломать
Каждое правило грамматики определяется функцией, в которой строка документации для этой функции содержит соответствующую контекстно-независимую грамматическую спецификацию. Операторы, составляющие тело функции, реализуют семантические действия правила. Каждая функция принимает один аргумент p, который представляет собой последовательность, содержащую значения каждого грамматического символа в соответствующем правиле. Значения сопоставляются грамматические символы , как показано здесь:
- Для лексем, «ценность» соответствующий является таким же , как атрибута , назначенным в модуле лексического анализатора. Таким образом, будет иметь значение .
Обратите внимание , что функция может иметь любое имя, до тех пор , как оно предваряется. p_error(p) правило, определяется , чтобы поймать синтаксические ошибки ( такие же , как yyerror в YACC / зубров)
p_error(p) правило, определяется , чтобы поймать синтаксические ошибки ( такие же , как yyerror в YACC / зубров).
Несколько правил грамматики могут быть объединены в одну функцию, что является хорошей идеей, если производства имеют схожую структуру.
Символьные литералы могут использоваться вместо токенов.
Конечно, литералы должны быть указаны в модуле lexer.
- Чтобы явно задать начальный символ, используйте , где некоторая нетерминал.
Установка приоритета и ассоциативности может быть выполнена с помощью переменной приоритета.
##
Жетоны упорядочены по возрастанию. означает , что эти маркеры не ассоциируют. Это значит , что — то вроде незаконна тогда по — прежнему законно.
Want to Learn More?
Finally, I’ve collected some useful courses for you to learn deep learning and NLP further. Check them out:
- Deep Learning Specialization on Coursera.
- Sequences, Time Series and Prediction Course.
- Natural Language Processing Course.
Learn also: How to Perform Text Summarization using Transformers in Python.
Happy Training
Loved the article? You’ll love our Code Converter even more! It’s your secret weapon for effortless coding. Give it a whirl!
View Full Code
Generate Python Code
Sharing is caring!
Read Also

How to Perform Text Summarization using Transformers in Python
Learn how to use Huggingface transformers and PyTorch libraries to summarize long text, using pipeline API and T5 transformer model in Python.
Visit →

How to Perform Text Classification in Python using Tensorflow 2 and Keras
Building deep learning models (using embedding and recurrent layers) for different text classification problems such as sentiment analysis or 20 news group classification using Tensorflow and Keras in Python
Visit →
Обертка для eSpeak NG
Модуль называется py-espeak-ng. Это альтернатива pyttsx3 для случаев, когда вам нужен или доступен только один синтезатор — eSpeak NG. Не дай бог, конечно. Впрочем, для быстрых экспериментов с голосом очень даже подходит. Принцип использования покажется вам знакомым:
from espeakng import ESpeakNG
engine = ESpeakNG()
engine.speed = 150
engine.say(«I’d like to be under the sea. In an octopus’s garden, in the shade!», sync=True)
engine.speed = 95
engine.pitch = 32
engine.voice = ‘russian’
engine.say(‘А теперь Горбатый!’, sync=True)
Обратите внимание на параметр синхронизации реплик sync=True. Без него синтезатор начнет читать все фразы одновременно — вперемешку
В отличие от pyttsx3, обертка espeakng не использует команду runAndWait(), и пропуск параметра sync сбивает очередь чтения.
Озвучиваем текст из файла
Не будем довольствоваться текстами в коде программы — пора научиться брать их извне. Тем более, это очень просто. В папке, где хранится только что рассмотренный нами скрипт, создайте файл test.txt с текстом на русском языке и в кодировке UTF-8. Теперь добавьте в конец кода такой блок:
text_file = open(«test.txt», «r»)
data = text_file.read()
tts.say(data, sync=True)
text_file.close()
Открываем файл на чтение, передаем содержимое в переменную data, затем воспроизводим голосом все, что в ней оказалось, и закрываем файл.
3.4 Семантика
Семантика определяет последовательность действий, которые должен выполнить
грамматический анализатор, когда ему удается свести входной поток до одного
конкретного правила. В нашем примере семантика соответствует программе-интерпретатору.
В случае простого компилятора, результатом работы может оказаться соответствующий
правилу ассемблерный код.
Предположим, что в результате работы компилятора должен получаться код на языке
ассемблера для процессора 8086. Примем за правило, что регистр ‘bx’ используется
для хранения промежуточных результатов. Встретив очередной операнд, необходимо
содержимое регистра ‘ax’ переписать в регистр ‘bx’, после чего в регистр ‘ax’
занести новый операнд. Таким образом, последний встреченный операнд (или результат
операции) всегда будет содержаться в регистре ‘ax’.
def p_factor_num(t) :
'factor : NUM'
__output_fp.write("\tmov bx,ax\n"%f) # bx <--
__output_fp.write("\tmov ax,0x%x\n"%t) # ax <-- t
где, ‘__output_fp’ — дескриптор результирующего файла.
После того, как операнды подготовлены к выполнению операции (унарной или бинарной),
мы можем описать семантику операции, например сложения:
def p_statement_plus(t) :
'statement : statement ADDOP term'
__output_fp.write("\tadd ax,bx\n")
# ax <-- +
Аналогичным образом, встретив объявление переменной, можно предусмотреть выбрать
регистр процессора для ее хранения (локальные переменные предпочтительнее размещать
на стеке), и запомнить выделенный регистр в словаре. Всякий раз, когда встречается
ссылка на имя переменной, используя имя переменной в качестве ключа можно найти
имя соответствующего регистра.
Stemming
Stemming is the process of reducing inflection in words (like running, runs) to their root form (e.g., run). The ‘root’ in this case may not actually be a real root word, but just a canonical form of the original word. NLTK provides several famous stemmers interfaces, such as PorterStemmer.
Here’s how to use NLTK’s PorterStemmer:
from nltk.stem import PorterStemmer from nltk.tokenize import word_tokenize text = "He was running and eating at same time. He has bad habit of swimming after playing long hours in the Sun." porter_stemmer = PorterStemmer() words = word_tokenize(text) stemmed_words = print(stemmed_words)
Output:
In this piece of code, we first tokenize the text, and then we pass each word into the function of our stemmer.
Note how the words “running”, “eating”, “swimming”, and “playing” have been reduced to their root form: “run”, “eat”, “swim”, and “play”, respectively.
Building a Parser
First let’s import all the necessary modules.
Python3
Now let’s build a class BasicParser which extends the Lexer class. The token stream from the BasicLexer is passed to a variable tokens. The precedence is defined, which is the same for most programming languages. Most of the parsing written in the program below is very simple. When there is nothing, the statement passes nothing. Essentially you can press enter on your keyboard(without typing in anything) and go to the next line. Next, your language should comprehend assignments using the “=”. This is handled in line 18 of the program below. The same thing can be done when assigned to a string.
Python3
Парсер также должен выполнять синтаксический анализ в арифметических операциях, это можно делать с помощью выражений. Допустим, вам нужно что-то вроде показанного ниже. Здесь все они построчно преобразуются в поток токенов и построчно анализируются. Следовательно, согласно приведенной выше программе, a = 10 похоже на строку 22. То же самое для b = 20. a + b напоминает строку 34, которая возвращает дерево синтаксического анализа (‘add’, (‘var’, ‘a’), (‘var’, ‘b’)).
GFG Language > a = 10 GFG Language > b = 20 GFG Language > a + b 30
Теперь мы преобразовали потоки токенов в дерево синтаксического анализа. Следующий шаг — интерпретировать это.
Исполнение
Устный перевод — простая процедура. Основная идея состоит в том, чтобы пройти по дереву и иерархически оценить арифметические операции. Этот процесс рекурсивно вызывается снова и снова, пока не будет оценено все дерево и не будет получен ответ. Скажем, например, 5 + 7 + 4. Этот символьный поток сначала токенизируется в токен-поток в лексере. Затем поток токенов анализируется для формирования дерева синтаксического анализа. Дерево синтаксического анализа по существу возвращает (‘add’, (‘add’, (‘num’, 5), (‘num’, 7)), (‘num’, 4)). (см. изображение ниже)
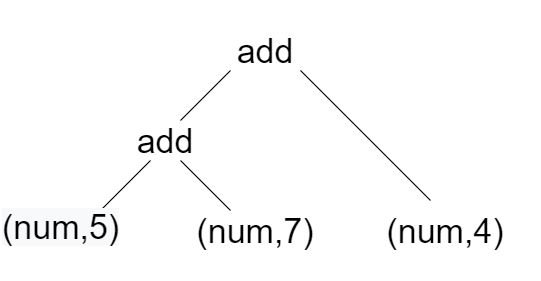
The interpreter is going to add 5 and 7 first and then recursively call walkTree and add 4 to the result of addition of 5 and 7. Thus, we are going to get 16. The below code does the same process.
Python3
Displaying the Output
To display the output from the interpreter, we should write some codes. The code should first call the lexer, then the parser and then the interpreter and finally retrieves the output. The output in then displayed on to the shell.
Python3
Необходимо знать, что мы не исправляли ошибок. Таким образом, SLY будет показывать сообщения об ошибках всякий раз, когда вы делаете что-то, что не указано в правилах, которые вы написали.
Запустите программу, которую вы написали, используя,
python you_program_name.py
Сноски
Интерпретатор, который мы построили, очень прост. Это, конечно, можно расширить, чтобы сделать гораздо больше. Можно добавлять циклы и условные выражения. Могут быть реализованы функции модульного или объектно-ориентированного дизайна. Интеграция модулей, определения методов, параметры методов — вот некоторые из функций, которые могут быть расширены на то же самое.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы
Обработка входного потока данных
Перед тем, как начать разбор входного потока, лексер применяет процесс нормализации данных, включающий удаление комментариев, пробелов, лишних переносов строк и других символов, которые не являются частью языка программирования или спецификации.
Основной принцип работы лексера заключается в том, что он последовательно считывает данные из входного потока и определяет, к какому типу лексемы они относятся. Лексемы могут быть различными символами, ключевыми словами, идентификаторами, операторами, числами и другими элементами языка программирования.
Для определения типа каждой лексемы лексер использует набор правил, называемых регулярными выражениями. Регулярные выражения описывают шаблоны символов или последовательностей символов, которые соответствуют определенному типу лексемы.


Когда лексер находит соответствие между символами входного потока и регулярным выражением, он создает соответствующую лексему и передает ее следующему компоненту компилятора или интерпретатора для дальнейшей обработки. Если символы не соответствуют ни одному регулярному выражению, лексер выдает ошибку и прекращает работу.
Обработка входного потока данных лексером является первым этапом компиляции или интерпретации программы. Она позволяет преобразовать текст программы в последовательность лексем, которые далее используются для построения абстрактного синтаксического дерева или выполнения программы.
Уровень 6: Интерпретатор
Финальным уровнем является интерпретатор. Он берет последовательность байт-кодов и преобразует ее в машинные операции. Вот почему Python.exe и Python для Mac и Linux — все отдельные исполняемые файлы. Некоторым байт-кодам нужна конкретная обработка и проверка ОС. API-интерфейс потоковой обработки, например, должен работать с API-интерфейсом GNU/Linux, который очень отличается от потоков Windows.
Для дальнейшего чтения.
Если вас интересуют интерпретаторы, я рассказал о Pyjion, архитектуре плагина для CPython, которая стала PEP523
Если вы все еще хотите поиграть, я запушил код на GitHub вместе с моими изменениями в токенизаторе ожидания.
Как всегда ждём вопросы, комментарии, замечания.
The IMP language
Before we start writing, let’s discuss the language we’ll be interpreting. IMP is a minimal imperative language with the following constructs:
Assignment statements (all variables are global and can only store integers):
x := 1
Conditional statements:
if x = 1 then y := 2 else y := 3 end
While loops:
while x < 10 do x := x + 1 end
Compound statements (separated by semicolons):
x := 1; y := 2
Okay, so it’s just a toy language, but you could easily extend it to be something more useful like Lua or Python. I wanted to keep things as simple as possible for this tutorial.
Here’s an example of a program which computes a factorial:
n := 5; p := 1; while n > 0 do p := p * n; n := n - 1 end
IMP provides no way to read input, so the initial state must be set with a series of assignment statements at the beginning of the program. There is also no way to print results, so the interpreter will print the values of all variables at the end of the program.
Measuring semantic similarity
We can also measure the semantic similarity between two words based on the distance between these words in the hypernym tree.
Here is an example:
from nltk.corpus import wordnet
# Get the first synset for each word
dog = wordnet.synsets('dog')
cat = wordnet.synsets('cat')
# Get the similarity value
similarity = dog.path_similarity(cat)
print("Semantic similarity between 'dog' and 'cat': ", similarity)
Output:
Semantic similarity: 0.2
In this code, we first get the first synset of each word using . Then we measure the semantic similarity between these synsets using .
In this example, we are only comparing the first sense of each word. If you want a more comprehensive measure of similarity, you may need to compare all senses of the words and possibly aggregate the similarity scores in some way.
Here’s an example of how to do this:
from nltk.corpus import wordnet
# Get all synsets for each word
synsets_dog = wordnet.synsets('dog')
synsets_cat = wordnet.synsets('cat')
# Initialize max similarity
max_similarity = 0
# Compare all pairs of synsets
for synset_dog in synsets_dog:
for synset_cat in synsets_cat:
similarity = synset_dog.path_similarity(synset_cat)
if similarity is not None: # If the words are connected in the hypernym/hyponym taxonomy
max_similarity = max(max_similarity, similarity)
print("Comprehensive semantic similarity between 'dog' and 'cat': ", max_similarity)
Output:
Comprehensive semantic similarity between 'dog' and 'cat': 0.2
In this script, we first get all synsets of each word using . Then we initialize the max similarity to 0.
We compare all pairs of synsets and update the max similarity each time we find a higher similarity. Finally, we print the max similarity.